This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Summary: Datasilos are isolated data repositories within organisations that hinder access and collaboration. Eliminating datasilos enhances decision-making, improves operational efficiency, and fosters a collaborative environment, ultimately leading to better customer experiences and business outcomes.
When companies work with data that is untrustworthy for any reason, it can result in incorrect insights, skewed analysis, and reckless recommendations to become data integrity vs dataquality. Two terms can be used to describe the condition of data: data integrity and dataquality.
Businesses face significant hurdles when preparing data for artificial intelligence (AI) applications. The existence of datasilos and duplication, alongside apprehensions regarding dataquality, presents a multifaceted environment for organizations to manage.
Poor dataquality is one of the top barriers faced by organizations aspiring to be more data-driven. Ill-timed business decisions and misinformed business processes, missed revenue opportunities, failed business initiatives and complex data systems can all stem from dataquality issues.
Within the Data Management industry, it’s becoming clear that the old model of rounding up massive amounts of data, dumping it into a data lake, and building an API to extract needed information isn’t working. The post Why Graph Databases Are an Essential Choice for Master Data Management appeared first on DATAVERSITY.
Insights from data gathered across business units improve business outcomes, but having heterogeneous data from disparate applications and storages makes it difficult for organizations to paint a big picture. How can organizations get a holistic view of data when it’s distributed across datasilos?
As they do so, access to traditional and modern data sources is required. Poor dataquality and information silos tend to emerge as early challenges. Customer dataquality, for example, tends to erode very quickly as consumers experience various life changes.
Organizations require reliable data for robust AI models and accurate insights, yet the current technology landscape presents unparalleled dataquality challenges, specifically as the growth of data spans multiple formats: structured, semistructured and unstructured.
Minimize data input The less data that you have going into ETL process, the faster and cleaner your results are likely to be. That’s why you want to strip out any unnecessary data as early in the ETL process as possible. Maximize dataquality The old saying “crap in, crap out” applies to ETL integration.
It’s on Data Governance Leaders to identify the issues with the business process that causes users to act in these ways. Inconsistencies in expectations can create enormous negative issues regarding dataquality and governance. Roadblock #3: Silos Breed Misunderstanding. Picking the Right Data Governance Tools.
Open is creating a foundation for storing, managing, integrating and accessing data built on open and interoperable capabilities that span hybrid cloud deployments, data storage, data formats, query engines, governance and metadata.
As companies strive to leverage AI/ML, location intelligence, and cloud analytics into their portfolio of tools, siloed mainframe data often stands in the way of forward momentum. Insufficient skills, limited budgets, and poor dataquality also present significant challenges. To learn more, read our ebook.
Organizations require reliable data for robust AI models and accurate insights, yet the current technology landscape presents unparalleled dataquality challenges. This situation will exacerbate datasilos, increase costs and complicate the governance of AI and data workloads.
Understanding Data Integration in Data Mining Data integration is the process of combining data from different sources. Thus creating a consolidated view of the data while eliminating datasilos. It involves mapping and transforming data elements to align with a unified schema.
Duration of data informs on long-term variations and patterns in the dataset that would otherwise go undetected and lead to biased and ill-informed predictions. Breaking down these datasilos to unite the untapped potential of the scattered data can save and transform many lives. Much of this work comes down to the data.”
A data mesh is a decentralized approach to data architecture that’s been gaining traction as a solution to the challenges posed by large and complex data ecosystems. It’s all about breaking down datasilos, empowering domain teams to take ownership of their data, and fostering a culture of data collaboration.
This requires access to data from across business systems when they need it. Datasilos and slow batch delivery of data will not do. Stale data and inconsistencies can distort the perception of what is really happening in the business leading to uncertainty and delay.
By employing ETL, businesses ensure that their data is reliable, accurate, and ready for analysis. This process is essential in environments where data originates from various systems, such as databases , applications, and web services. The key is to ensure that all relevant data is captured for further processing.
What Is Data Lake? A Data Lake is a centralized repository that allows businesses to store vast volumes of structured and unstructured data at any scale. Unlike traditional databases, Data Lakes enable storage without the need for a predefined schema, making them highly flexible.
Data governance and security Like a fortress protecting its treasures, data governance, and security form the stronghold of practical Data Intelligence. Think of data governance as the rules and regulations governing the kingdom of information. It ensures dataquality , integrity, and compliance.
Here are four aspects of a data management approach that you should consider to increase the success of an architecture: Break down datasilos by automating the integration of essential data – from legacy mainframes and midrange systems, databases, apps, and more – into your logical data warehouse or data lake.
Implementing Generative AI can be difficult as there are some hurdles to overcome for any business to get up and running: DataQuality You get the same quality output as the data you use for any AI system, so having accurate and unbiased data is of the utmost importance.
A 2019 survey by McKinsey on global data transformation revealed that 30 percent of total time spent by enterprise IT teams was spent on non-value-added tasks related to poor dataquality and availability. The data lake can then refine, enrich, index, and analyze that data.
These pipelines assist data scientists in saving time and effort by ensuring that the data is clean, properly formatted, and ready for use in machine learning tasks. Moreover, ETL pipelines play a crucial role in breaking down datasilos and establishing a single source of truth.
Here, we have highlighted the concerning issues like usability, dataquality, and clinician trust. DataQuality The accuracy of CDSS recommendations hinges on the quality of patient data fed into the system. This can create datasilos and hinder the flow of information within a healthcare organization.
. “ This sounds great in theory, but how does it work in practice with customer data or something like a ‘composable CDP’? Well, implementing transitional modeling does require a shift in how we think about and work with customer data. It often involves specialized databases designed to handle this kind of atomic, temporal data.
Although organizations don’t set out to intentionally create datasilos, they are likely to arise naturally over time. This can make collaboration across departments difficult, leading to inconsistent dataquality , a lack of communication and visibility, and higher costs over time (among other issues). Technology.
They’re where the world’s transactional data originates – and because that essential data can’t remain siloed, organizations are undertaking modernization initiatives to provide access to mainframe data in the cloud. That approach assumes that good dataquality will be self-sustaining.
Enhanced Collaboration: dbt Mesh fosters a collaborative environment by using cross-project references, making it easy for teams to share, reference, and build upon each other’s work, eliminating the risk of datasilos. Deploy jobs are designed to build into production databases, running sequentially to prevent conflicts.
Data producers and consumers alike are working from home and hybrid locations more often. And in an increasingly remote workforce, people need to access data systems easily to do their jobs. This might mean that they’re accessing a database from a smartphone, computer, or tablet. Today, data dwells everywhere.
Creating data observability routines to inform key users of any changes or exceptions that crop up within the data, enabling a more proactive approach to compliance. Regulations like GDPR and CCPA, for example, require institutions to permit their customers to remove select types of personal information from internal databases.
Through this unified query capability, you can create comprehensive insights into customer transaction patterns and purchase behavior for active products without the traditional barriers of datasilos or the need to copy data between systems. You will see a new database dev@ in the managed Amazon Redshift Serverless workgroup.
Establishing a data culture changes this paradigm. Data pipelines are standardized to ingest data to Snowflake to provide consistency and maintainability. Data transformation introduces dataquality rules, such as with dbt or Matillion, to establish trust that data is ready for consumption.
Data ingestion Data ingestion involves collecting various forms of datastructured, unstructured, and semi-structuredfrom multiple sources. This can include data at rest, such as databases, and data in motion, like live streaming data from IoT devices.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















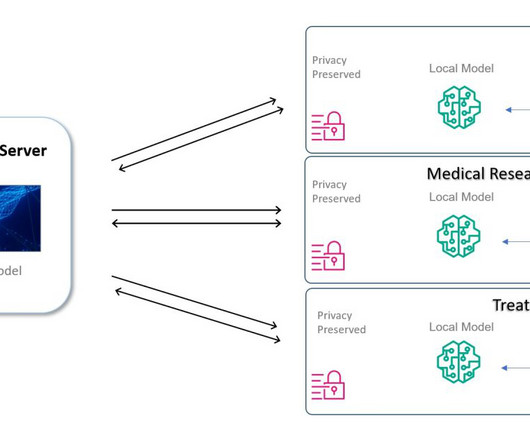






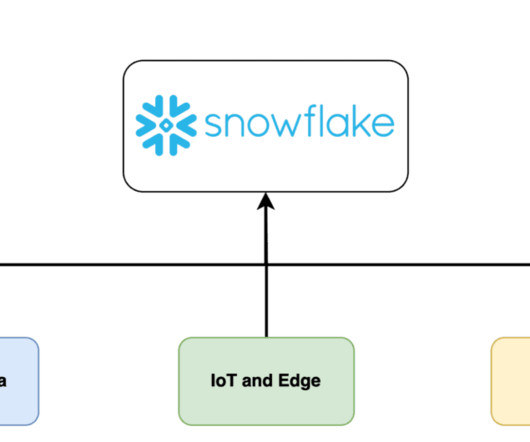










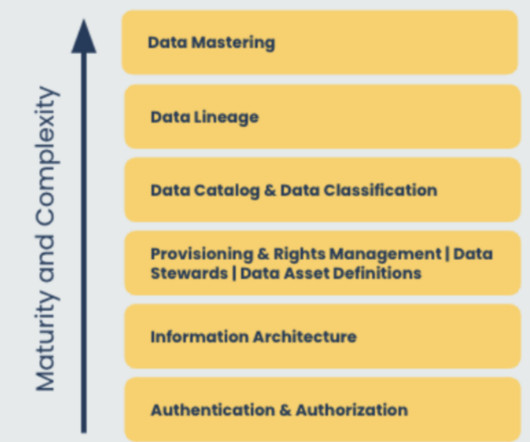







Let's personalize your content