This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
NLP with Transformers introduces readers to transformer architecture for naturallanguageprocessing, offering practical guidance on using Hugging Face for tasks like text classification.
Summary: This guide explores Artificial Intelligence Using Python, from essential libraries like NumPy and Pandas to advanced techniques in machine learning and deep learning. Python’s simplicity, versatility, and extensive library support make it the go-to language for AI development.
TensorFlow First on the AI tool list, we have TensorFlow which is an open-source software library for numerical computation using data flow graphs. It is used for machine learning, naturallanguageprocessing, and computer vision tasks. It is similar to TensorFlow, but it is designed to be more Pythonic.
We cover two approaches: using the Amazon SageMaker Studio UI for a no-code solution, and using the SageMaker Python SDK. FMs through SageMaker JumpStart in the SageMaker Studio UI and the SageMaker Python SDK. Fine-tune using the SageMaker Python SDK You can also fine-tune Meta Llama 3.2 Vision models.
As AI adoption continues to accelerate, developing efficient mechanisms for digesting and learning from unstructured data becomes even more critical in the future. This could involve better preprocessing tools, semi-supervised learning techniques, and advances in naturallanguageprocessing. And select Python (PySpark).
For instance, today’s machine learning tools are pushing the boundaries of naturallanguageprocessing, allowing AI to comprehend complex patterns and languages. PyTorch PyTorch, a Python-based machine learning library, stands out among its peers in the machine learning tools ecosystem.
Solution overview This solution uses Amazon Comprehend and SageMaker Data Wrangler to automatically redact PII data from a sample dataset. Amazon Comprehend is a naturallanguageprocessing (NLP) service that uses ML to uncover insights and relationships in unstructured data, with no managing infrastructure or ML experience required.
In other words, companies need to move from a model-centric approach to a data-centric approach.” – Andrew Ng A data-centric AI approach involves building AI systems with quality data involving datapreparation and feature engineering. Custom transforms can be written as separate steps within Data Wrangler.
Word2vec is useful for various naturallanguageprocessing (NLP) tasks, such as sentiment analysis, named entity recognition, and machine translation. If you are prompted to choose a Kernel, choose the Python 3 (Data Science 3.0) Import the required Python library and set the roles and the S3 buckets.
Fine tuning embedding models using SageMaker SageMaker is a fully managed machine learning service that simplifies the entire machine learning workflow, from datapreparation and model training to deployment and monitoring. Python script that serves as the entry point. client('s3') # Get the region name session = boto3.Session()
With the addition of forecasting, you can now access end-to-end ML capabilities for a broad set of model types—including regression, multi-class classification, computer vision (CV), naturallanguageprocessing (NLP), and generative artificial intelligence (AI)—within the unified user-friendly platform of SageMaker Canvas.
Large language models (LLMs) have achieved remarkable success in various naturallanguageprocessing (NLP) tasks, but they may not always generalize well to specific domains or tasks. This is where MLflow can help streamline the ML lifecycle, from datapreparation to model deployment.
It simplifies the development and maintenance of ML models by providing a centralized platform to orchestrate tasks such as datapreparation, model training, tuning and validation. You can run the following command from your notebook or terminal to install or upgrade the SageMaker Python SDK version to 2.162.0
By implementing a modern naturallanguageprocessing (NLP) model, the response process has been shaped much more efficiently, and waiting time for clients has been reduced tremendously. In the following sections, we break down the datapreparation, model experimentation, and model deployment steps in more detail.
They consist of interconnected nodes that learn complex patterns in data. Different types of neural networks, such as feedforward, convolutional, and recurrent networks, are designed for specific tasks like image recognition, NaturalLanguageProcessing, and sequence modelling.
Given this mission, Talent.com and AWS joined forces to create a job recommendation engine using state-of-the-art naturallanguageprocessing (NLP) and deep learning model training techniques with Amazon SageMaker to provide an unrivaled experience for job seekers. The client registers smddp as a backend for PyTorch.
While both these tools are powerful on their own, their combined strength offers a comprehensive solution for data analytics. In this blog post, we will show you how to leverage KNIME’s Tableau Integration Extension and discuss the benefits of using KNIME for datapreparation before visualization in Tableau.
A good understanding of Python and machine learning concepts is recommended to fully leverage TensorFlow's capabilities. Libraries and Extensions: Includes torchvision for image processing, touchaudio for audio processing, and torchtext for NLP. It is well-suited for both research and production environments.
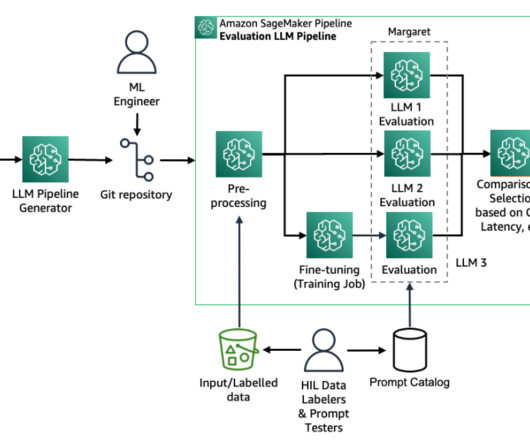
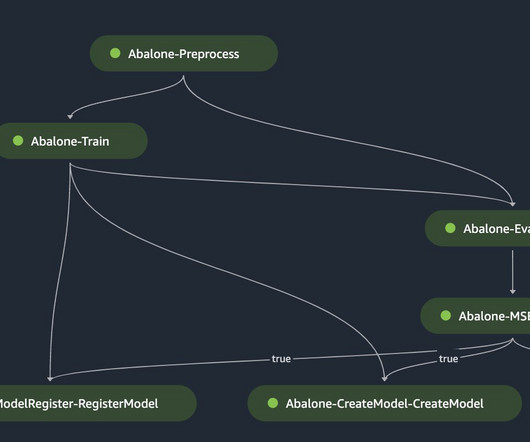
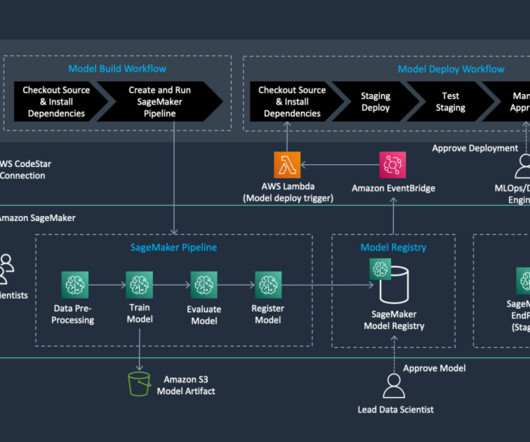
We create an automated model build pipeline that includes steps for datapreparation, model training, model evaluation, and registration of the trained model in the SageMaker Model Registry. Romina’s areas of interest are naturallanguageprocessing, large language models, and MLOps.
LLMs are one of the most exciting advancements in naturallanguageprocessing (NLP). We will explore how to better understand the data that these models are trained on, and how to evaluate and optimize them for real-world use. LLMs rely on vast amounts of text data to learn patterns and generate coherent text.
Datapreparation LLM developers train their models on large datasets of naturally occurring text. Popular examples of such data sources include Common Crawl and The Pile. Naturally occurring text may contain biases, inaccuracies, grammatical errors, and syntax variations.
With the introduction of EMR Serverless support for Apache Livy endpoints , SageMaker Studio users can now seamlessly integrate their Jupyter notebooks running sparkmagic kernels with the powerful dataprocessing capabilities of EMR Serverless. In this post, we build a Docker image that includes the Python 3.11
Haystack FileConverters and PreProcessor allow you to clean and prepare your raw files to be in a shape and format that your naturallanguageprocessing (NLP) pipeline and language model of choice can deal with. An indexing pipeline may also include a step to create embeddings for your documents.
PyTorch For tasks like computer vision and naturallanguageprocessing, Using the Torch library as its foundation, PyTorch is a free and open-source machine learning framework that comes in handy. Anomalib Anomalib is a Python library that helps users to detect anomalies in time-series data.
This allows users to accomplish different NaturalLanguageProcessing (NLP) functional tasks and take advantage of IBM vetted pre-trained open-source foundation models. Encoder-decoder and decoder-only large language models are available in the Prompt Lab today. To bridge the tuning gap, watsonx.ai
The expeditious and efficient construction, deployment, and scalability of machine learning models assume utmost importance in unearthing the untapped potential of data-driven decision-making. This extensive repertoire includes classification, regression, clustering, naturallanguageprocessing, and anomaly detection.
It can be difficult to find insights from this data, particularly if efforts are needed to classify, tag, or label it. Amazon Comprehend is a natural-languageprocessing (NLP) service that uses machine learning to uncover valuable insights and connections in text. CSV) or semi-structured format (ex.
Jupyter notebooks can differentiate between SQL and Python code using the %%sm_sql magic command, which must be placed at the top of any cell that contains SQL code. This command signals to JupyterLab that the following instructions are SQL commands rather than Python code. In his free time, he enjoys playing chess and traveling.
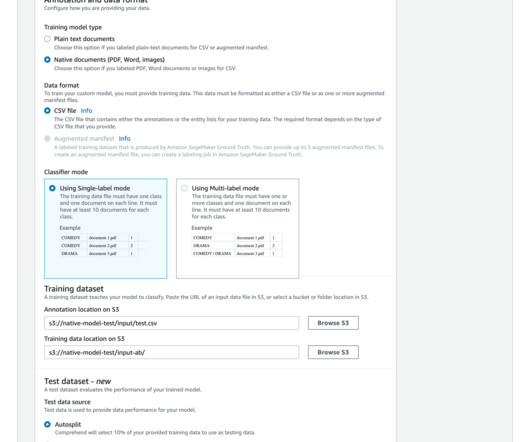
At AWS re:Invent 2022, Amazon Comprehend , a naturallanguageprocessing (NLP) service that uses machine learning (ML) to discover insights from text, launched support for native document types. This new feature gave you the ability to classify documents in native formats (PDF, TIFF, JPG, PNG, DOCX) using Amazon Comprehend.
Amazon Kendra is a highly accurate and intelligent search service that enables users to search unstructured and structured data using naturallanguageprocessing (NLP) and advanced search algorithms. For more information, refer to Granting Data Catalog permissions using the named resource method.
Key programming languages include Python and R, while mathematical concepts like linear algebra and calculus are crucial for model optimisation. Understanding Machine Learning algorithms and effective data handling are also critical for success in the field. The global Machine Learning market was valued at USD 35.80
For example, if your team is proficient in Python and R, you may want an MLOps tool that supports open data formats like Parquet, JSON, CSV, etc., For example, if your team works on recommender systems or naturallanguageprocessing applications, you may want an MLOps tool that has built-in algorithms or templates for these use cases.
AI encompasses various subfields, including Machine Learning (ML), NaturalLanguageProcessing (NLP), robotics, and computer vision. Together, Data Science and AI enable organisations to analyse vast amounts of data efficiently and make informed decisions based on predictive analytics.
Because the machine learning lifecycle has many complex components that reach across multiple teams, it requires close-knit collaboration to ensure that hand-offs occur efficiently, from datapreparation and model training to model deployment and monitoring.
DataPreparation: Cleaning, transforming, and preparingdata for analysis and modelling. Algorithm Development: Crafting algorithms to solve complex business problems and optimise processes. Essential Technical Skills Technical proficiency is at the heart of an Azure Data Scientist’s role.
Leaving aside the more established skills here’s a visual look at the newer skills NaturalLanguageProcessing (NLP), Tokenization, Transformers, Representation Learning and Knowledge Graphs NLP (NaturalLanguageProcessing) The NLP engineer can be considered a precursor to the Promt Engineer.
Augmented Analytics Augmented analytics is revolutionising the way businesses analyse data by integrating Artificial Intelligence (AI) and Machine Learning (ML) into analytics processes. This foundational knowledge is essential for any Data Science project. What Skills Are Most Important for Future Data Scientists?
For example, Modularizing a naturallanguageprocessing (NLP) model for sentiment analysis can include separating the word embedding layer and the RNN layer into separate modules, which can be packaged and reused in other NLP models to manage code and reduce duplication and computational resources required to run the model.
LangChain is an open source Python library designed to build applications with LLMs. Datapreparation In this post, we use several years of Amazon’s Letters to Shareholders as a text corpus to perform QnA on. For more detailed steps to prepare the data, refer to the GitHub repo.
In terms of resulting speedups, the approximate order is programming hardware, then programming against PBA APIs, then programming in an unmanaged language such as C++, then a managed language such as Python. Analysis of publications containing accelerated compute workloads by Zeta-Alpha shows a breakdown of 91.5%
Key steps involve problem definition, datapreparation, and algorithm selection. Data quality significantly impacts model performance. Predictive analytics uses historical data to forecast future trends, such as stock market movements or customer churn. Types include supervised, unsupervised, and reinforcement learning.
I spent over a decade of my career developing large-scale data pipelines to transform both structured and unstructured data into formats that can be utilized in downstream systems. I also have experience in building large-scale distributed text search and NaturalLanguageProcessing (NLP) systems.
Data preprocessing Text data can come from diverse sources and exist in a wide variety of formats such as PDF, HTML, JSON, and Microsoft Office documents such as Word, Excel, and PowerPoint. Its rare to already have access to text data that can be readily processed and fed into an LLM for training.
Sales teams can forecast trends, optimize lead scoring, and enhance customer engagement all while reducing manual data analysis. IBM Watson A pioneer in AI-driven analytics, IBM Watson transforms enterprise operations with naturallanguageprocessing, machine learning, and predictive modeling.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content