This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Summary: Datasilos are isolated data repositories within organisations that hinder access and collaboration. Eliminating datasilos enhances decision-making, improves operational efficiency, and fosters a collaborative environment, ultimately leading to better customer experiences and business outcomes.
True dataquality simplification requires transformation of both code and data, because the two are inextricably linked. Code sprawl and datasiloing both imply bad habits that should be the exception, rather than the norm.
Summary: Dataquality is a fundamental aspect of MachineLearning. Poor-qualitydata leads to biased and unreliable models, while high-qualitydata enables accurate predictions and insights. What is DataQuality in MachineLearning?
By analyzing their data, organizations can identify patterns in sales cycles, optimize inventory management, or help tailor products or services to meet customer needs more effectively. The company aims to integrate additional data sources, including other mission-critical systems, into ODAP.
This post is part of an ongoing series about governing the machinelearning (ML) lifecycle at scale. This post dives deep into how to set up data governance at scale using Amazon DataZone for the data mesh. Data lake account (producer) – There can be one or more data lake accounts within the organization.
Be sure to check out her talk, “ Power trusted AI/ML Outcomes with Data Integrity ,” there! Due to the tsunami of data available to organizations today, artificial intelligence (AI) and machinelearning (ML) are increasingly important to businesses seeking competitive advantage through digital transformation.
Almost half of AI projects are doomed by poor dataquality, inaccurate or incomplete data categorization, unstructured data, and datasilos. Avoid these 5 mistakes
Technology helped to bridge the gap, as AI, machinelearning, and data analytics drove smarter decisions, and automation paved the way for greater efficiency. AI and machinelearning initiatives play an increasingly important role. As they do so, access to traditional and modern data sources is required.
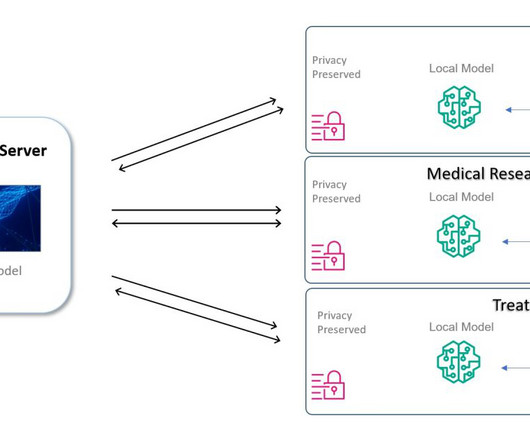
Medical data restrictions You can use machinelearning (ML) to assist doctors and researchers in diagnosis tasks, thereby speeding up the process. However, the datasets needed to build the ML models and give reliable results are sitting in silos across different healthcare systems and organizations.
Without a doubt, no company can achieve lasting profitability and sustainable growth with a poorly constructed data governance methodology. Today, all companies must pursue data analytics, MachineLearning & Artificial Intelligence (ML & AI) as an integral part of any standard business plan.
They shore up privacy and security, embrace distributed workforce management, and innovate around artificial intelligence and machinelearning-based automation. The key to success within all of these initiatives is high-integrity data. Only 46% of respondents rate their dataquality as “high” or “very high.”
In 2024 organizations will increasingly turn to third-party data and spatial insights to augment their training and reference data for the most nuanced, coherent, and contextually relevant AI output. When it comes to AI outputs, results will only be as strong as the data that’s feeding them.
Key Takeaways: Trusted AI requires data integrity. For AI-ready data, focus on comprehensive data integration, dataquality and governance, and data enrichment. Building data literacy across your organization empowers teams to make better use of AI tools. The impact? The stakes are very high.
Access to high-qualitydata can help organizations start successful products, defend against digital attacks, understand failures and pivot toward success. Emerging technologies and trends, such as machinelearning (ML), artificial intelligence (AI), automation and generative AI (gen AI), all rely on good dataquality.
Innovators in the industry understand that leading-edge technologies such as AI and machinelearning will be a deciding factor in the quest for competitive advantage when moving to the cloud. To learn more, read our ebook. Insufficient skills, limited budgets, and poor dataquality also present significant challenges.
She started as a Web Analyst and Online Marketing Manager, and discovered her passion for data, Big Data, data science and machinelearning. She goes on to explain the one of the most beneficial features of One Data’s enabling technology, One Data Cartography , is record linkage combined with dataquality.
Financial institutions are using data in a myriad of different ways, from know-your-customer (KYC) compliance to marketing insights and channel optimization, from risk assessment and fraud detection to innovative AI and machinelearning initiatives. This post examines the practical implications of poor data integrity.
You need to break down datasilos and integrate critical data from all relevant sources into Amazon Web Services (AWS). Fuel your AI applications with trusted data to power reliable results. You’re not alone. This ensures your AI models can access a comprehensive dataset, minimizing bias and enhancing accuracy.
While use cases may vary, each success story shares a common foundation: data integrity. Whether it’s making personalized recommendations, automating complex workflows, or training machinelearning models, the accuracy, consistency, and context of your data determine the effectiveness of your AI solutions.
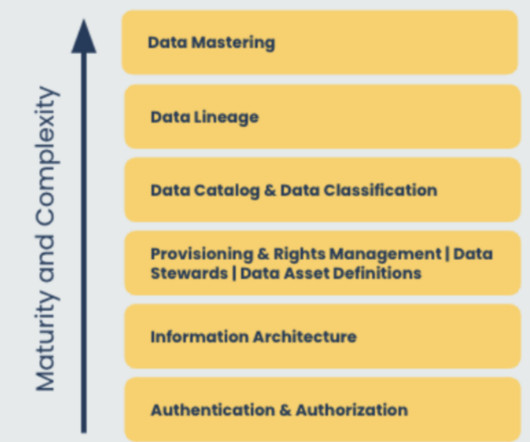
How is the data architecture role evolving? As data governance gains importance, data architects must work with data stewards and owners to establish policies, develop governance frameworks, implement dataquality programs, and provide guidance to other data professionals.
Creating data observability routines to inform key users of any changes or exceptions that crop up within the data, enabling a more proactive approach to compliance. Doing so requires comprehensive dataquality and data governance programs that help you clearly understand who you’re dealing with. Intelligence.
Here are some of the key trends and challenges facing telecommunications companies today: The growth of AI and machinelearning: Telecom companies use artificial intelligence and machinelearning (AI/ML) for predictive analytics and network troubleshooting.
Imagine this: we collect loads of data, right? Data Intelligence takes that data, adds a touch of AI and MachineLearning magic, and turns it into insights. It’s not just about having data; it’s about turning that data into real wisdom for better products and services. These insights?
What is data fabric Data fabric is a data management architecture that allows you to break down datasilos, improve efficiencies, and accelerate access for users. It provides a unified and consistent data infrastructure across distributed environments, accelerating analytics and decision-making.
While this industry has used data and analytics for a long time, many large travel organizations still struggle with datasilos , which prevent them from gaining the most value from their data. What is big data in the travel and tourism industry?
Modern data governance relies on automation, which reduces costs. Automated tools make data governance processes very cost-effective. Machinelearning plays a key role, as it can increase the speed and accuracy of metadata capture and categorization. This empowers leaders to see and refine human processes around data.
This requires access to data from across business systems when they need it. Datasilos and slow batch delivery of data will not do. Stale data and inconsistencies can distort the perception of what is really happening in the business leading to uncertainty and delay.
Ensures consistent, high-qualitydata is readily available to foster innovation and enable you to drive competitive advantage in your markets through advanced analytics and machinelearning. You must be able to continuously catalog, profile, and identify the most frequently used data. Increase metadata maturity.
Often the Data Team, comprising Data and ML Engineers , needs to build this infrastructure, and this experience can be painful. We also discuss different types of ETL pipelines for ML use cases and provide real-world examples of their use to help data engineers choose the right one. fillna( iris_transform_df[cols].mean())
Insights Gathering insight from consumer information is one of the top data challenges modern retailers face. Around 90% of all data is unstructured. While tools like machinelearning technology can process it, visualizing it can still be complex. It’s generally more challenging to manage with traditional approaches.
What Is Data Governance In The Public Sector? Effective data governance for the public sector enables entities to ensure dataquality, enhance security, protect privacy, and meet compliance requirements. With so much focus on compliance, democratizing data for self-service analytics can present a challenge.
Businesses face significant hurdles when preparing data for artificial intelligence (AI) applications. The existence of datasilos and duplication, alongside apprehensions regarding dataquality, presents a multifaceted environment for organizations to manage.
Data now comes from so many sources that integrating, cleaning, and transforming it across systems is difficult. Dataquality problems cause low productivity, inefficiency, high costs, and errors in decision-making. Many organizations are turning to active data governance to minimize the burden of governance tasks.
In the past, businesses would collect data, run analytics, and extract insights, which would inform strategy and decision-making. Nowadays, machinelearning , AI, and augmented reality analytics are speeding up this process, so that collection and analysis are always on. Evaluate and monitor dataquality.
Summary: AIOps leverages AI and MachineLearning to automate IT tasks, identify anomalies, and predict problems. Learn how to implement AIOps in your organization! It utilizes MachineLearning (ML) and other AI techniques to streamline IT processes, improve efficiency, and free up valuable time for IT professionals.
What is Data Mesh? Data Mesh is a new data set that enables units or cross-functional teams to decentralize and manage their data domains while collaborating to maintain dataquality and consistency across the organization — architecture and governance approach. We can call fabric texture or actual fabric.
Data as the foundation of what the business does is great – but how do you support that? What technology or platform can meet the needs of the business, from basic report creation to complex document analysis to machinelearning workflows? The Snowflake AI Data Cloud is the platform that will support that and much more!
This centralization streamlines data access, facilitating more efficient analysis and reducing the challenges associated with siloed information. With all data in one place, businesses can break down datasilos and gain holistic insights.
Enhanced Collaboration: dbt Mesh fosters a collaborative environment by using cross-project references, making it easy for teams to share, reference, and build upon each other’s work, eliminating the risk of datasilos. The semantic models are defined in the model’s.yml configuration file.
Looking to build a machine-learning model for churn prediction? The atomic data provides a perfect input, capturing the full richness of customer behavior over time. DataQuality Management : Persistent staging provides a clear demarcation between raw and processed customer data. Just plug it in!
Through this unified query capability, you can create comprehensive insights into customer transaction patterns and purchase behavior for active products without the traditional barriers of datasilos or the need to copy data between systems. He loves spending time with his family and friends.
Continuous intelligence is the real-time analysis and processing of data streams to enable automated decision-making and insights. It integrates artificial intelligence, machinelearning, and analytics to provide dynamic responses, often used in fraud detection, IoT monitoring, and operational optimization.
By leveraging GenAI, businesses can personalize customer experiences and improve dataquality while maintaining privacy and compliance. Introduction Generative AI (GenAI) is transforming Data Analytics by enabling organisations to extract deeper insights and make more informed decisions.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content