This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
generally available on May 24, Alation introduces the Open DataQuality Initiative for the modern data stack, giving customers the freedom to choose the dataquality vendor that’s best for them with the added confidence that those tools will integrate seamlessly with Alation’s Data Catalog and Data Governance application.
How to Scale Your DataQuality Operations with AI and ML: In the fast-paced digital landscape of today, data has become the cornerstone of success for organizations across the globe. Every day, companies generate and collect vast amounts of data, ranging from customer information to market trends.
Alignment to other tools in the organization’s tech stack Consider how well the MLOps tool integrates with your existing tools and workflows, such as data sources, data engineering platforms, code repositories, CI/CD pipelines, monitoring systems, etc. and Pandas or Apache Spark DataFrames.
As such, the quality of their data can make or break the success of the company. This article will guide you through the concept of a dataquality framework, its essential components, and how to implement it effectively within your organization. What is a dataquality framework?
Dataquality plays a significant role in helping organizations strategize their policies that can keep them ahead of the crowd. Hence, companies need to adopt the right strategies that can help them filter the relevant data from the unwanted ones and get accurate and precise output.
Many tools and techniques are available for ML model monitoring in production, such as automated monitoring systems, dashboarding and visualization, and alerts and notifications. Learn more about building effective ML teams with our free ebook. This monitoring requires robust data management and processing infrastructure.
Its goal is to help with a quick analysis of target characteristics, training vs testing data, and other such data characterization tasks. Apache Superset GitHub | Website Apache Superset is a must-try project for any ML engineer, data scientist, or data analyst.
From data processing to quick insights, robust pipelines are a must for any ML system. Often the Data Team, comprising Data and ML Engineers , needs to build this infrastructure, and this experience can be painful. However, efficient use of ETL pipelines in ML can help make their life much easier.
It provides a unique ability to automate or accelerate user tasks, resulting in benefits like: improved efficiency greater productivity reduced dependence on manual labor Let’s look at AI-enabled dataquality solutions as an example. Problem: “We’re unsure about the quality of our existing data and how to improve it!”
In the next section, let’s take a deeper look into how these key attributes help data scientists and analysts make faster, more informed decisions, while supporting stewards in their quest to scale governance policies on the Data Cloud easily. Find Trusted Data. Verifying quality is time consuming.
Artificial intelligence and machine learning (AI/ML) offer new avenues for credit scoring solutions and could usher in a new era of fairness, efficiency, and risk management. Traditional credit scoring models rely on static variables and historical data like income, employment, and debt-to-income ratio. Supercharge predictive modeling.
Artificial intelligence and machine learning (AI/ML) offer new avenues for credit scoring solutions and could usher in a new era of fairness, efficiency, and risk management. Traditional credit scoring models rely on static variables and historical data like income, employment, and debt-to-income ratio. Supercharge predictive modeling.
Artificial intelligence and machine learning (AI/ML) offer new avenues for credit scoring solutions and could usher in a new era of fairness, efficiency, and risk management. Traditional credit scoring models rely on static variables and historical data like income, employment, and debt-to-income ratio. Supercharge predictive modeling.
Data pipeline stages But before delving deeper into the technical aspects of these tools, let’s quickly understand the core components of a data pipeline succinctly captured in the image below: Data pipeline stages | Source: Author What does a good data pipeline look like?
Piyush Puri: Please join me in welcoming to the stage our next speakers who are here to talk about data-centric AI at Capital One, the amazing team who may or may not have coined the term, “what’s in your wallet.” What can get less attention is the foundational element of what makes AI and ML shine. That’s data.
Piyush Puri: Please join me in welcoming to the stage our next speakers who are here to talk about data-centric AI at Capital One, the amazing team who may or may not have coined the term, “what’s in your wallet.” What can get less attention is the foundational element of what makes AI and ML shine. That’s data.
Under an active data governance framework , a Behavioral Analysis Engine will use AI, ML and DI to crawl all data and metadata, spot patterns, and implement solutions. Data Governance and Data Strategy. Finally, data catalogs leverage behavioral metadata to glean insights into how humans interact with data.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











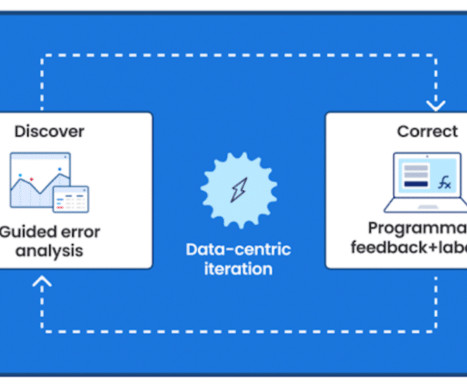
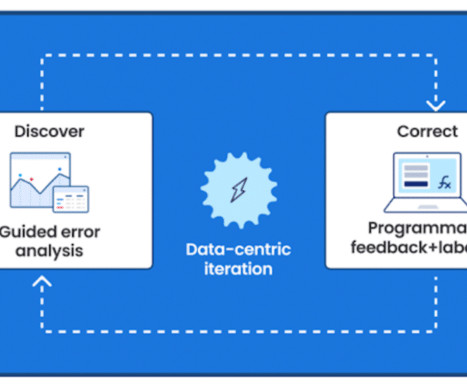











Let's personalize your content