This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
generally available on May 24, Alation introduces the Open DataQuality Initiative for the modern data stack, giving customers the freedom to choose the dataquality vendor that’s best for them with the added confidence that those tools will integrate seamlessly with Alation’s Data Catalog and Data Governance application.
Here are some effective strategies to break down data silos: Data Integration Solutions Employing tools for data integration such as Extract, Transform, Load (ETL) processes can help consolidate data from various sources into a single repository. This allows for easier access and analysis across departments.
The magic of the data warehouse was figuring out how to get data out of these transactional systems and reorganize it in a structured way optimized for analysis and reporting. But those end users werent always clear on which data they should use for which reports, as the datadefinitions were often unclear or conflicting.
Summary: Choosing the right ETL tool is crucial for seamless data integration. Top contenders like Apache Airflow and AWS Glue offer unique features, empowering businesses with efficient workflows, high dataquality, and informed decision-making capabilities. Also Read: Top 10 Data Science tools for 2024.
An example direct acyclic graph (DAG) might automate data ingestion, processing, model training, and deployment tasks, ensuring that each step is run in the correct order and at the right time. Though it’s worth mentioning that Airflow isn’t used at runtime as is usual for extract, transform, and load (ETL) tasks.
Understanding Data Lakes A data lake is a centralized repository that stores structured, semi-structured, and unstructured data in its raw format. Unlike traditional data warehouses or relational databases, data lakes accept data from a variety of sources, without the need for prior data transformation or schema definition.
Let’s delve into the key components that form the backbone of a data warehouse: Source Systems These are the operational databases, CRM systems, and other applications that generate the raw data feeding the data warehouse. Data Extraction, Transformation, and Loading (ETL) This is the workhorse of architecture.
Additionally, it addresses common challenges and offers practical solutions to ensure that fact tables are structured for optimal dataquality and analytical performance. Introduction In today’s data-driven landscape, organisations are increasingly reliant on Data Analytics to inform decision-making and drive business strategies.
These pipelines automate collecting, transforming, and delivering data, crucial for informed decision-making and operational efficiency across industries. Tools such as Python’s Pandas library, Apache Spark, or specialised data cleaning software streamline these processes, ensuring data integrity before further transformation.
Document Hierarchy Structures Maintain thorough documentation of hierarchy designs, including definitions, relationships, and data sources. DataQuality Issues Inconsistent or incomplete data can hinder the effectiveness of hierarchies. Avoid excessive levels that may slow down query performance.
For small-scale/low-value deployments, there might not be many items to focus on, but as the scale and reach of deployment go up, data governance becomes crucial. This includes dataquality, privacy, and compliance. If you aren’t aware already, let’s introduce the concept of ETL. Redshift, S3, and so on.
Catalog Enhanced data trust, visibility, and discoverability Tableau Catalog automatically catalogs all your data assets and sources into one central list and provides metadata in context for fast data discovery. Included with Data Management. Using geo hierarchies, you can go deeper into your data and find new insights.
I used a demo project that I frequently work with and introduced syntax errors and dataquality problems. This can be done by updating the contract definition to include this column and ensuring that the name, data type, and number of columns in the contract match the columns in the model’s definition.
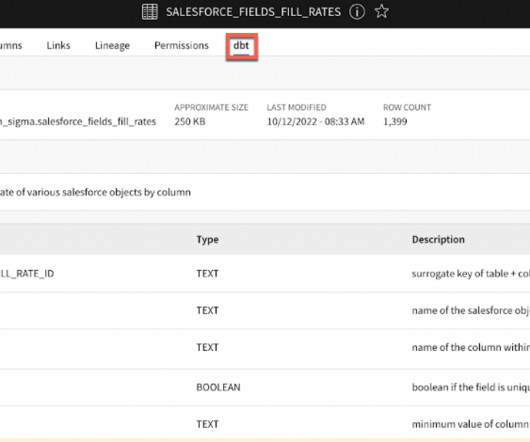
Now that your data is loaded in using dbt, one can see the data displayed in Sigma itself, allowing the user to verify how up-to-date their data is. DataQuality View dbt quality tests on columns and models, providing precision and transparency into your dataquality questions and concerns – What a relief.
Account A is the data lake account that houses all the ML-ready data obtained through extract, transform, and load (ETL) processes. Account B is the data science account where a group of data scientists compile and run data transformations using SageMaker Data Wrangler. compute.internal.
Data fabric is now on the minds of most data management leaders. In our previous blog, Data Mesh vs. Data Fabric: A Love Story , we defined data fabric and outlined its uses and motivations. The data catalog is a foundational layer of the data fabric. Alation Data Catalog for the data fabric.
At a high level, we are trying to make machine learning initiatives more human capital efficient by enabling teams to more easily get to production and maintain their model pipelines, ETLs, or workflows. To a junior data scientist, it doesn’t matter if you’re using Airflow, Prefect , Dexter. I term it as a feature definition store.
Slow Response to New Information: Legacy data systems often lack the computation power necessary to run efficiently and can be cost-inefficient to scale. This typically results in long-running ETL pipelines that cause decisions to be made on stale or old data. Read more here.
Here are some challenges you might face while managing unstructured data: Storage consumption: Unstructured data can consume a large volume of storage. For instance, if you are working with several high-definition videos, storing them would take a lot of storage space, which could be costly. Unstructured.io
You don’t need massive data sets because “dataquality scales better than data size.” ” Small models with good data are better than massive models because “in the long run, the best models are the ones which can be iterated upon quickly.”
Traditionally, answering this question would involve multiple data exports, complex extract, transform, and load (ETL) processes, and careful data synchronization across systems. Users can write data to managed RMS tables using Iceberg APIs, Amazon Redshift, or Zero-ETL ingestion from supported data sources.
They offer a range of features and integrations, so the choice depends on factors like the complexity of your data pipeline, requirements for connections to other services, user interface, and compatibility with any ETL software already in use. Proper error handling enhances the resilience and reliability of your data pipeline.
If the event log is your customer’s diary, think of persistent staging as their scrapbook – a place where raw customer data is collected, organized, and kept for future reference. In traditional ETL (Extract, Transform, Load) processes in CDPs, staging areas were often temporary holding pens for data.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.





























Let's personalize your content