This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Sensor data : Sensor data can be used to train models for tasks such as object detection and anomaly detection. This data can be collected from a variety of sources, such as smartphones, wearable devices, and traffic cameras. Machine learning practices for datascientists 3.
How Long Does It Take to Learn Data Science Fundamentals?; Become a Data Science Professional in Five Steps; New Ways of Sharing Code Blocks for DataScientists; Machine Learning Algorithms for Classification; The Significance of DataQuality in Making a Successful Machine Learning Model.
Machine learning engineer vs datascientist: two distinct roles with overlapping expertise, each essential in unlocking the power of data-driven insights. As businesses strive to stay competitive and make data-driven decisions, the roles of machine learning engineers and datascientists have gained prominence.
generally available on May 24, Alation introduces the Open DataQuality Initiative for the modern data stack, giving customers the freedom to choose the dataquality vendor that’s best for them with the added confidence that those tools will integrate seamlessly with Alation’s Data Catalog and Data Governance application.
When we talk about data integrity, we’re referring to the overarching completeness, accuracy, consistency, accessibility, and security of an organization’s data. Together, these factors determine the reliability of the organization’s data. DataqualityDataquality is essentially the measure of data integrity.
The goal of MLOps is to ensure that models are reliable, secure, and scalable, while also making it easier for datascientists and engineers to develop, test, and deploy ML models. Data Management: Effective data management is crucial for ML models to work well.
The goal of ML Ops is to ensure that models are reliable, secure, and scalable, while also making it easier for datascientists and engineers to develop, test, and deploy ML models. Data Management: Effective data management is crucial for ML models to work well.
Companies rely heavily on data and analytics to find and retain talent, drive engagement, improve productivity and more across enterprise talent management. However, analytics are only as good as the quality of the data, which must be error-free, trustworthy and transparent. What is dataquality? million each year.
Data versioning is a fascinating concept that plays a crucial role in modern data management, especially in machine learning. As datasets evolve through various modifications, the ability to track changes ensures that datascientists can maintain accuracy and integrity in their projects.
However, analytics are only as good as the quality of the data, which aims to be error-free, trustworthy, and transparent. According to a Gartner report , poor dataquality costs organizations an average of USD $12.9 What is dataquality? Dataquality is critical for data governance.
In this article, we delve deeper into the key insights from the original piece to understand the significant impact of IoT on datascientists and the world at large. As billions of devices are interconnected, they produce a massive amount of real-time data that can be harnessed to gain valuable insights.
. — Peter Norvig, The Unreasonable Effectiveness of Data. Edited Photo by Taylor Vick on Unsplash In ML engineering, dataquality isn’t just critical — it’s foundational. Since 2011, Peter Norvig’s words underscore the power of a data-centric approach in machine learning. Using biased or low-qualitydata?
Metadata Enrichment: Empowering Data Governance DataQuality Tab from Metadata Enrichment Metadata enrichment is a crucial aspect of data governance, enabling organizations to enhance the quality and context of their data assets. This dataset spans a wide range of ages, from teenagers to senior citizens.
In just about any organization, the state of information quality is at the same low level – Olson, DataQualityData is everywhere! As datascientists and machine learning engineers, we spend the majority of our time working with data. Upgrade to access all of Medium.
As such, the quality of their data can make or break the success of the company. This article will guide you through the concept of a dataquality framework, its essential components, and how to implement it effectively within your organization. What is a dataquality framework?
Superior Accuracy: CatBoost uses a unique way to calculate leaf values, which helps prevent overfitting and leads to better generalization on unseen data. Reduced Hyperparameter Tuning: CatBoost tends to require less tuning than other algorithms, making it easier for beginners and saving time for experienced datascientists.
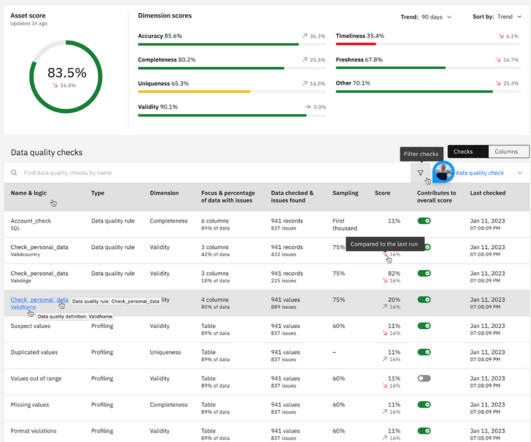
We’ve all generally heard that dataquality issues can be catastrophic. But what does that look like for data teams, in terms of dollars and cents? And who is responsible for dealing with dataquality issues?
Through data crawling, cataloguing, and indexing, they also enable you to know what data is in the lake. To preserve your digital assets, data must lastly be secured. To comprehend and transform raw, unstructured data for any specific business use, it typically takes a datascientist and specialized tools.
Top reported benefits of data governance programs include improved quality of data analytics and insights (58%), improved dataquality (58%), and increased collaboration (57%). Data governance is a top data integrity challenge, cited by 54% of organizations second only to dataquality (56%).
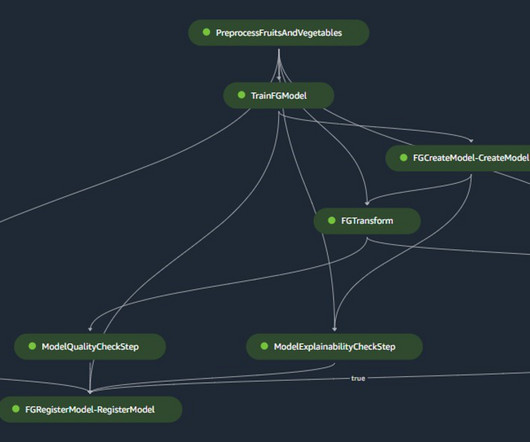
Each product translates into an AWS CloudFormation template, which is deployed when a datascientist creates a new SageMaker project with our MLOps blueprint as the foundation. These are essential for monitoring data and model quality, as well as feature attributions. Workflow B corresponds to model quality drift checks.
Amazon DataZone allows you to create and manage data zones , which are virtual data lakes that store and process your data, without the need for extensive coding or infrastructure management. Solution overview In this section, we provide an overview of three personas: the data admin, data publisher, and datascientist.
The speaker is Andrew Madson, a data analytics leader and educator. The event is for anyone interested in learning about generative AI and data storytelling, including business leaders, datascientists, and enthusiasts. Over 10,000 people from all over the world attended the event.
Some popular end-to-end MLOps platforms in 2023 Amazon SageMaker Amazon SageMaker provides a unified interface for data preprocessing, model training, and experimentation, allowing datascientists to collaborate and share code easily. Check out the Kubeflow documentation.
Learn how DataScientists use ChatGPT, a potent OpenAI language model, to improve their operations. ChatGPT is essential in the domains of natural language processing, modeling, data analysis, data cleaning, and data visualization. It facilitates exploratory Data Analysis and provides quick insights.
Descriptive analytics is a fundamental method that summarizes past data using tools like Excel or SQL to generate reports. Techniques such as data cleansing, aggregation, and trend analysis play a critical role in ensuring dataquality and relevance. DataScientists require a robust technical foundation.
Where exactly within an organization does the primary responsibility lie for ensuring that a data pipeline project generates data of high quality, and who exactly holds that responsibility? Who is accountable for ensuring that the data is accurate? Is it the data engineers? The datascientists?
Additionally, imagine being a practitioner, such as a datascientist, data engineer, or machine learning engineer, who will have the daunting task of learning how to use a multitude of different tools. There are many types of features, as shown below: The easiest example of a feature is the column within a dataset.
Jacomo Corbo is a Partner and Chief Scientist, and Bryan Richardson is an Associate Partner and Senior DataScientist, for QuantumBlack AI by McKinsey. They presented “Automating DataQuality Remediation With AI” at Snorkel AI’s The Future of Data-Centric AI Summit in 2022.
Jacomo Corbo is a Partner and Chief Scientist, and Bryan Richardson is an Associate Partner and Senior DataScientist, for QuantumBlack AI by McKinsey. They presented “Automating DataQuality Remediation With AI” at Snorkel AI’s The Future of Data-Centric AI Summit in 2022.
As the Internet of Things (IoT) continues to revolutionize industries and shape the future, datascientists play a crucial role in unlocking its full potential. A recent article on Analytics Insight explores the critical aspect of data engineering for IoT applications.
Jacomo Corbo is a Partner and Chief Scientist, and Bryan Richardson is an Associate Partner and Senior DataScientist, for QuantumBlack AI by McKinsey. They presented “Automating DataQuality Remediation With AI” at Snorkel AI’s The Future of Data-Centric AI Summit in 2022.
This guide unlocks the path from Data Analyst to DataScientist Architect. DataQuality and Standardization The adage “garbage in, garbage out” holds true. Inconsistent data formats, missing values, and data bias can significantly impact the success of large-scale Data Science projects.
It serves as the hub for defining and enforcing data governance policies, data cataloging, data lineage tracking, and managing data access controls across the organization. Data lake account (producer) – There can be one or more data lake accounts within the organization.
Follow five essential steps for success in making your data AI ready with data integration. Define clear goals, assess your data landscape, choose the right tools, ensure dataquality and governance, and continuously optimize your integration processes.
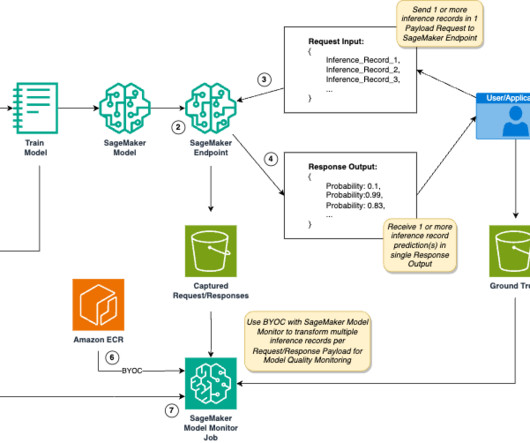
TWCo datascientists and ML engineers took advantage of automation, detailed experiment tracking, integrated training, and deployment pipelines to help scale MLOps effectively. The DataQuality Check part of the pipeline creates baseline statistics for the monitoring task in the inference pipeline.
However, as datascientists and engineering teams delve into the world of generative AI, it’s crucial to navigate through the hype and approach this cutting-edge technology with a clear strategy. DataQuality and Ethical Considerations The quality and quantity of data play a pivotal role in the success of generative AI models.
So, if a simple yes has convinced you, you can go straight to learning how to become a datascientist. But if you want to learn more about data science, today’s emerging profession that will shape your future, just a few minutes of reading can answer all your questions. In the corporate world, fast wins.
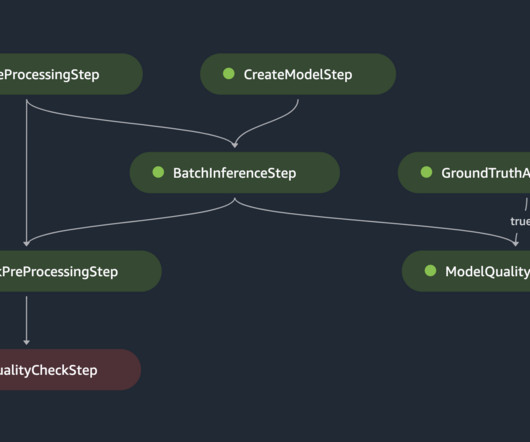
When a new version of the model is registered in the model registry, it triggers a notification to the responsible datascientist via Amazon SNS. If the batch inference pipeline discovers dataquality issues, it will notify the responsible datascientist via Amazon SNS.
Early and proactive detection of deviations in model quality enables you to take corrective actions, such as retraining models, auditing upstream systems, or fixing quality issues without having to monitor models manually or build additional tooling. DataScientist with AWS Professional Services. Raju Patil is a Sr.
By analyzing real-time data, this technique empowers airlines and maintenance teams to anticipate maintenance requirements and schedule necessary repairs before critical components malfunction. One of the primary concerns is the dataquality and reliability.
This reduces the reliance on manual data labeling and significantly speeds up the model training process. At its core, Snorkel Flow empowers datascientists and domain experts to encode their knowledge into labeling functions, which are then used to generate high-quality training datasets.
DataQuality and Privacy Concerns: AI models require high-qualitydata for training and accurate decision-making. Ensuring data privacy and security is vital, especially when handling sensitive user information.
This framework creates a central hub for feature management and governance with enterprise feature store capabilities, making it straightforward to observe the data lineage for each feature pipeline, monitor dataquality , and reuse features across multiple models and teams.
One such field is data labeling, where AI tools have emerged as indispensable assets. This process is important if you want to improve dataquality especially for artificial intelligence purposes. This article will discuss the influence of artificial intelligence and machine learning in data labeling. trillion by 2032.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content