This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Source: Author Introduction Machinelearning model monitoring tracks the performance and behavior of a machinelearning model over time. Organizations can ensure that their machine-learning models remain robust and trustworthy over time by implementing effective model monitoring practices.
Summary: Data quality is a fundamental aspect of MachineLearning. Poor-quality data leads to biased and unreliable models, while high-quality data enables accurate predictions and insights. What is Data Quality in MachineLearning? What is Data Quality in MachineLearning?
Through machinelearning and expert systems, machines can produce patterns within mass flows of data and pinpoint correlations that couldn’t possibly be immediately intuitive to humans. (AI Thousands of data points on each student are being used to assess admission applications. AI software market revenue.
How to evaluate MLOps tools and platforms Like every software solution, evaluating MLOps (MachineLearning Operations) tools and platforms can be a complex task as it requires consideration of varying factors. Pay-as-you-go pricing makes it easy to scale when needed.
There are several techniques used in intelligent data classification, including: Machinelearning : Machinelearning algorithms can be trained on large datasets to recognize patterns and categories within the data.
There are many well-known libraries and platforms for data analysis such as Pandas and Tableau, in addition to analytical databases like ClickHouse, MariaDB, Apache Druid, Apache Pinot, Google BigQuery, Amazon RedShift, etc. This tool automatically detects problems in an ML dataset.
Financial services companies are leveraging data and machinelearning to mitigate risks like fraud and cyber threats and to provide a modern customer experience. Here are 13 excellent open financial and economic datasets and data sources for financial data for machinelearning. Get the datasets here.
To improve this experience for its members, we at RallyPoint wanted to explore how machinelearning (ML) could help. The sample set of de-identified, already publicly shared data included thousands of anonymized user profiles, with more than fifty user-metadata points, but many had inconsistent or missing meta-data/profile information.
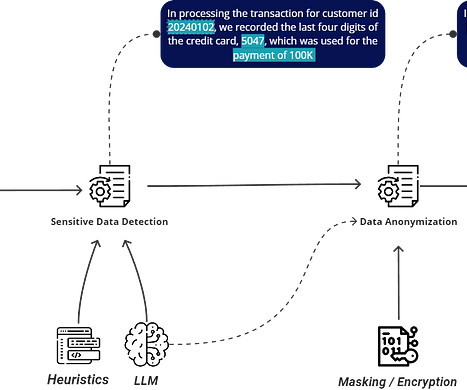
A Step-by-Step Guide to Understand and Implement an LLM-based Sensitive Data Detection WorkflowSensitive Data Detection and Masking Workflow — Image by Author Introduction What and who defines the sensitivity of data ?What What is data anonymization and pseudonymisation?What million terabytes of data is created daily.
In the first post of this three-part series, we presented a solution that demonstrates how you can automate detecting document tampering and fraud at scale using AWS AI and machinelearning (ML) services for a mortgage underwriting use case. Data must reside in Amazon S3 in an AWS Region supported by the service.
This work enables business stewards to prioritize data remediation efforts. Step 4: Data Sources. This step is about cataloging data sources and discovering data sources containing the specified critical data elements. Step 5: DataProfiling. This is done by collecting data statistics.
Data science tasks such as machinelearning also greatly benefit from good data integrity. When an underlying machinelearning model is being trained on data records that are trustworthy and accurate, the better that model will be at making business predictions or automating tasks.
In this article, we delve into the significance of data quality, how organizations are leveraging various tools to enhance it, and the transformative power of Artificial Intelligence (AI) and MachineLearning (ML) in elevating data quality to new heights. It can be employed for both regression and classification tasks.
In the digital age, the abundance of textual information available on the internet, particularly on platforms like Twitter, blogs, and e-commerce websites, has led to an exponential growth in unstructured data. Text data is often unstructured, making it challenging to directly apply machinelearning algorithms for sentiment analysis.
2) DataProfiling : To profiledata in Excel, users typically create filters and pivot tables – but problems arise when a column contains thousands of distinct values or when there are duplicates resulting from different spellings. DataRobot Data Prep. free trial. Try now for free.
Often the Data Team, comprising Data and ML Engineers , needs to build this infrastructure, and this experience can be painful. We also discuss different types of ETL pipelines for ML use cases and provide real-world examples of their use to help data engineers choose the right one. fillna( iris_transform_df[cols].mean())
Three experts from Capital One ’s data science team spoke as a panel at our Future of Data-Centric AI conference in 2022. Please welcome to the stage, Senior Director of Applied ML and Research, Bayan Bruss; Director of Data Science, Erin Babinski; and Head of Data and MachineLearning, Kishore Mosaliganti.
Three experts from Capital One ’s data science team spoke as a panel at our Future of Data-Centric AI conference in 2022. Please welcome to the stage, Senior Director of Applied ML and Research, Bayan Bruss; Director of Data Science, Erin Babinski; and Head of Data and MachineLearning, Kishore Mosaliganti.
We recommend using dataprofiling options within Power Query to assess the quality of columns, examining their validity and errors. Dataflows vs. Power Query in Power BI Desktop Dataflows and Power Query in Power BI Desktop are being used to cleanse and transform data, each with its own purposes and differences, as listed below.
Image generated with Midjourney Organizations increasingly rely on data to make business decisions, develop strategies, or even make data or machinelearning models their key product. As such, the quality of their data can make or break the success of the company. It is part of the broader Talend Data Fabric suite.
Artificial intelligence and machinelearning (AI/ML) offer new avenues for credit scoring solutions and could usher in a new era of fairness, efficiency, and risk management. Traditional credit scoring models rely on static variables and historical data like income, employment, and debt-to-income ratio. Book a demo today.
Some of these solutions include: Data quality management: Data quality management involves ensuring that the data is accurate, consistent, and complete. It includes various processes such as dataprofiling, data cleansing, and data validation.
Define data ownership, access rights, and responsibilities within your organization. A well-structured framework ensures accountability and promotes data quality. Data Quality Tools Invest in quality data management tools. Here’s how: DataProfiling Start by analyzing your data to understand its quality.
Artificial intelligence and machinelearning (AI/ML) offer new avenues for credit scoring solutions and could usher in a new era of fairness, efficiency, and risk management. Traditional credit scoring models rely on static variables and historical data like income, employment, and debt-to-income ratio. Book a demo today.
To mitigate bias, organizations must take steps to ensure data quality and data governance: Dataprofiling is a data quality capability that helps you gain insight into the data select appropriate data subsets for training.
They shore up privacy and security, embrace distributed workforce management, and innovate around artificial intelligence and machinelearning-based automation. The key to success within all of these initiatives is high-integrity data. The biggest surprise?
Some vendors leverage machinelearning to build rules where others rely on manually declared rules. These solutions exist because different industries or departments within an organization may require different types of data quality.
Quality Data quality is about the reliability and accuracy of your data. High-quality data is free from errors, inconsistencies, and anomalies. To assess data quality, you may need to perform dataprofiling, validation, and cleansing to identify and address issues like missing values, duplicates, or outliers.
By bringing the power of AI and machinelearning (ML) to the Precisely Data Integrity Suite, we aim to speed up tasks, streamline workflows, and facilitate real-time decision-making. But the strategy isn’t static – as industry advancements and domain-specific requirements develop, we adapt right along with them.
As data collection and volume surges, enterprises are inundated in both data and its metadata. For this reason, data intelligence software has increasingly leveraged artificial intelligence and machinelearning (AI and ML) to automate curation activities, which deliver trustworthy data to those who need it.
Artificial intelligence and machinelearning (AI/ML) offer new avenues for credit scoring solutions and could usher in a new era of fairness, efficiency, and risk management. Traditional credit scoring models rely on static variables and historical data like income, employment, and debt-to-income ratio.
Data Quality Assessment Evaluate the quality of existing data and address any issues before migration. This may involve dataprofiling and cleansing activities to improve data accuracy. Testing should include validating data integrity and performance in the new environment.
Get 8 different alert types like Nulls, Cardinality, Median, Variance, Skewness, and Freshness The platform sends real-time notifications promoting effective management and resolution Helps you identify trends and underlying issues Monte Carlo It uses MachineLearning to scrutinize datasets.
Modern data governance relies on automation, which reduces costs. Automated tools make data governance processes very cost-effective. Machinelearning plays a key role, as it can increase the speed and accuracy of metadata capture and categorization. With governance in the budget, leadership can prioritize it.
This is a difficult decision at the onset, as the volume of data is a factor of time and keeps varying with time, but an initial estimate can be quickly gauged by analyzing this aspect by running a pilot. Also, the industry best practices suggest performing a quick dataprofiling to understand the data growth.
ETL architecture components The architecture of ETL pipelines is composed of several key components that ensure seamless operation throughout the data processing stages: Dataprofiling: Assesses the quality of raw data, determining its suitability for the ETL process and setting the stage for effective transformation.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.








































Let's personalize your content