This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In this contributed article, editorial consultant Jelani Harper discusses a number of hot topics today: computer vision, dataquality, and spatial data. Computer vision is an extremely viable facet of advanced machine learning for the enterprise. Its utility for dataquality is evinced from some high profile use cases.
This article was published as a part of the Data Science Blogathon. Introduction In deeplearning, the activation functions are one of the essential parameters in training and building a deeplearning model that makes accurate predictions.
In this contributed article, Stephany Lapierre, Founder and CEO of Tealbook, discusses how AI can help streamline procurement processes, reduce costs and improve supplier management, while also addressing common concerns and challenges related to AI implementation like data privacy, ethical considerations and the need for human oversight.
Summary: Autoencoders are powerful neural networks used for deeplearning. They compress input data into lower-dimensional representations while preserving essential features. Their applications include dimensionality reduction, feature learning, noise reduction, and generative modelling. Let’s dive in!
iMerit, a leading artificial intelligence (AI) data solutions company, released its 2023 State of ML Ops report, which includes a study outlining the impact of data on wide-scale commercial-ready AI projects.
Just like a skyscraper’s stability depends on a solid foundation, the accuracy and reliability of your insights rely on top-notch dataquality. Enter Generative AI – a game-changing technology revolutionizing data management and utilization. Businesses must ensure their data is clean, structured, and reliable.
Deeplearning models are typically highly complex. While many traditional machine learning models make do with just a couple of hundreds of parameters, deeplearning models have millions or billions of parameters. The reasons for this range from wrongly connected model components to misconfigured optimizers.
In this contributed article, Kim Stagg, VP of Product for Appen, knows the only way to achieve functional AI models is to use high-qualitydata in every stage of deployment.
Deeplearning technology is changing the future of small businesses around the world. A growing number of small businesses are using deeplearning technology to address some of their most pressing challenges. New advances in deeplearning are integrated into various accounting algorithms.
Dropout in deeplearning In deeplearning, dropout is a regularization technique where random neurons are excluded during training. This process encourages the model to learn robust features that are not reliant on any single neuron, thereby improving generalization.
] High-qualitydata is the fuel for modern datadeeplearning model training. Most of task-specific labeled data comes from human annotation, such as classification task or RLHF labeling (which can be constructed as classification format) for LLM alignment training.
Quantitative evaluation shows superior performance of biophysical motivated synthetic training data, even outperforming manual annotation and pretrained models. This underscores the potential of incorporating biophysical modeling for enhancing synthetic training dataquality.
Deeplearning is a branch of machine learning that makes use of neural networks with numerous layers to discover intricate data patterns. Deeplearning models use artificial neural networks to learn from data. It is a tremendous tool with the ability to completely alter numerous sectors.
Summary : DeepLearning engineers specialise in designing, developing, and implementing neural networks to solve complex problems. Introduction DeepLearning engineers are specialised professionals who design, develop, and implement DeepLearning models and algorithms.
Neuron is the SDK used to run deeplearning workloads on Trainium and Inferentia based instances. This data makes sure models are being trained smoothly and reliably. If failures increase, it may signal issues with dataquality, model configurations, or resource limitations that need to be addressed.
As such, the quality of their data can make or break the success of the company. This article will guide you through the concept of a dataquality framework, its essential components, and how to implement it effectively within your organization. What is a dataquality framework?
Dataquality control: Robust dataset labeling and annotation tools incorporate quality control mechanisms such as inter-annotator agreement analysis, review workflows, and data validation checks to ensure the accuracy and reliability of annotations. Data monitoring tools help monitor the quality of the data.
Object detection works by using machine learning or deeplearning models that learn from many examples of images with objects and their labels. In the early days of machine learning, this was often done manually, with researchers defining features (e.g., Object detection is useful for many applications (e.g.,
Earlier today, one analysis found that the market size for deeplearning was worth $51 billion in 2022 and it will grow to be worth $1.7 One such field is data labeling, where AI tools have emerged as indispensable assets. trillion by 2032.
In quality control, an outlier could indicate a defect in a manufacturing process. By understanding and identifying outliers, we can improve dataquality, make better decisions, and gain deeper insights into the underlying patterns of the data. Thakur, eds., Join the Newsletter!
Over the past decade, deeplearning arose from a seismic collision of data availability and sheer compute power, enabling a host of impressive AI capabilities. Data: the foundation of your foundation model Dataquality matters. Data curation is a task that’s never truly finished.
Navigating Nemotron to Generate Synthetic Data LLMs can help developers generate synthetic training data in scenarios where access to large, diverse labeled datasets is limited. Then, to boost the quality of the AI-generated data, developers can use the Nemotron-4 340B Reward model to filter for high-quality responses.
After confirming that the dataquality is acceptable, we go back to the data flow and use Data Wrangler’s DataQuality and Insights Report. Refer to Get Insights On Data and DataQuality for more information. Choose the plus sign next to Data types , then choose Add analysis.
MLOps facilitates automated testing mechanisms for ML models, which detects problems related to model accuracy, model drift, and dataquality. Data collection and preprocessing The first stage of the ML lifecycle involves the collection and preprocessing of data.
What are the biggest challenges in machine learning? select all that apply) Related to the previous question, these are a few issues faced in machine learning. Some of the issues make perfect sense as they relate to dataquality, with common issues being bad/unclean data and data bias.
As we have already said, the challenge for companies is to extract value from data, and to do so it is necessary to have the best visualization tools. Over time, it is true that artificial intelligence and deeplearning models will be help process these massive amounts of data (in fact, this is already being done in some fields).
Amazon SageMaker Ground Truth is a powerful data labeling service offered by AWS that provides a comprehensive and scalable platform for labeling various types of data, including text, images, videos, and 3D point clouds, using a diverse workforce of human annotators. Rejected objects go back to annotators to re-label.
Limitations: Bias and interpretability: Machine learning algorithms may reflect biases present in the data used to train them, and it may be challenging to interpret how they arrived at their decisions. RPA can be used to automate data entry and data management processes, reducing the risk of errors and improving dataquality.
This monitoring requires robust data management and processing infrastructure. Data Velocity: High-velocity data streams can quickly overwhelm monitoring systems, leading to latency and performance issues. We’re committed to supporting and inspiring developers and engineers from all walks of life.
Summary: Artificial Intelligence (AI) is revolutionising Genomic Analysis by enhancing accuracy, efficiency, and data integration. Techniques such as Machine Learning and DeepLearning enable better variant interpretation, disease prediction, and personalised medicine.
Machine Learning (ML) is a game-changer in this regard, but its effective implementation requires adherence to best practices. Data Management and Preprocessing for Accurate Predictions DataQuality is Paramount: The foundation of robust ML in demand forecasting lies in high-qualitydata.
Making Data Observable Bigeye The quality of the data powering your machine learning algorithms should not be a mystery. Bigeye’s data observability platform helps data science teams “measure, improve, and communicate dataquality at any scale.”
Thinking about High-Quality Human Data High-quality, detailed human annotations are crucial for creating effective deeplearning models, ensuring AI accuracy through tasks such as content classification and language model alignment. This article shared the practices and techniques for improving dataquality.
The application of machine learning in asset pricing is becoming increasingly popular in the finance industry, as it allows for more accurate valuations and informed investment decisions Challenges in implementing machine learning in asset pricing Dataquality: Machine learning algorithms rely on high-qualitydata to make accurate predictions.
When it comes to deeplearning models, that are often used for more complex problems and sequential data, Long Short-Term Memory (LSTM) networks or Transformers are applied. Moreover, random forest models as well as support vector machines (SVMs) are also frequently applied.
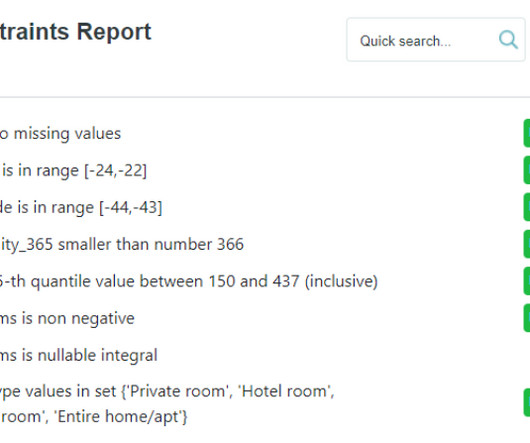
Let’s download the dataframe with: import pandas as pd df_target = pd.read_parquet("[link] /Listings/airbnb_listings_target.parquet") Let’s simulate a scenario where we want to assert the quality of a batch of production data. These constraints operate on top of statistical summaries of data, rather than on the raw data itself.
For instance, if a business prioritizes accuracy in generating synthetic data, the resulting output may inadvertently include too many personally identifiable attributes, thereby increasing the company’s privacy risk exposure unknowingly.
Summary: This guide explores Artificial Intelligence Using Python, from essential libraries like NumPy and Pandas to advanced techniques in machine learning and deeplearning. TensorFlow and Keras: TensorFlow is an open-source platform for machine learning.
Skills like effective verbal and written communication will help back up the numbers, while data visualization (specific frameworks in the next section) can help you tell a complete story. Data Wrangling: DataQuality, ETL, Databases, Big Data The modern data analyst is expected to be able to source and retrieve their own data for analysis.
With advances in machine learning, deeplearning, and natural language processing, the possibilities of what we can create with AI are limitless. Collect and preprocess data for AI development. Develop AI models using machine learning or deeplearning algorithms.
Dataquality AI algorithms rely on accurate and high-qualitydata to make informed decisions. However, dataquality can be a significant challenge in accounting, particularly when dealing with unstructured data sources such as invoices and receipts.
However, as the size and complexity of the deeplearning models that power generative AI continue to grow, deployment can be a challenging task. Then, we highlight how Amazon SageMaker large model inference deeplearning containers (LMI DLCs) can help with optimization and deployment.
Image and Signal Processing: In medical imaging and signal processing, data scientists and machine learning engineers employ advanced algorithms to extract valuable information from images, such as CT scans, MRIs, and EKGs. However, ensuring dataquality can be a significant challenge.
Computational Costs : Analyzing vast and complex genomic data requires substantial computational resources, making it expensive and time-consuming. DataQuality : Ensuring the accuracy and reliability of sequencing data is crucial.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content