This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The fields of Data Science, Artificial Intelligence (AI), and Large Language Models (LLMs) continue to evolve at an unprecedented pace. To keep up with these rapid developments, it’s crucial to stay informed through reliable and insightful sources. Link to blog -> What is LangChain?
Businesses need to understand the trends in datapreparation to adapt and succeed. If you input poor-quality data into an AI system, the results will be poor. This principle highlights the need for careful datapreparation, ensuring that the input data is accurate, consistent, and relevant.
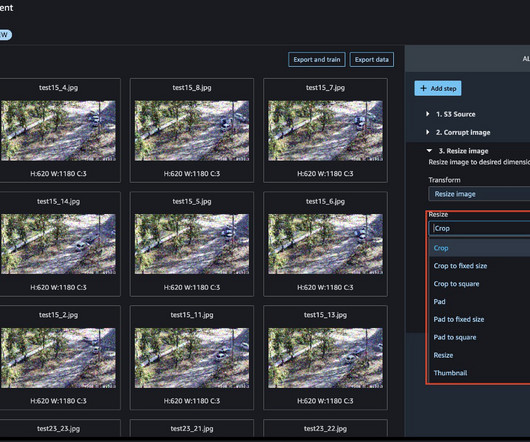
Datapreparation is a crucial step in any machine learning (ML) workflow, yet it often involves tedious and time-consuming tasks. Amazon SageMaker Canvas now supports comprehensive datapreparation capabilities powered by Amazon SageMaker Data Wrangler. Within the data flow, add an Amazon S3 destination node.
Amazon SageMaker Data Wrangler provides a visual interface to streamline and accelerate datapreparation for machine learning (ML), which is often the most time-consuming and tedious task in ML projects. Charles holds an MS in Supply Chain Management and a PhD in Data Science. Huong Nguyen is a Sr. Product Manager at AWS.
Think your customers will pay more for data visualizations in your application? Five years ago they may have. But today, dashboards and visualizations have become table stakes. Discover which features will differentiate your application and maximize the ROI of your embedded analytics. Brought to you by Logi Analytics.
This approach is ideal for use cases requiring accuracy and up-to-date information, like providing technical product documentation or customer support. For instance, prompts like “Provide a detailed but informal explanation” can shape the output significantly without requiring the model itself to be fine-tuned.
You need to provide the user with information within a short time frame without compromising the user experience. He cited delivery time prediction as an example, where each user’s data is unique and depends on numerous factors, precluding pre-caching. Data management is another critical area.
Datapreparation is a critical step in any data-driven project, and having the right tools can greatly enhance operational efficiency. Amazon SageMaker Data Wrangler reduces the time it takes to aggregate and prepare tabular and image data for machine learning (ML) from weeks to minutes.
Augmented analytics is revolutionizing how organizations interact with their data. By harnessing the power of machine learning (ML) and natural language processing (NLP), businesses can streamline their data analysis processes and make more informed decisions. What is augmented analytics?
Why do some embedded analytics projects succeed while others fail? We surveyed 500+ application teams embedding analytics to find out which analytics features actually move the needle. Read the 6th annual State of Embedded Analytics Report to discover new best practices. Brought to you by Logi Analytics.
By narrowing down the search space to the most relevant documents or chunks, metadata filtering reduces noise and irrelevant information, enabling the LLM to focus on the most relevant content. By combining the capabilities of LLM function calling and Pydantic data models, you can dynamically extract metadata from user queries.
The updated version provides more practical information on these techniques, which we believe have become more accessible since the book was published and have found broader applications beyond research. A major addition to the book is a brand-new chapter titled Indexes, Retrievers, and DataPreparation. What’s New?
This mostly occurs when prompted with information not present in their training set, despite being trained on extensive data. This discrepancy between the general knowledge embedded in the LLM’s weights and newer information can be bridged using RAG. Use Google Colab for code execution.
These include safeguarding sensitive information, providing accuracy and relevance of AI-generated content, mitigating biases, maintaining transparency, and adhering to data protection regulations. Have an S3 bucket to store your dataprepared for batch inference. Focus on the main issue, steps taken, and resolution.
As data science evolves and grows, the demand for skilled data scientists is also rising. A data scientist’s role is to extract insights and knowledge from data and to use this information to inform decisions and drive business growth.
Presented by SQream The challenges of AI compound as it hurtles forward: demands of datapreparation, large data sets and data quality, the time sink of long-running queries, batch processes and more. In this VB Spotlight, William Benton, principal product architect at NVIDIA, and others explain how …
Generative AI (GenAI), specifically as it pertains to the public availability of large language models (LLMs), is a relatively new business tool, so it’s understandable that some might be skeptical of a technology that can generate professional documents or organize data instantly across multiple repositories.
Synthetic data is revolutionizing the way we approach data privacy and analysis across various industries. By creating artificial datasets that mimic real-world statistics without compromising personal information, organizations can harness the power of data while adhering to stringent privacy regulations.
It enhances data classification by increasing the complexity of input data, helping organizations make informed decisions based on probabilities. By analyzing data from IoT devices, organizations can perform maintenance tasks proactively, reducing downtime and operational costs.
This article delves into the essential components of data mining, highlighting its processes, techniques, tools, and applications. What is data mining? Data mining refers to the systematic process of analyzing large datasets to uncover hidden patterns and relationships that inform and address business challenges.
We will start by setting up libraries and datapreparation. Setup and DataPreparation For implementing a similar word search, we will use the gensim library for loading pre-trained word embeddings vector. These word vectors are trained from Twitter data making them semantically rich in information.
Some projects may necessitate a comprehensive LLMOps approach, spanning tasks from datapreparation to pipeline production. Exploratory Data Analysis (EDA) Data collection: The first step in LLMOps is to collect the data that will be used to train the LLM. What are the benefits of LLMOps?
From data discovery and cleaning to report creation and sharing, we will delve into the key steps that can be taken to turn data into decisions. A data analyst is a professional who uses data to inform business decisions. Check out this course and learn Power BI today!
Synapse Data Science: Synapse Data Science empowers data scientists to work directly with secured and governed sales dataprepared by engineering teams, allowing for the efficient development of predictive models.
Their solutions span a wide range of applications, including data management, advanced analytics, and artificial intelligence. SAS’s offerings cater to various industries, enabling businesses to analyze complex data, forecast trends, and drive informed decision-making.
We discuss the important components of fine-tuning, including use case definition, datapreparation, model customization, and performance evaluation. This post dives deep into key aspects such as hyperparameter optimization, data cleaning techniques, and the effectiveness of fine-tuning compared to base models.
Importing data from the SageMaker Data Wrangler flow allows you to interact with a sample of the data before scaling the datapreparation flow to the full dataset. This improves time and performance because you don’t need to work with the entirety of the data during preparation.
Imagine a world where computers can’t interpret the visual information around them without a little human assistance. That’s where data annotation comes into play. In simple terms, data annotation is the process of labeling various types of content, including text, audio, images, and videos.
According to Gartner , unstructured data now represents 80–90% of all new enterprise data, but just 18% of organizations are taking advantage of this data. Today, we are happy to announce that with Amazon SageMaker Data Wrangler , you can perform image datapreparation for machine learning (ML) using little to no code.
Additionally, these tools provide a comprehensive solution for faster workflows, enabling the following: Faster datapreparation – SageMaker Canvas has over 300 built-in transformations and the ability to use natural language that can accelerate datapreparation and making data ready for model building.
In the world of data science and machine learning, feature transformation plays a crucial role in achieving accurate and reliable results. By manipulating the input features of a dataset, we can enhance their quality, extract meaningful information, and improve the performance of predictive models.
We recommend referring to the Submit a model distillation job in Amazon Bedrock in the official AWS documentation for the most up-to-date and comprehensive information. Preparing your data Effective datapreparation is crucial for successful distillation of agent function calling capabilities.
Summary: Retrieval-Augmented Generation (RAG) combines information retrieval and generative models to improve AI output. By integrating efficient information retrieval mechanisms with pre-trained transformers, RAG systems can produce more accurate and contextually relevant responses.
Interviewers aren’t just looking for textbook definitions; they want to understand your thought process, your design principles, your familiarity with tools, and your ability to communicate complex information effectively through visuals. Q1: What is data visualization, and why is it important in Data Analysis?
It is also possible to define and use dynamic prompt variables, as well as apply automatic detection of HAP (hateful, abusive or profane content) and PII (personally identifiable information) on the input and the output texts. For more information see the prompt lab documentation. For more information see Prompt Lab documentation.
Multimodal fine-tuning represents a powerful approach for customizing foundation models (FMs) to excel at specific tasks that involve both visual and textual information. multimodal fine-tuning excels in scenarios where the model needs to understand visual information and generate appropriate textual responses.
Natural Language Processing (NLP) for Data Interaction Generative AI models like GPT-4 utilize transformer architectures to understand and generate human-like text based on a given context. Impact on Data Analytics: Risk Management : By simulating various outcomes, GenAI helps organizations prepare for potential risks and uncertainties.
We exist in a diversified era of data tools up and down the stack – from storage to algorithm testing to stunning business insights. appeared first on DATAVERSITY.
Overview of multimodal embeddings and multimodal RAG architectures Multimodal embeddings are mathematical representations that integrate information not only from text but from multiple data modalities—such as product images, graphs, and charts—into a unified vector space.
Next Generation DataStage on Cloud Pak for Data Ensuring high-quality data A crucial aspect of downstream consumption is data quality. Studies have shown that 80% of time is spent on datapreparation and cleansing, leaving only 20% of time for data analytics. This leaves more time for data analysis.
Given the enormous volume of information which can reach petabytes efficient data handling is crucial. Tools used for datapreparation differ based on the data’s volume and complexity: Pandas: A Python library suitable for data processing in smaller projects or prototyping the big ones.
For readers who work in ML/AI, it’s well understood that machine learning models prefer feature vectors of numerical information. However, the majority of enterprise data remains unleveraged from an analytics and machine learning perspective, and much of the most valuable information remains in relational database schemas such as OLAP.
The process begins with datapreparation, followed by model training and tuning, and then model deployment and management. Datapreparation is essential for model training and is also the first phase in the MLOps lifecycle. Next, you can use governance to share information about the environmental impact of your model.
For this walkthrough, we use a straightforward generative AI lifecycle involving datapreparation, fine-tuning, and a deployment of Meta’s Llama-3-8B LLM. Datapreparation In this phase, prepare the training and test data for the LLM. We use the SageMaker Core SDK to execute all the steps.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content