This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In this blog, we explore how the introduction of SQL Asset Type enhances the metadata enrichment process within the IBM Knowledge Catalog , enhancing data governance and consumption. It enables organizations to seamlessly access and utilize data assets irrespective of their location or format.
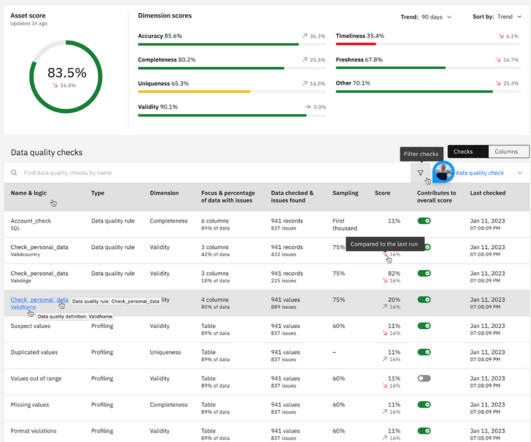
Poor dataquality is one of the top barriers faced by organizations aspiring to be more data-driven. Ill-timed business decisions and misinformed business processes, missed revenue opportunities, failed business initiatives and complex data systems can all stem from dataquality issues.
Organizations require reliable data for robust AI models and accurate insights, yet the current technology landscape presents unparalleled dataquality challenges. This situation will exacerbate datasilos, increase costs and complicate the governance of AI and data workloads.
Open is creating a foundation for storing, managing, integrating and accessing data built on open and interoperable capabilities that span hybrid cloud deployments, data storage, data formats, query engines, governance and metadata. Effective dataquality management is crucial to mitigating these risks.
This phase is crucial for enhancing dataquality and preparing it for analysis. Transformation involves various activities that help convert raw data into a format suitable for reporting and analytics. Normalisation: Standardising data formats and structures, ensuring consistency across various data sources.
Businesses face significant hurdles when preparing data for artificial intelligence (AI) applications. The existence of datasilos and duplication, alongside apprehensions regarding dataquality, presents a multifaceted environment for organizations to manage.
This centralization streamlines data access, facilitating more efficient analysis and reducing the challenges associated with siloed information. With all data in one place, businesses can break down datasilos and gain holistic insights.
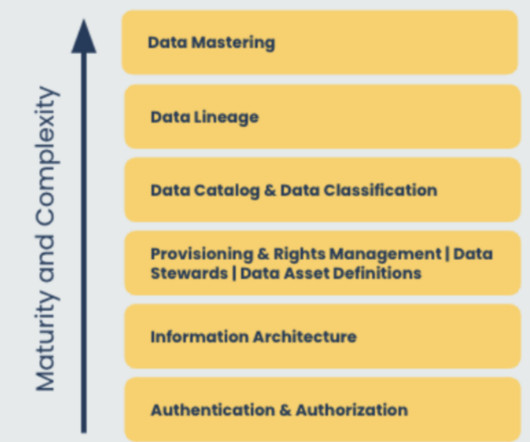
Data governance and security Like a fortress protecting its treasures, data governance, and security form the stronghold of practical Data Intelligence. Think of data governance as the rules and regulations governing the kingdom of information. It ensures dataquality , integrity, and compliance.
A 2019 survey by McKinsey on global data transformation revealed that 30 percent of total time spent by enterprise IT teams was spent on non-value-added tasks related to poor dataquality and availability. The data lake can then refine, enrich, index, and analyze that data. Tell me more about ECL.
Some modern CDPs are starting to incorporate these concepts, allowing for more flexible and evolving customer data models. It also requires a shift in how we query our customer data. Instead of simple SQL queries, we often need to use more complex temporal query languages or rely on derived views for simpler querying.
By analyzing their data, organizations can identify patterns in sales cycles, optimize inventory management, or help tailor products or services to meet customer needs more effectively. This tool democratizes data access across the organization, enabling even nontechnical users to gain valuable insights.
Through this unified query capability, you can create comprehensive insights into customer transaction patterns and purchase behavior for active products without the traditional barriers of datasilos or the need to copy data between systems. For the simplicity, we chose the SQL analytics project profile.
Enhanced Collaboration: dbt Mesh fosters a collaborative environment by using cross-project references, making it easy for teams to share, reference, and build upon each other’s work, eliminating the risk of datasilos.
What Is Data Governance In The Public Sector? Effective data governance for the public sector enables entities to ensure dataquality, enhance security, protect privacy, and meet compliance requirements. With so much focus on compliance, democratizing data for self-service analytics can present a challenge.
Establishing a data culture changes this paradigm. Data pipelines are standardized to ingest data to Snowflake to provide consistency and maintainability. Data transformation introduces dataquality rules, such as with dbt or Matillion, to establish trust that data is ready for consumption.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




















Let's personalize your content