This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Predictive modeling is a mathematical process that focuses on utilizing historical and current data to predict future outcomes. By identifying patterns within the data, it helps organizations anticipate trends or events, making it a vital component of predictive analytics.
In the sales context, this ensures that sales data remains consistent, accurate, and easily accessible for analysis and reporting. Synapse Data Science: Synapse Data Science empowers data scientists to work directly with secured and governed sales dataprepared by engineering teams, allowing for the efficient development of predictive models.
The motivation behind utilizing multiple camera views comes from the limitation of information when the impact events are captured with only one view. With multiple camera views available from each game, we have developed solutions to identify helmet impacts from each of these views and merge the helmet impact results. astype('str').str.zfill(6)
Pharmaceutical companies sell a variety of different, often novel, drugs on the market, where sometimes unintended but serious adverse events can occur. These events can be reported anywhere, from hospitals or at home, and must be responsibly and efficiently monitored. The training job is built using the SageMaker PyTorch estimator.
Solution overview The real-time personalized recommendations solution is implemented using Amazon Personalize , Amazon Simple Storage Service (Amazon S3) , Amazon Kinesis Data Streams , AWS Lambda , and Amazon API Gateway. For this particular use case, you will be uploading interactions data and items data.
Unfortunately, our data engineering and machine learning ops teams haven’t built a feature vector for us, so all of the relevant data lives in a relational schema in separate tables. Understanding Relationships: GraphReduce doesn’t help with this part, so you’ll need to profile the data, talk to a data guru, or use emerging technology.
Working with AWS, Light & Wonder recently developed an industry-first secure solution, Light & Wonder Connect (LnW Connect), to stream telemetry and machine health data from roughly half a million electronic gaming machines distributed across its casino customer base globally when LnW Connect reaches its full potential.
Regardless of your industry, whether it’s an enterprise insurance company, pharmaceuticals organization, or financial services provider, it could benefit you to gather your own data to predict future events. From a predictive analytics standpoint, you can be surer of its utility. Deep Learning, Machine Learning, and Automation.
Therefore, the ingestion components need to be able to manage authentication, data sourcing in pull mode, data preprocessing, and data storage. Because the data is being fetched hourly, a mechanism is also required to orchestrate and schedule ingestion jobs. Data comes from disparate sources in a number of formats.
You can even use generative AI to supplement your data sets with synthetic data for privacy or accuracy. Most businesses already recognize the need to automate the actual analysis of data, but you can go further. Automating the datapreparation and interpretation phases will take much time and effort out of the equation, too.
Best practices for datapreparation The quality and structure of your training data fundamentally determine the success of fine-tuning. Our experiments revealed several critical insights for preparing effective multimodal datasets: Data structure You should use a single image per example rather than multiple images.
A DataBrew job extracts the data from the TR data warehouse for the users who are eligible to provide recommendations during renewal based on the current subscription plan and recent activity. The real-time integration starts with collecting the live user engagement data and streaming it to Amazon Personalize.
Recent events including Tropical Cyclone Gabrielle have highlighted the susceptibility of the grid to extreme weather and emphasized the need for climate adaptation with resilient infrastructure. Datapreparation SageMaker Ground Truth employs a human workforce made up of Northpower volunteers to annotate a set of 10,000 images.
The excitement is building for the fourteenth edition of AWS re:Invent, and as always, Las Vegas is set to host this spectacular event. This session covers the technical process, from datapreparation to model customization techniques, training strategies, deployment considerations, and post-customization evaluation.
The Github merge event triggers our Jenkins CI pipeline, which in turn starts a SageMaker Pipelines job with test data. Model deployment – After making sure that everything is running as expected, data scientists merge the develop branch into the primary branch. A test endpoint is deployed for testing purposes.
The vendors evaluated for this MarketScape offer various software tools needed to support end-to-end machine learning (ML) model development, including datapreparation, model building and training, model operation, evaluation, deployment, and monitoring. SageMaker launches at re:Invent 2022.
It is designed to address the shortcomings we found with other data for good initiatives, by making sure participants have access to the specialized help they need to create high-quality, lasting AI solutions. We can help with datapreparation and AI development, deployment, and monitoring.
Datapreparation, feature engineering, and feature impact analysis are techniques that are essential to model building. These activities play a crucial role in extracting meaningful insights from raw data and improving model performance, leading to more robust and insightful results.
Common Pitfalls in LLM Development Neglecting DataPreparation: Poorly prepareddata leads to subpar evaluation and iterations, reducing generalizability and stakeholder confidence. Real-world applications often expose gaps that proper datapreparation could have preempted. Evaluation: Tools likeNotion.
MLOps aims to bridge the gap between data science and operational teams so they can reliably and efficiently transition ML models from development to production environments, all while maintaining high model performance and accuracy. AIOps integrates these models into existing IT systems to enhance their functions and performance.
It was a crucial lesson in the power of using tangible, recent events to illustrate potential value. Tool choice may influence design, as each tool has preferred data structures, though corporate strategy and cost considerations may ultimately drive the decision. Future trends Emerging trends are reshaping the data analytics landscape.
The result of these events can be evaluated afterwards so that they make better decisions in the future. With this proactive approach, Kakao Games can launch the right events at the right time. Kakao Games can then create a promotional event not to leave the game. However, this approach is reactive.
Datapreparation using Roboflow, model loading and configuration PaliGemma2 (including optional LoRA/QLoRA), and data loader creation are explained. The article details how these leaks occur, citing examples of real-world incidents, and explores the roles of developers, users, and attackers in these events.
Introduction The Formula 1 Prediction Challenge: 2024 Mexican Grand Prix brought together data scientists to tackle one of the most dynamic aspects of racing — pit stop strategies. With every second on the track critical, the challenge showcased how data can shape decisions that define race outcomes.
By bringing the unmatched AutoML capabilities of DataRobot to the data in Snowflake’s Data Cloud, customers get a seamless and comprehensive enterprise-grade data science platform.” launch event on March 16th. Register here to be part of this virtual event.
First, we have data scientists who are in charge of creating and training machine learning models. They might also help with datapreparation and cleaning. The machine learning engineers are in charge of taking the models developed by data scientists and deploying them into production.
Why is Data Mining Important? Data mining is often used to build predictive models that can be used to forecast future events. Moreover, data mining techniques can also identify potential risks and vulnerabilities in a business. Further, data transformation is also a process ensuring consistent data sets.
Secure, Seamless, and Scalable ML DataPreparation and Experimentation Now DataRobot and Snowflake customers can maximize their return on investment in AI and their cloud data platform. Automated datapreparation and well-defined APIs allow you to quickly frame business problems as training datasets.
Using Amazon Comprehend to redact PII as part of a SageMaker Data Wrangler datapreparation workflow keeps all downstream uses of the data, such as model training or inference, in alignment with your organization’s PII requirements. For more details, refer to Integrating SageMaker Data Wrangler with SageMaker Pipelines.
This includes gathering, exploring, and understanding the business and technical aspects of the data, along with evaluation of any manipulations that may be needed for the model building process. One aspect of this datapreparation is feature engineering.
Amazon SageMaker Pipelines allows orchestrating the end-to-end ML lifecycle from datapreparation and training to model deployment as automated workflows. Prepare the source data for the feature store by adding an event time and record ID for each row of data.
This feature empowers you to rapidly synthesize this information without the hassle of datapreparation or any management overhead. He frequently speaks at AI/ML conferences, events, and meetups around the world. or “What are the common pain points mentioned by customers regarding our onboarding process?”
It does so by covering the ML workflow end-to-end: whether you’re looking for powerful datapreparation and AutoML, managed endpoint deployment, simplified MLOps capabilities, and ready-to-use models powered by AWS AI services and Generative AI, SageMaker Canvas can help you to achieve your goals.
And, for the tenth anniversary of ODSC East , we are pulling out all of the stops with new tracks, new events, and even a new location. Youll gain immediate, practical skills in Python, datapreparation, machine learning modeling, and retrieval-augmented generation (RAG), all leading up to AI Agents. Find outbelow!
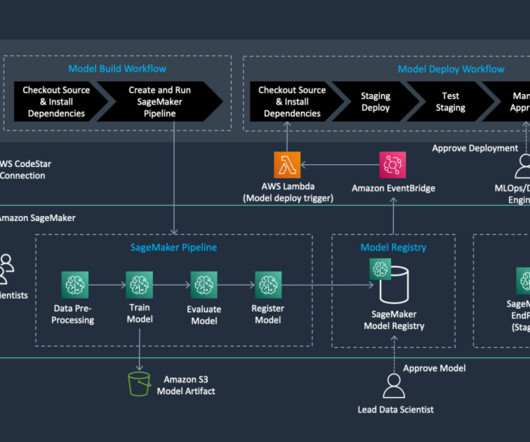
We create an automated model build pipeline that includes steps for datapreparation, model training, model evaluation, and registration of the trained model in the SageMaker Model Registry. You can create event-driven workflows triggered by specific events, like when code is pushed to a repository or a pull request is created.
25 Enterprise LLM Summit: Building GenAI with Your Data drew over a thousand engaged attendees across three and a half hours and nine sessions. The eight speakers at the event—the second in our Enterprise LLM series—united around one theme: AI data development drives enterprise AI success. Snorkel AI’s Jan.
This instance will be used for various tasks such as video processing and datapreparation. Rob Koch is a tech enthusiast who thrives on steering projects from their initial spark to successful fruition, Rob Koch is Principal at Slalom Build in Seattle, an AWS Data Hero, and Co-chair of the CNCF Deaf and Hard of Hearing Working Group.
A model builder: Data scientists create models that simulate real-world processes. These models can predict future events, classify data into categories, or uncover relationships between variables, enabling better decision-making.
The Women in Big Data (WiBD) Spring Hackathon 2024, organized by WiDS and led by WiBD’s Global Hackathon Director Rupa Gangatirkar , sponsored by Gilead Sciences, offered an exciting opportunity to sharpen data science skills while addressing critical social impact challenges.
The solution focuses on the fundamental principles of developing an AI/ML application workflow of datapreparation, model training, model evaluation, and model monitoring. Solution overview Predicting animal breeds from an image needs custom ML models. Amazon DynamoDB is a fast and flexible nonrelational database service for any scale.
Here’s how it differentiates itself from traditional IT operations methods: Data-driven It thrives on collecting and processing vast amounts of data from diverse sources – applications, networks, infrastructure, and user behavior. By analyzing this data , it identifies patterns and anomalies that might escape human observation.
DataRobot now delivers both visual and code-centric datapreparation and data pipelines, along with automated machine learning that is composable, and can be driven by hosted notebooks or a graphical user experience. Virtual Event. Learn More About DataRobot’s Vision and Roadmap for AI Cloud. September 23. Register Now.
It has versatile data connectivity, real-time data exploration, and plenty of community support that helps users, new to veterans, unleash the program’s full potential. Most of these features also come with AI assistance to help users find the best way to visualize their data. Interested in attending an ODSC event?
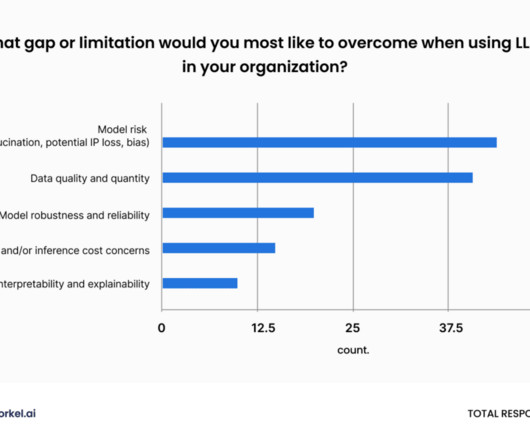
As data science teams reorient around the enduring value of small, deployable models, they’re also learning how LLMs can accelerate data labeling. According to our poll participants, datapreparation still occupies more data scientists’ hours than anything else.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content