This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Organizations can effectively manage the quality of their information by doing dataprofiling. Businesses must first profiledata metrics to extract valuable and practical insights from data. Dataprofiling is becoming increasingly essential as more firms generate huge quantities of data every day.
You may combine event data (e.g., shot types and results) with tracking data (e.g., Effective data collection ensures you have all the necessary information to begin the analysis, setting the stage for reliable insights into improving shot conversion rates or any other defined problem.
Almost all organisations nowadays make informed decisions by leveraging data and analysing the market effectively. However, analysis of data may involve partiality or incorrect insights in case the data quality is not adequate. What is DataProfiling in ETL? integer, string, date).
For any data user in an enterprise today, dataprofiling is a key tool for resolving data quality issues and building new data solutions. In this blog, we’ll cover the definition of dataprofiling, top use cases, and share important techniques and best practices for dataprofiling today.
Data entry errors will gradually be reduced by these technologies, and operators will be able to fix the problems as soon as they become aware of them. Make DataProfiling Available. To ensure that the data in the network is accurate, dataprofiling is a typical procedure. Streamline the Methodology.
But the Internet and search engines becoming mainstream enabled never-before-seen access to unstructured content and not just structured data. It was very promising as a way of managing datas scale challenges, but data integrity once again became top of mind. The SLM (small language model) is the new data mart.
Business users want to know where that data lives, understand if people are accessing the right data at the right time, and be assured that the data is of high quality. But they are not always out shopping for Data Quality […].
Businesses project planning is key to success and now they are increasingly rely on data projects to make informed decisions, enhance operations, and achieve strategic goals. However, the success of any data project hinges on a critical, often overlooked phase: gathering requirements. What are the data quality expectations?
The developmental capabilities and precision of AI ultimately depend on the gathering of data – Big Data. Where better to find a continuous stream of information than within the highly active and engaging community of students. AI systems allow for the analysis of more granular patterns of the student’s dataprofile.
The purpose of data archiving is to ensure that important information is not lost or corrupted over time and to reduce the cost and complexity of managing large amounts of data on primary storage systems. This information helps organizations understand what data they have, where it’s located, and how it can be used.
Data Quality Now that you’ve learned more about your data and cleaned it up, it’s time to ensure the quality of your data is up to par. With these data exploration tools, you can determine if your data is accurate, consistent, and reliable.
Several weeks ago (prior to the Omicron wave), I got to attend my first conference in roughly two years: Dataversity’s Data Quality and Information Quality Conference. Ryan Doupe, Chief Data Officer of American Fidelity, held a thought-provoking session that resonated with me. Step 4: Data Sources. Step 5: DataProfiling.
Data must reside in Amazon S3 in an AWS Region supported by the service. It’s highly recommended to run a dataprofile before you train (use an automated dataprofiler for Amazon Fraud Detector ). It’s recommended to use at least 3–6 months of data. Two headers are required: EVENT_TIMESTAMP and EVENT_LABEL.
The more complete, accurate and consistent a dataset is, the more informed business intelligence and business processes become. The different types of data integrity There are two main categories of data integrity: Physical data integrity and logical data integrity. Are there missing data elements or blank fields?
Data integration breaks down data silos by giving users self-service access to enterprise data, which ensures your AI initiatives are fueled by complete, relevant, and timely information. Defining data quality and governance roles and responsibilities, including data owners, stewards, and analysts.
. • 41% of respondents say their data quality strategy supports structured data only, even though they use all kinds of data • Only 16% have a strategy encompassing all types of relevant data 3. Enterprises have only begun to automate their data quality management processes.” Adopt process automation platforms.
This has created many different data quality tools and offerings in the market today and we’re thrilled to see the innovation. People will need high-quality data to trust information and make decisions. DataProfiling — Statistics such as min, max, mean, and null can be applied to certain columns to understand its shape.
Every business, irrespective of the niche of operations is harnessing the power of data and make their strategies result-oriented. As compared to the earlier times, businesses are inundated with vast amounts of information. To harness this information in the best interest of the business, it is imperative to filter quality inputs.
According to Entrepreneur , Gartner predicts, “through 2022, only 20% of organizations investing in information governance will succeed in scaling governance for digital business.” This survey result shows that organizations need a method to help them implement Data Governance at scale. Find Trusted Data. Two problems arise.
How to Scale Your Data Quality Operations with AI and ML: In the fast-paced digital landscape of today, data has become the cornerstone of success for organizations across the globe. Every day, companies generate and collect vast amounts of data, ranging from customer information to market trends.
By analyzing the sentiment of users towards certain products, services, or topics, sentiment analysis provides valuable insights that empower businesses and organizations to make informed decisions, gauge public opinion, and improve customer experiences. Noise in data can arise due to data collection errors, system glitches, or human errors.
The sample set of de-identified, already publicly shared data included thousands of anonymized user profiles, with more than fifty user-metadata points, but many had inconsistent or missing meta-data/profileinformation. For more information refer to Creating a Custom dataset group.
Badulescu cites two examples: Quality rule recommendations: AI systems can analyze existing data to understand data ranges, anomalies, relationships, and more. Then, this information can be used to suggest new quality rules that will help prevent data issues proactively.
Can you debug system information? Metadata management : Robust metadata management capabilities enable you to associate relevant information, such as dataset descriptions, annotations, preprocessing steps, and licensing details, with the datasets, facilitating better organization and understanding of the data.
This platform should: Connect to diverse data sources (on-prem, hybrid, legacy, or modern). Extract data quality information. Monitor data anomalies and data drift. Track how data transforms, noting unexpected changes during its lifecycle. Alation and Bigeye have partnered to deliver this platform.
” Solution: Intelligent solutions can mine metadata, analyze usage patterns and frequencies, and identify relationships among data elements – all through automation, with minimal human input. Problem: “We face challenges in manually classifying, cataloging, and organizing large volumes of data.”
What Is Master Data Management (MDM)? MDM is a discipline that helps organize critical information to avoid duplication, inconsistency, and other data quality issues. Transactional systems and data warehouses can then use the golden records as the entity’s most current, trusted representation.
Hence, the quality of data is significant here. Quality data fuels business decisions, informs scientific research, drives technological innovations, and shapes our understanding of the world. The Relevance of Data Quality Data quality refers to the accuracy, completeness, consistency, and reliability of data.
They are responsible for designing, building, and maintaining the infrastructure and tools needed to manage and process large volumes of data effectively. This involves working closely with data analysts and data scientists to ensure that data is stored, processed, and analyzed efficiently to derive insights that inform decision-making.
Missing Data Incomplete datasets with missing values can distort the training process and lead to inaccurate models. Missing data can occur due to various reasons, such as data entry errors, loss of information, or non-responses in surveys. Both scenarios result in suboptimal model performance.
By answering key questions around the who, what, where and when of a given data asset, DI paints a picture of why folks might use it, educating on that asset’s reliability and relative value. Insights into how an asset’s been used in the past inform how it might be intelligently applied in the future. Why keep data at all?
When errors do happen, we want customers (or employees leveraging the toolkit at a customer) to have the ability to provide enough information back to the development team so we can triage and resolve the issue. To make this easier, we have added a diagnose command to the toolkit! As with any conversion tool, you have a source and a target.
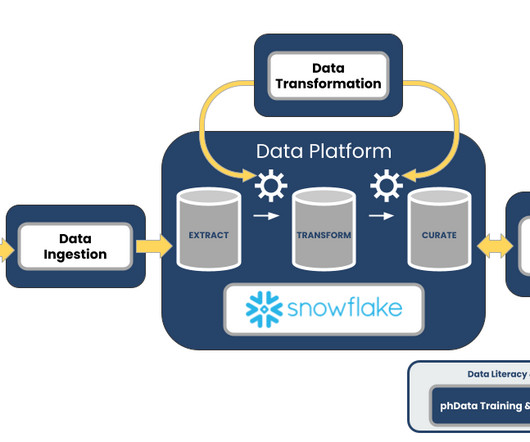
This automation includes things like SQL translation during a data platform migration (SQLMorph), making changes to your Snowflake information architecture (Tram), and checking for parity and data quality between platforms (Data Source Automation). But what does this actually mean?
As a result, Gartner estimates that poor data quality costs organizations an average of $13 million annually. High-quality data significantly reduces the risk of costly errors, and the resulting penalties or legal issues. Completeness determines whether all required data fields are filled with appropriate and valid information.
Healthcare and Life Sciences (HCLS) companies face a multitude of challenges when it comes to managing and analyzing data. From the sheer volume of information to the complexity of data sources and the need for real-time insights, HCLS companies constantly need to adapt and overcome these challenges to stay ahead of the competition.
This involves implementing data validation processes, data cleansing routines, and quality checks to eliminate errors, inaccuracies, or inconsistencies. Reliable data is essential for making informed decisions and conducting meaningful analyses. Quality Data quality is about the reliability and accuracy of your data.
Provision Tool Updates For those who aren’t familiar with the Provision tool, it gives customers the flexibility to allow them to define and apply their own information architecture in a standardized way to Snowflake. For more information on the SQL Collect tool, check out the resource page!
Our Data Source tool is unique to the CLI and enables a wide variety of use cases: Platform migration validation Platform migration automation Metadata collection and visualization Tracking platform changes over time Dataprofiling and quality at scale Data pipeline generation and automation dbt project generation By leveraging profilinginformation (..)
These include information about budgets, monthly wages, occupations and a lot more. Global Financial Data (GDF) An extensive database of current and historical financial data, providing updated information alongside data from hundreds of years ago. Data is organized annually and was last updated in November 2021.
This process involves real-time monitoring and documentation to provide visibility on the data quality, thereby helping the organization detect and address data-related issues. Bigeye Its analytical prowess and data visualization capabilities will help Data Scientists make effective data-driven decision-making.
Data warehousing (DW) and business intelligence (BI) projects are a high priority for many organizations who seek to empower more and better data-driven decisions and actions throughout their enterprises. These groups want to expand their user base for data discovery, BI, and analytics so that their business […].
For example, when customers log onto our website or mobile app, our conversational AI capabilities can help find the information they may want. To borrow another example from Andrew Ng, improving the quality of data can have a tremendous impact on model performance. This is to say that clean data can better teach our models.
For example, when customers log onto our website or mobile app, our conversational AI capabilities can help find the information they may want. To borrow another example from Andrew Ng, improving the quality of data can have a tremendous impact on model performance. This is to say that clean data can better teach our models.
This role is commonly the chief data officer, or CDO. They will articulate the need for data governance and keep stakeholders informed. Direct reports include project managers, responsible for data governance initiatives. These folks will articulate the critical elements of data to data consumers.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content