This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Summary: Dataquality is a fundamental aspect of MachineLearning. Poor-qualitydata leads to biased and unreliable models, while high-qualitydata enables accurate predictions and insights. What is DataQuality in MachineLearning?
Source: Author Introduction Machinelearning model monitoring tracks the performance and behavior of a machinelearning model over time. Organizations can ensure that their machine-learning models remain robust and trustworthy over time by implementing effective model monitoring practices.
generally available on May 24, Alation introduces the Open DataQuality Initiative for the modern data stack, giving customers the freedom to choose the dataquality vendor that’s best for them with the added confidence that those tools will integrate seamlessly with Alation’s Data Catalog and Data Governance application.
Several weeks ago (prior to the Omicron wave), I got to attend my first conference in roughly two years: Dataversity’s DataQuality and Information Quality Conference. Ryan Doupe, Chief Data Officer of American Fidelity, held a thought-provoking session that resonated with me. Step 2: Data Definitions.
When we talk about data integrity, we’re referring to the overarching completeness, accuracy, consistency, accessibility, and security of an organization’s data. Together, these factors determine the reliability of the organization’s data. DataqualityDataquality is essentially the measure of data integrity.
How to evaluate MLOps tools and platforms Like every software solution, evaluating MLOps (MachineLearning Operations) tools and platforms can be a complex task as it requires consideration of varying factors. Pay-as-you-go pricing makes it easy to scale when needed.
Image generated with Midjourney Organizations increasingly rely on data to make business decisions, develop strategies, or even make data or machinelearning models their key product. As such, the quality of their data can make or break the success of the company. What is a dataquality framework?
How to Scale Your DataQuality Operations with AI and ML: In the fast-paced digital landscape of today, data has become the cornerstone of success for organizations across the globe. Every day, companies generate and collect vast amounts of data, ranging from customer information to market trends.
Dataquality plays a significant role in helping organizations strategize their policies that can keep them ahead of the crowd. Hence, companies need to adopt the right strategies that can help them filter the relevant data from the unwanted ones and get accurate and precise output.
In this blog, we are going to unfold the two key aspects of data management that is Data Observability and DataQuality. Data is the lifeblood of the digital age. Today, every organization tries to explore the significant aspects of data and its applications.
Key Takeaways: Data integrity is essential for AI success and reliability – helping you prevent harmful biases and inaccuracies in AI models. Robust data governance for AI ensures data privacy, compliance, and ethical AI use. Proactive dataquality measures are critical, especially in AI applications.
There are many well-known libraries and platforms for data analysis such as Pandas and Tableau, in addition to analytical databases like ClickHouse, MariaDB, Apache Druid, Apache Pinot, Google BigQuery, Amazon RedShift, etc. With these data exploration tools, you can determine if your data is accurate, consistent, and reliable.
Data engineers play a crucial role in managing and processing big data Ensuring dataquality and integrity Dataquality and integrity are essential for accurate data analysis. Data engineers are responsible for ensuring that the data collected is accurate, consistent, and reliable.
In the digital age, the abundance of textual information available on the internet, particularly on platforms like Twitter, blogs, and e-commerce websites, has led to an exponential growth in unstructured data. Text data is often unstructured, making it challenging to directly apply machinelearning algorithms for sentiment analysis.
They shore up privacy and security, embrace distributed workforce management, and innovate around artificial intelligence and machinelearning-based automation. The key to success within all of these initiatives is high-integrity data. Only 46% of respondents rate their dataquality as “high” or “very high.”
Data Observability and DataQuality are two key aspects of data management. The focus of this blog is going to be on Data Observability tools and their key framework. The growing landscape of technology has motivated organizations to adopt newer ways to harness the power of data. What is Data Observability?
It provides a unique ability to automate or accelerate user tasks, resulting in benefits like: improved efficiency greater productivity reduced dependence on manual labor Let’s look at AI-enabled dataquality solutions as an example. Problem: “We’re unsure about the quality of our existing data and how to improve it!”
Assessment Evaluate the existing dataquality and structure. This step involves identifying any data cleansing or transformation needed to ensure compatibility with the target system. Assessing dataquality upfront can prevent issues later in the migration process.
Artificial intelligence and machinelearning (AI/ML) offer new avenues for credit scoring solutions and could usher in a new era of fairness, efficiency, and risk management. Traditional credit scoring models rely on static variables and historical data like income, employment, and debt-to-income ratio. Book a demo today.
Often the Data Team, comprising Data and ML Engineers , needs to build this infrastructure, and this experience can be painful. We also discuss different types of ETL pipelines for ML use cases and provide real-world examples of their use to help data engineers choose the right one.
Artificial intelligence and machinelearning (AI/ML) offer new avenues for credit scoring solutions and could usher in a new era of fairness, efficiency, and risk management. Traditional credit scoring models rely on static variables and historical data like income, employment, and debt-to-income ratio. Book a demo today.
Three experts from Capital One ’s data science team spoke as a panel at our Future of Data-Centric AI conference in 2022. Please welcome to the stage, Senior Director of Applied ML and Research, Bayan Bruss; Director of Data Science, Erin Babinski; and Head of Data and MachineLearning, Kishore Mosaliganti.
Three experts from Capital One ’s data science team spoke as a panel at our Future of Data-Centric AI conference in 2022. Please welcome to the stage, Senior Director of Applied ML and Research, Bayan Bruss; Director of Data Science, Erin Babinski; and Head of Data and MachineLearning, Kishore Mosaliganti.
Artificial intelligence and machinelearning (AI/ML) offer new avenues for credit scoring solutions and could usher in a new era of fairness, efficiency, and risk management. Traditional credit scoring models rely on static variables and historical data like income, employment, and debt-to-income ratio.
Scalability : A data pipeline is designed to handle large volumes of data, making it possible to process and analyze data in real-time, even as the data grows. Dataquality : A data pipeline can help improve the quality of data by automating the process of cleaning and transforming the data.
Modern data governance relies on automation, which reduces costs. Automated tools make data governance processes very cost-effective. Machinelearning plays a key role, as it can increase the speed and accuracy of metadata capture and categorization. This empowers leaders to see and refine human processes around data.
As data collection and volume surges, enterprises are inundated in both data and its metadata. For this reason, data intelligence software has increasingly leveraged artificial intelligence and machinelearning (AI and ML) to automate curation activities, which deliver trustworthy data to those who need it.
ETL architecture components The architecture of ETL pipelines is composed of several key components that ensure seamless operation throughout the data processing stages: Dataprofiling: Assesses the quality of raw data, determining its suitability for the ETL process and setting the stage for effective transformation.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



















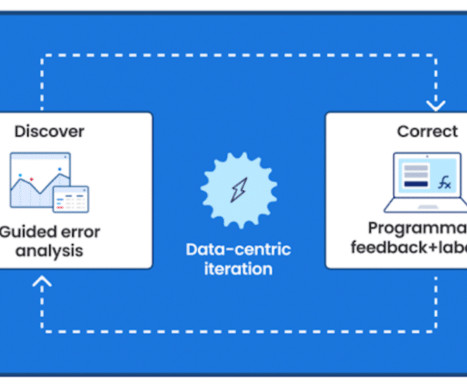

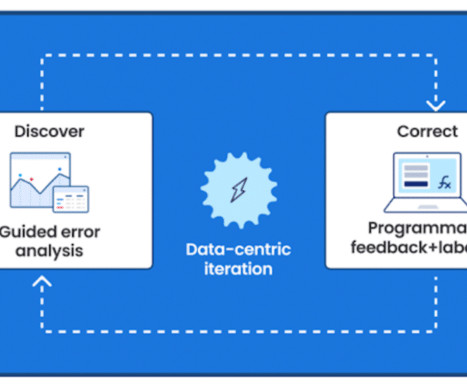













Let's personalize your content