This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
We’re excited to announce the release of SageMaker Core , a new Python SDK from Amazon SageMaker designed to offer an object-oriented approach for managing the machine learning (ML) lifecycle. With SageMaker Core, managing ML workloads on SageMaker becomes simpler and more efficient. or greater is installed in the environment.
This year, generative AI and machine learning (ML) will again be in focus, with exciting keynote announcements and a variety of sessions showcasing insights from AWS experts, customer stories, and hands-on experiences with AWS services. Visit the session catalog to learn about all our generative AI and ML sessions.
With the most recent developments in machine learning , this process has become more accurate, flexible, and fast: algorithms analyze vast amounts of data, glean insights from the data, and find optimal solutions. Image credit: economicsdiscussion.net The Transformation with ML The dynamic pricing landscape is very different now.
With that, the need for data scientists and machine learning (ML) engineers has grown significantly. Data scientists and ML engineers require capable tooling and sufficient compute for their work. Data scientists and ML engineers require capable tooling and sufficient compute for their work.
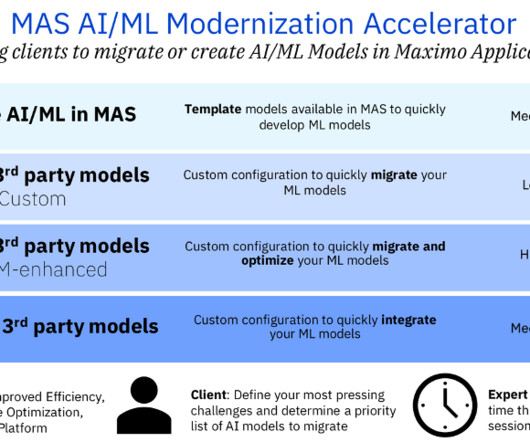
Many businesses are in different stages of their MAS AI/ML modernization journey. In this blog, we delve into 4 different “on-ramps” we created in a MAS Accelerator to offer a straightforward path to harnessing the power of AI in MAS, wherever you may be on your MAS AI/ML modernization journey.
Amazon SageMaker is a fully managed machine learning (ML) service. With SageMaker, data scientists and developers can quickly and easily build and train ML models, and then directly deploy them into a production-ready hosted environment. We add this data to Snowflake as a new table.
In these scenarios, as you start to embrace generative AI, large language models (LLMs) and machine learning (ML) technologies as a core part of your business, you may be looking for options to take advantage of AWS AI and ML capabilities outside of AWS in a multicloud environment.
Datapreparation is a critical step in any data-driven project, and having the right tools can greatly enhance operational efficiency. Amazon SageMaker Data Wrangler reduces the time it takes to aggregate and prepare tabular and image data for machine learning (ML) from weeks to minutes.
Amazon Redshift is the most popular cloud data warehouse that is used by tens of thousands of customers to analyze exabytes of data every day. SageMaker Studio is the first fully integrated development environment (IDE) for ML. as the image and Glue Python [PySpark and Ray] as the kernel, then choose Select.
This post presents and compares options and recommended practices on how to manage Python packages and virtual environments in Amazon SageMaker Studio notebooks. Amazon SageMaker Studio is a web-based, integrated development environment (IDE) for machine learning (ML) that lets you build, train, debug, deploy, and monitor your ML models.
jpg", "prompt": "Which part of Virginia is this letter sent from", "completion": "Richmond"} SageMaker JumpStart SageMaker JumpStart is a powerful feature within the SageMaker machine learning (ML) environment that provides ML practitioners a comprehensive hub of publicly available and proprietary foundation models (FMs).
Let’s get started with the best machine learning (ML) developer tools: TensorFlow TensorFlow, developed by the Google Brain team, is one of the most utilized machine learning tools in the industry. Scikit Learn Scikit Learn is a comprehensive machine learning tool designed for data mining and large-scale unstructured data analysis.
The ability to quickly build and deploy machine learning (ML) models is becoming increasingly important in today’s data-driven world. However, building ML models requires significant time, effort, and specialized expertise. This is where the AWS suite of low-code and no-code ML services becomes an essential tool.
As machine learning (ML) becomes increasingly prevalent in a wide range of industries, organizations are finding the need to train and serve large numbers of ML models to meet the diverse needs of their customers. The consumption values are randomly generated between 0–1,000 with sinusoidal seasonality.
PyTorch PyTorch is another open-source software library for numerical computation using data flow graphs. It is similar to TensorFlow, but it is designed to be more Pythonic. Scikit-learn Scikit-learn is an open-source machine learning library for Python. TensorFlow was also used by Netflix to improve its recommendation engine.
[link] Ahmad Khan, head of artificial intelligence and machine learning strategy at Snowflake gave a presentation entitled “Scalable SQL + PythonML Pipelines in the Cloud” about his company’s Snowpark service at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. Welcome everybody.
[link] Ahmad Khan, head of artificial intelligence and machine learning strategy at Snowflake gave a presentation entitled “Scalable SQL + PythonML Pipelines in the Cloud” about his company’s Snowpark service at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. Welcome everybody.
Second, because data, code, and other development artifacts like machine learning (ML) models are stored within different services, it can be cumbersome for users to understand how they interact with each other and make changes. With the SQL editor, you can query data lakes, databases, data warehouses, and federated data sources.
In this comprehensive guide, we’ll explore the key concepts, challenges, and best practices for ML model packaging, including the different types of packaging formats, techniques, and frameworks. Best practices for ml model packaging Here is how you can package a model efficiently.
The solution harnesses the capabilities of generative AI, specifically Large Language Models (LLMs), to address the challenges posed by diverse sensor data and automatically generate Python functions based on various data formats. The solution only invokes the LLM for new device data file type (code has not yet been generated).
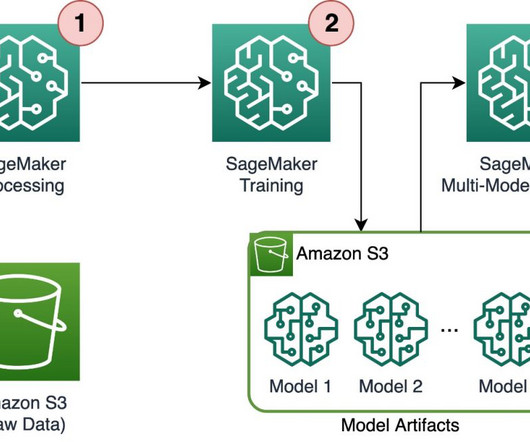
Solution overview Amazon SageMaker is a fully managed service that helps developers and data scientists build, train, and deploy machine learning (ML) models. Datapreparation SageMaker Ground Truth employs a human workforce made up of Northpower volunteers to annotate a set of 10,000 images.
Customers increasingly want to use deep learning approaches such as large language models (LLMs) to automate the extraction of data and insights. For many industries, data that is useful for machine learning (ML) may contain personally identifiable information (PII).
Machine learning (ML) is becoming increasingly complex as customers try to solve more and more challenging problems. This complexity often leads to the need for distributed ML, where multiple machines are used to train a single model. SageMaker is a fully managed service for building, training, and deploying ML models.
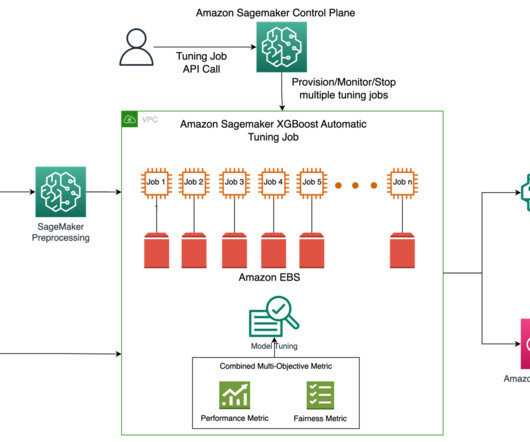
Model tuning is the experimental process of finding the optimal parameters and configurations for a machine learning (ML) model that result in the best possible desired outcome with a validation dataset. Single objective optimization with a performance metric is the most common approach for tuning ML models.
Image generated by Gemini Spark is an open-source distributed computing framework for high-speed data processing. As a Python user, I find the {pySpark} library super handy for leveraging Spark’s capacity to speed up data processing in machine learning projects. within each project folder.
In other words, companies need to move from a model-centric approach to a data-centric approach.” – Andrew Ng A data-centric AI approach involves building AI systems with quality data involving datapreparation and feature engineering. Custom transforms can be written as separate steps within Data Wrangler.
The IDE connects to a Python runtime environment inside the secure scope of a project, which enables to run code in that context with access to assets available in your project. Data Science and MLOps: Tools, pipelines and runtimes that support building ML models automatically, and automate the full lifecycle from development to deployment.
aws sagemaker create-cluster --cli-input-json file://cluster-config.json --region $AWS_REGION You should be able to see your cluster by navigating to SageMaker Hyperpod in the AWS Management Console and see a cluster named ml-cluster listed. Step 1: Environment setup You first need to install the required Python packages for fine tuning.
Amazon SageMaker Studio provides a comprehensive suite of fully managed integrated development environments (IDEs) for machine learning (ML), including JupyterLab , Code Editor (based on Code-OSS), and RStudio. In this post, we provide step-by-step guidance on how you can build and use custom container images in SageMaker Studio.
Being one of the largest AWS customers, Twilio engages with data and artificial intelligence and machine learning (AI/ML) services to run their daily workloads. ML models don’t operate in isolation. This necessitates considering the entire ML lifecycle during design and development.
Summary: This guide explores Artificial Intelligence Using Python, from essential libraries like NumPy and Pandas to advanced techniques in machine learning and deep learning. Python’s simplicity, versatility, and extensive library support make it the go-to language for AI development.
Alignment to other tools in the organization’s tech stack Consider how well the MLOps tool integrates with your existing tools and workflows, such as data sources, data engineering platforms, code repositories, CI/CD pipelines, monitoring systems, etc. and Pandas or Apache Spark DataFrames.
For readers who work in ML/AI, it’s well understood that machine learning models prefer feature vectors of numerical information. Tapping into these schemas and pulling out machine learning-ready features can be nontrivial as one needs to know where the data entity of interest lives (e.g.,
And eCommerce companies have a ton of use cases where ML can help. The problem is, with more ML models and systems in production, you need to set up more infrastructure to reliably manage everything. And because of that, many companies decide to centralize this effort in an internal ML platform. But how to build it?
Datapreparation is important at multiple stages in Retrieval Augmented Generation ( RAG ) models. Specifically, we clean the data and create RAG artifacts to answer the questions about the content of the dataset. Choose Create on the right side of page, then give a data flow name and select Create. Choose your domain.
However, managing machine learning projects can be challenging, especially as the size and complexity of the data and models increase. Without proper tracking, optimization, and collaboration tools, ML practitioners can quickly become overwhelmed and lose track of their progress. This is where Comet comes in.
Machine learning (ML) models do not operate in isolation. To deliver value, they must integrate into existing production systems and infrastructure, which necessitates considering the entire ML lifecycle during design and development. GitHub serves as a centralized location to store, version, and manage your ML code base.
Amazon SageMaker Data Wrangler is a single visual interface that reduces the time required to preparedata and perform feature engineering from weeks to minutes with the ability to select and clean data, create features, and automate datapreparation in machine learning (ML) workflows without writing any code.
Fine tuning embedding models using SageMaker SageMaker is a fully managed machine learning service that simplifies the entire machine learning workflow, from datapreparation and model training to deployment and monitoring. Python script that serves as the entry point. writefile opt/ml/model/inference.py
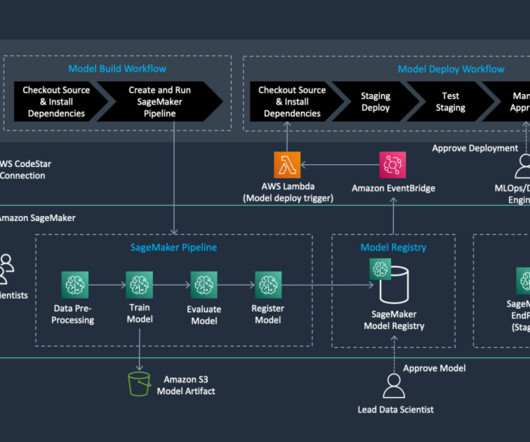
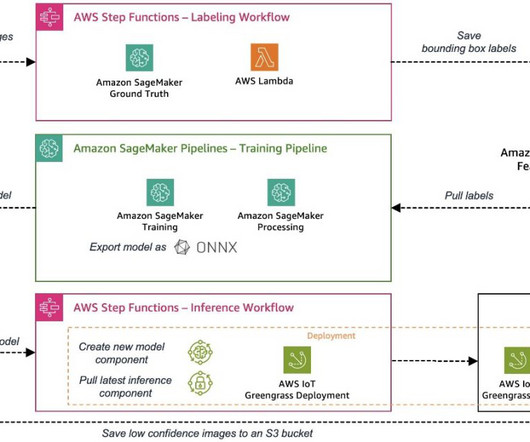
Solution overview In Part 1 of this series, we laid out an architecture for our end-to-end MLOps pipeline that automates the entire machine learning (ML) process, from data labeling to model training and deployment at the edge. In Part 2 , we showed how to automate the labeling and model training parts of the pipeline.
Statistical methods and machine learning (ML) methods are actively developed and adopted to maximize the LTV. In this post, we share how Kakao Games and the Amazon Machine Learning Solutions Lab teamed up to build a scalable and reliable LTV prediction solution by using AWS data and ML services such as AWS Glue and Amazon SageMaker.
Amazon SageMaker Studio provides a fully managed solution for data scientists to interactively build, train, and deploy machine learning (ML) models. Amazon SageMaker notebook jobs allow data scientists to run their notebooks on demand or on a schedule with a few clicks in SageMaker Studio.
Machine learning practitioners are often working with data at the beginning and during the full stack of things, so they see a lot of workflow/pipeline development, data wrangling, and datapreparation. What percentage of machine learning models developed in your organization get deployed to a production environment?
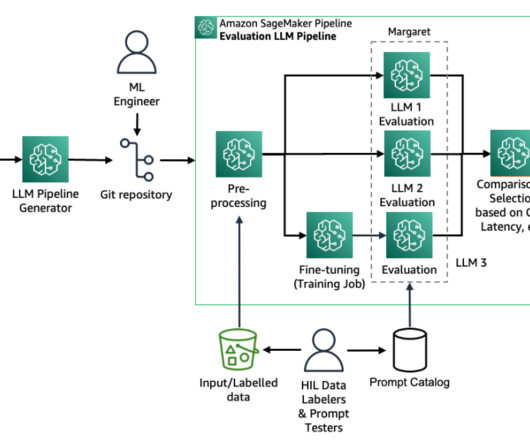
Fine-tuning an LLM can be a complex workflow for data scientists and machine learning (ML) engineers to operationalize. Solution overview Running hundreds of experiments, comparing the results, and keeping a track of the ML lifecycle can become very complex. Each iteration can be considered a run within an experiment.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.










































Let's personalize your content