This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Its goal is to help with a quick analysis of target characteristics, training vs testing data, and other such data characterization tasks. Apache Superset GitHub | Website Apache Superset is a must-try project for any ML engineer, datascientist, or data analyst.
Some popular end-to-end MLOps platforms in 2023 Amazon SageMaker Amazon SageMaker provides a unified interface for data preprocessing, model training, and experimentation, allowing datascientists to collaborate and share code easily. Check out the Kubeflow documentation.
In the previous blog , we discussed how Alation provides a platform for datascientists and analysts to complete projects and analysis at speed. In this blog we will discuss how Alation helps minimize risk with active data governance. But governance is a time-consuming process (for users and data stewards alike).
To measure and maintain high-quality data, organizations use data quality rules, also known as data validation rules, to ensure datasets meet criteria as defined by the organization. Additional time is saved that would have otherwise been wasted on acting on incomplete or inaccurate data.
The primary goal of model monitoring is to ensure that the model remains effective and reliable in making predictions or decisions, even as the data or environment in which it operates evolves. Dataprofiling can help identify issues, such as data anomalies or inconsistencies.
Solution: Ensure real-time insights and predictive analytics are both accurate and actionable with data integration. To enable smarter decision-making and operational efficiency, your business users, analysts, and datascientists need real-time, self-service access to data from across the business.
Data preprocessing ensures the removal of incorrect, incomplete, and inaccurate data from datasets, leading to the creation of accurate and useful datasets for analysis ( Image Credit ) Data completeness One of the primary requirements for data preprocessing is ensuring that the dataset is complete, with minimal missing values.
FMs can even transform dense tabular data into digestible consumer profiles. Datascientists can train large language models (LLMs) and generative AI like GPT-3.5 to generate natural language reports from tabular data that help human agents easily interpret complex dataprofiles on potential borrowers.
As a platform for data intelligence , Alation boasts open APIs with which Bigeye can easily integrate. This integration empowers all data consumers, from business users, to stewards, analysts, and datascientists, to access trustworthy and reliable data.
FMs can even transform dense tabular data into digestible consumer profiles. Datascientists can train large language models (LLMs) and generative AI like GPT-3.5 to generate natural language reports from tabular data that help human agents easily interpret complex dataprofiles on potential borrowers.
FMs can even transform dense tabular data into digestible consumer profiles. Datascientists can train large language models (LLMs) and generative AI like GPT-3.5 to generate natural language reports from tabular data that help human agents easily interpret complex dataprofiles on potential borrowers.
They are responsible for designing, building, and maintaining the infrastructure and tools needed to manage and process large volumes of data effectively. This involves working closely with data analysts and datascientists to ensure that data is stored, processed, and analyzed efficiently to derive insights that inform decision-making.
Prime examples of this in the data catalog include: Trust Flags — Allow the data community to endorse, warn, and deprecate data to signal whether data can or can’t be used. DataProfiling — Statistics such as min, max, mean, and null can be applied to certain columns to understand its shape.
How can financial services companies build, expand and optimize their use of data and ML? Open and free financial datasets and economic datasets are an essential starting point for datascientists and engineers who are developing and training ML models for finance. But sadly, they can be hard to come by. Get the datasets here.
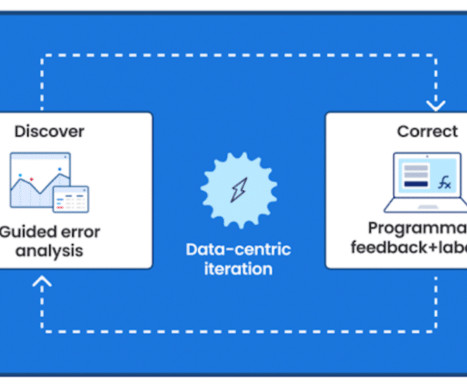
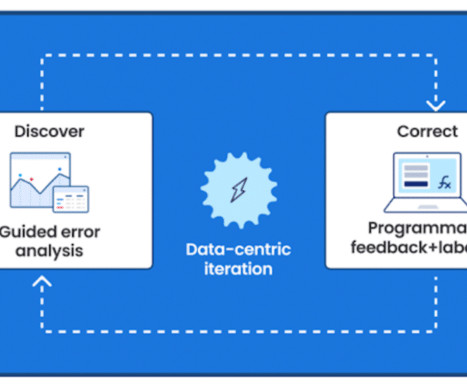
My name is Erin Babinski and I’m a datascientist at Capital One, and I’m speaking today with my colleagues Bayan and Kishore. We’re here to talk to you all about data-centric AI. Publishing standards for data and governance of that data is either missing or very widely far from an ideal.
My name is Erin Babinski and I’m a datascientist at Capital One, and I’m speaking today with my colleagues Bayan and Kishore. We’re here to talk to you all about data-centric AI. Publishing standards for data and governance of that data is either missing or very widely far from an ideal.
The sample set of de-identified, already publicly shared data included thousands of anonymized user profiles, with more than fifty user-metadata points, but many had inconsistent or missing meta-data/profile information. Matthew Rhodes is a DataScientist working in the Amazon ML Solutions Lab.
ETL pipeline | Source: Author These activities involve extracting data from one system, transforming it, and then processing it into another target system where it can be stored and managed. ML heavily relies on ETL pipelines as the accuracy and effectiveness of a model are directly impacted by the quality of the training data.
Data quality is crucial across various domains within an organization. For example, software engineers focus on operational accuracy and efficiency, while datascientists require clean data for training machine learning models. Without high-quality data, even the most advanced models can't deliver value.
Key Features Benefit from the real-time surveillance thus, it helps in identifying potential issues in real-time It comes with advanced analytical capacities contributing to well-informed decision-making; Intuitively explore and grasp the intricacies of data.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

























Let's personalize your content