This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Organizations can effectively manage the quality of their information by doing dataprofiling. Businesses must first profiledata metrics to extract valuable and practical insights from data. Dataprofiling is becoming increasingly essential as more firms generate huge quantities of data every day.
These SQL assets can be used in downstream operations like dataprofiling, analysis, or even exporting to other systems for further processing. Updated asset view based on the UpdatedQuery Step 11: Profile the Microsegment Run profiling on the newly created microsegment.
When we talk about data integrity, we’re referring to the overarching completeness, accuracy, consistency, accessibility, and security of an organization’s data. Together, these factors determine the reliability of the organization’s data. DataqualityDataquality is essentially the measure of data integrity.
However, analysis of data may involve partiality or incorrect insights in case the dataquality is not adequate. Accordingly, the need for DataProfiling in ETL becomes important for ensuring higher dataquality as per business requirements. What is DataProfiling in ETL?
Summary: Dataquality is a fundamental aspect of Machine Learning. Poor-qualitydata leads to biased and unreliable models, while high-qualitydata enables accurate predictions and insights. What is DataQuality in Machine Learning? Bias in data can result in unfair and discriminatory outcomes.
Poor dataquality is one of the top barriers faced by organizations aspiring to be more data-driven. Ill-timed business decisions and misinformed business processes, missed revenue opportunities, failed business initiatives and complex data systems can all stem from dataquality issues.
As such, the quality of their data can make or break the success of the company. This article will guide you through the concept of a dataquality framework, its essential components, and how to implement it effectively within your organization. What is a dataquality framework?
Dataquality plays a significant role in helping organizations strategize their policies that can keep them ahead of the crowd. Hence, companies need to adopt the right strategies that can help them filter the relevant data from the unwanted ones and get accurate and precise output.
In this blog, we are going to unfold the two key aspects of data management that is Data Observability and DataQuality. Data is the lifeblood of the digital age. Today, every organization tries to explore the significant aspects of data and its applications.
DataQuality Now that you’ve learned more about your data and cleaned it up, it’s time to ensure the quality of your data is up to par. With these data exploration tools, you can determine if your data is accurate, consistent, and reliable.
With built-in components and integration with Google Cloud services, Vertex AI simplifies the end-to-end machine learning process, making it easier for datascience teams to build and deploy models at scale. Metaflow Metaflow helps data scientists and machine learning engineers build, manage, and deploy datascience projects.
This monitoring requires robust data management and processing infrastructure. Data Velocity: High-velocity data streams can quickly overwhelm monitoring systems, leading to latency and performance issues. Dataprofiling can help identify issues, such as data anomalies or inconsistencies.
Data Observability and DataQuality are two key aspects of data management. The focus of this blog is going to be on Data Observability tools and their key framework. The growing landscape of technology has motivated organizations to adopt newer ways to harness the power of data. What is Data Observability?
By maintaining clean and reliable data, businesses can avoid costly mistakes, enhance operational efficiency, and gain a competitive edge in their respective industries. Best Data Hygiene Tools & Software Trifacta Wrangler Pros: User-friendly interface with drag-and-drop functionality. Provides real-time data monitoring and alerts.
Data engineers play a crucial role in managing and processing big data Ensuring dataquality and integrity Dataquality and integrity are essential for accurate data analysis. Data engineers are responsible for ensuring that the data collected is accurate, consistent, and reliable.
Assessment Evaluate the existing dataquality and structure. This step involves identifying any data cleansing or transformation needed to ensure compatibility with the target system. Assessing dataquality upfront can prevent issues later in the migration process.
Data scientists can train large language models (LLMs) and generative AI like GPT-3.5 to generate natural language reports from tabular data that help human agents easily interpret complex dataprofiles on potential borrowers. See what Snorkel can do to accelerate your datascience and machine learning teams.
Data scientists can train large language models (LLMs) and generative AI like GPT-3.5 to generate natural language reports from tabular data that help human agents easily interpret complex dataprofiles on potential borrowers. Learn more See what Snorkel can do to accelerate your datascience and machine learning teams.
How to become a data scientist Data transformation also plays a crucial role in dealing with varying scales of features, enabling algorithms to treat each feature equally during analysis Noise reduction As part of data preprocessing, reducing noise is vital for enhancing dataquality.
Data warehousing (DW) and business intelligence (BI) projects are a high priority for many organizations who seek to empower more and better data-driven decisions and actions throughout their enterprises. These groups want to expand their user base for data discovery, BI, and analytics so that their business […].
Data scientists can train large language models (LLMs) and generative AI like GPT-3.5 to generate natural language reports from tabular data that help human agents easily interpret complex dataprofiles on potential borrowers. Improve the accuracy of credit scoring predictions.
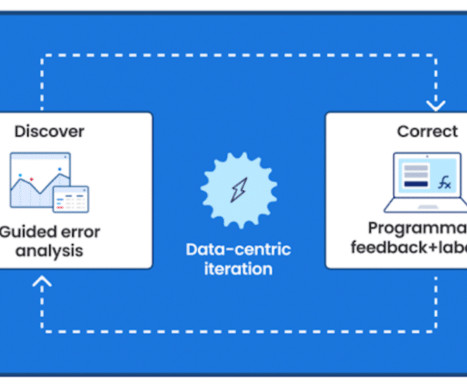
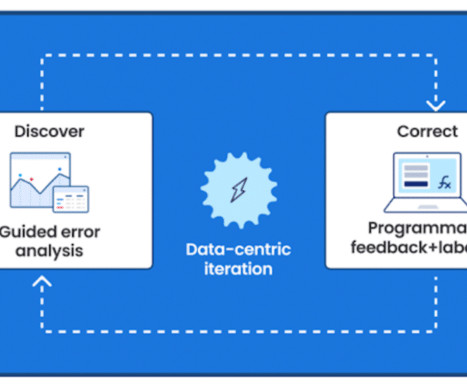
Three experts from Capital One ’s datascience team spoke as a panel at our Future of Data-Centric AI conference in 2022. Please welcome to the stage, Senior Director of Applied ML and Research, Bayan Bruss; Director of DataScience, Erin Babinski; and Head of Data and Machine Learning, Kishore Mosaliganti.
Three experts from Capital One ’s datascience team spoke as a panel at our Future of Data-Centric AI conference in 2022. Please welcome to the stage, Senior Director of Applied ML and Research, Bayan Bruss; Director of DataScience, Erin Babinski; and Head of Data and Machine Learning, Kishore Mosaliganti.
In Part 1 and Part 2 of this series, we described how data warehousing (DW) and business intelligence (BI) projects are a high priority for many organizations. Project sponsors seek to empower more and better data-driven decisions and actions throughout their enterprise; they intend to expand their […].
In Part 1 of this series, we described how data warehousing (DW) and business intelligence (BI) projects are a high priority for many organizations. Project sponsors seek to empower more and better data-driven decisions and actions throughout their enterprise; they intend to expand their user base for […].
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






























Let's personalize your content