This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
generally available on May 24, Alation introduces the Open DataQuality Initiative for the modern data stack, giving customers the freedom to choose the dataquality vendor that’s best for them with the added confidence that those tools will integrate seamlessly with Alation’s Data Catalog and Data Governance application.
When we talk about data integrity, we’re referring to the overarching completeness, accuracy, consistency, accessibility, and security of an organization’s data. Together, these factors determine the reliability of the organization’s data. DataqualityDataquality is essentially the measure of data integrity.
Alation and Bigeye have partnered to bring data observability and dataquality monitoring into the data catalog. Read to learn how our newly combined capabilities put more trustworthy, qualitydata into the hands of those who are best equipped to leverage it. trillion each year due to poor dataquality.
As such, the quality of their data can make or break the success of the company. This article will guide you through the concept of a dataquality framework, its essential components, and how to implement it effectively within your organization. What is a dataquality framework?
Some popular end-to-end MLOps platforms in 2023 Amazon SageMaker Amazon SageMaker provides a unified interface for data preprocessing, model training, and experimentation, allowing datascientists to collaborate and share code easily. Check out the Kubeflow documentation.
Follow five essential steps for success in making your data AI ready with data integration. Define clear goals, assess your data landscape, choose the right tools, ensure dataquality and governance, and continuously optimize your integration processes.
Its goal is to help with a quick analysis of target characteristics, training vs testing data, and other such data characterization tasks. Apache Superset GitHub | Website Apache Superset is a must-try project for any ML engineer, datascientist, or data analyst.
In the previous blog , we discussed how Alation provides a platform for datascientists and analysts to complete projects and analysis at speed. In this blog we will discuss how Alation helps minimize risk with active data governance. But governance is a time-consuming process (for users and data stewards alike).
The primary goal of model monitoring is to ensure that the model remains effective and reliable in making predictions or decisions, even as the data or environment in which it operates evolves. This monitoring requires robust data management and processing infrastructure. We pay our contributors, and we don’t sell ads.
They are responsible for designing, building, and maintaining the infrastructure and tools needed to manage and process large volumes of data effectively. This involves working closely with data analysts and datascientists to ensure that data is stored, processed, and analyzed efficiently to derive insights that inform decision-making.
Data Observability and DataQuality are two key aspects of data management. The focus of this blog is going to be on Data Observability tools and their key framework. The growing landscape of technology has motivated organizations to adopt newer ways to harness the power of data. What is Data Observability?
Data preprocessing ensures the removal of incorrect, incomplete, and inaccurate data from datasets, leading to the creation of accurate and useful datasets for analysis ( Image Credit ) Data completeness One of the primary requirements for data preprocessing is ensuring that the dataset is complete, with minimal missing values.
FMs can even transform dense tabular data into digestible consumer profiles. Datascientists can train large language models (LLMs) and generative AI like GPT-3.5 to generate natural language reports from tabular data that help human agents easily interpret complex dataprofiles on potential borrowers.
FMs can even transform dense tabular data into digestible consumer profiles. Datascientists can train large language models (LLMs) and generative AI like GPT-3.5 to generate natural language reports from tabular data that help human agents easily interpret complex dataprofiles on potential borrowers.
FMs can even transform dense tabular data into digestible consumer profiles. Datascientists can train large language models (LLMs) and generative AI like GPT-3.5 to generate natural language reports from tabular data that help human agents easily interpret complex dataprofiles on potential borrowers.
ETL pipeline | Source: Author These activities involve extracting data from one system, transforming it, and then processing it into another target system where it can be stored and managed. ML heavily relies on ETL pipelines as the accuracy and effectiveness of a model are directly impacted by the quality of the training data.
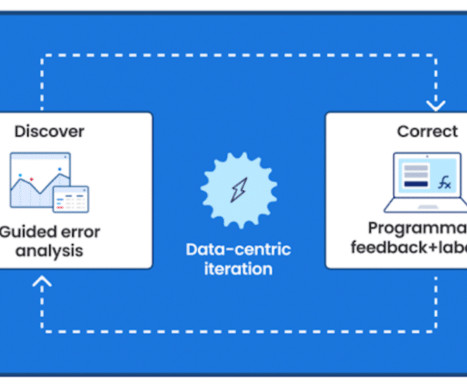
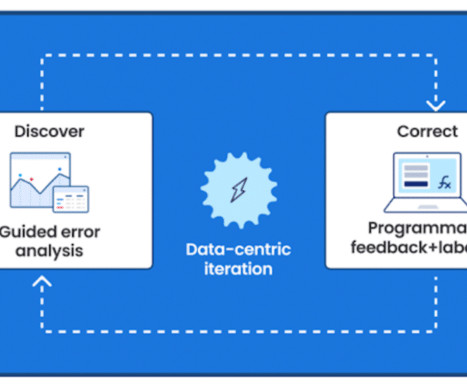
My name is Erin Babinski and I’m a datascientist at Capital One, and I’m speaking today with my colleagues Bayan and Kishore. We’re here to talk to you all about data-centric AI. All right, so let’s set the stage first with some examples: a focus on dataquality leads to better ML-powered products.
My name is Erin Babinski and I’m a datascientist at Capital One, and I’m speaking today with my colleagues Bayan and Kishore. We’re here to talk to you all about data-centric AI. All right, so let’s set the stage first with some examples: a focus on dataquality leads to better ML-powered products.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.























Let's personalize your content