This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
By using this method, you may speed up the process of defining data structures, schema, and transformations while scaling to any size of data. Through data crawling, cataloguing, and indexing, they also enable you to know what data is in the lake.
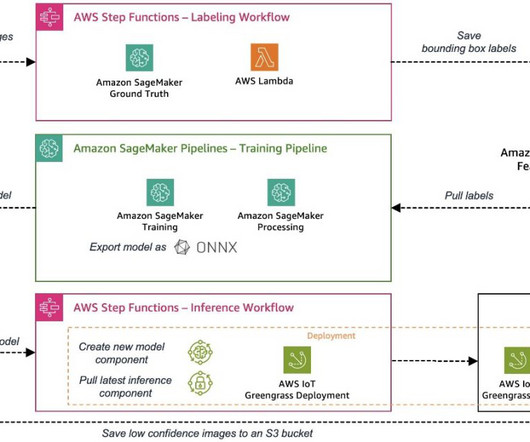
AWS IoT Greengrass is an Internet of Things (IoT) open-source edge runtime and cloud service that helps you build, deploy, and manage edge device software. You can also use EC2 instances to validate the different components in a QA process before deploying to an actual edge production device.
Using Amazon Comprehend to redact PII as part of a SageMaker Data Wrangler datapreparation workflow keeps all downstream uses of the data, such as model training or inference, in alignment with your organization’s PII requirements. For more details, refer to Integrating SageMaker Data Wrangler with SageMaker Pipelines.
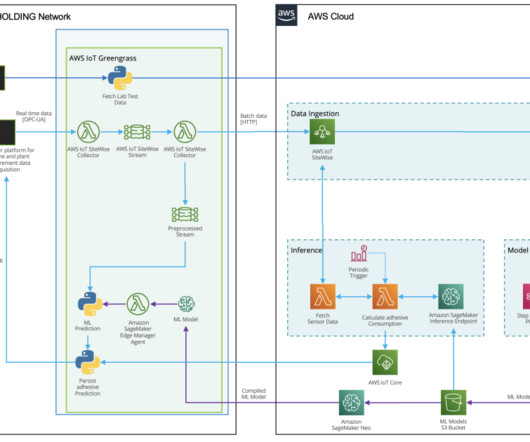
Data ingestion HAYAT HOLDING has a state-of-the art infrastructure for acquiring, recording, analyzing, and processing measurement data. Model training and optimization with SageMaker automatic model tuning Prior to the model training, a set of datapreparation activities are performed.
Today, data integration is moving closer to the edges – to the business people and to where the data actually exists – the Internet of Things (IoT) and the Cloud. 5] Gartner, Market Guide for DataPreparation , Published: 14 December 2017, Analyst(s): Ehtisham Zaidi | Rita L. DataRobot Data Prep.
Additions are required in historical datapreparation, model evaluation, and monitoring. In classic ML, the historical data is most often created by feeding the ground truth via ETL pipelines. However, they need to be prepared and follow the format of the existing historical unlabeled data.
It now allows users to clean, transform, and integrate data from various sources, streamlining the Data Analysis process. This eliminates the need to rely on separate tools for datapreparation, saving time and resources. The Internet of Things (IoT) generates vast amounts of data from sensors and connected devices.
This approach to datapreparation creates the foundation for fine-tuning a model that can play chess at a high level. Fine-tune a model With our refined dataset prepared from successful games and legal moves, we now proceed to fine-tune a model using Amazon SageMaker JumpStart.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













Let's personalize your content