This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Businesses are under pressure to show return on investment (ROI) from AI use cases, whether predictive machine learning (ML) or generative AI. Only 54% of ML prototypes make it to production, and only 5% of generative AI use cases make it to production. Using SageMaker, you can build, train and deploy ML models.
generally available on May 24, Alation introduces the Open DataQuality Initiative for the modern data stack, giving customers the freedom to choose the dataquality vendor that’s best for them with the added confidence that those tools will integrate seamlessly with Alation’s Data Catalog and Data Governance application.
This is the first one, where we look at some functions for dataquality checks, which are the initial steps I take in EDA. We will use this table to demo and test our custom functions. Let’s get started. 🤠 🔗 All code and config are available on GitHub. The three functions below are created for this purpose. .")
Alignment to other tools in the organization’s tech stack Consider how well the MLOps tool integrates with your existing tools and workflows, such as data sources, data engineering platforms, code repositories, CI/CD pipelines, monitoring systems, etc. and Pandas or Apache Spark DataFrames.
These vary from challenges in getting data, maintaining various data forms and kinds, and coping with inconsistent dataquality to the crucial need for current information. – Application layer: This layer emphasizes the potential of FinGPT in the financial industry by showcasing real-world applications and demos.
We are excited to announce the launch of Amazon DocumentDB (with MongoDB compatibility) integration with Amazon SageMaker Canvas , allowing Amazon DocumentDB customers to build and use generative AI and machine learning (ML) solutions without writing code. On the Import data page, for Data Source , choose DocumentDB and Add Connection.
Boost engagement and adoptionwith integrated, persona-based insights access tailored, role-specific dataquality scores, technical details, and relationships at-a-glance. Enhanced Data Catalog With new visual card views, you gain automated dataquality scores, technical details, and tailored information for different roles.
Building a demo is one thing; scaling it to production is an entirely different beast. It has already inspired me to set new goals for 2025, and I hope it can do the same for other ML engineers. They also inspired a bunch of new potentials for ML engineers. Everything changed when Deepseek burst onto the scene a month ago.
Solution overview SageMaker Canvas brings together a broad set of capabilities to help data professionals prepare, build, train, and deploy ML models without writing any code. SageMaker Data Wrangler has also been integrated into SageMaker Canvas, reducing the time it takes to import, prepare, transform, featurize, and analyze data.
Machine learning practitioners are often working with data at the beginning and during the full stack of things, so they see a lot of workflow/pipeline development, data wrangling, and data preparation. Some of the issues make perfect sense as they relate to dataquality, with common issues being bad/unclean data and data bias.
In the application pipeline, teams can swap: Logging inputs + responses to various data sources (database, stream, file, etc.) Additional data sources (RAG, web search, etc.) Classical ML models and LLMs If using QLORA to fine-tune, teams can swap out domain specific fine tuned adapters while using the same base model (e.g.
The last attribute, Churn , is the attribute that we want the ML model to predict. See the following code: # Configure the DataQuality Baseline Job # Configure the transient compute environment check_job_config = CheckJobConfig( role=role_arn, instance_count=1, instance_type="ml.c5.xlarge",
At DagsHub, we're building a platform to simplify your ML workflows. Every project consists of data, experiments, and models. At DagsHub we manage all those, and focus on helping you build and improve the quality of unstructured datasets, so you get high-performing models. Let’s dive into some details.
We couldn’t be more excited to announce our first group of partners for ODSC East 2023’s AI Expo and Demo Hall. These organizations are shaping the future of the AI and data science industries with their innovative products and services. Check them out below.
At the AI Expo and Demo Hall as part of ODSC West next week, you’ll have the opportunity to meet one-on-one with representatives from industry-leading organizations like Plot.ly, Google, Snowflake, Microsoft, and plenty more. Delphina Demo: AI-powered Data Scientist Jeremy Hermann | Co-founder at Delphina | Delphina.Ai
Artificial intelligence and machine learning (AI and ML) are removing some of the burden of manual metadata management, which has grown too cumbersome for people to manage alone. Data intelligence integrates intelligence derived from active metadata into categories like dataquality, governance, and profiling.
At the AI Expo and Demo Hall as part of ODSC West in a few weeks, you’ll have the opportunity to meet one-on-one with representatives from industry-leading organizations like Microsoft Azure, Hewlett Packard, Iguazio, neo4j, Tangent Works, Qwak, Cloudera, and others.
Unfortunately accessing data across various locations and file types and then operationalizing that data for AI usage has traditionally been a painfully manual, time-consuming, and costly process. Ahmad Khan, Head of AI/ML Strategy at Snowflake, discusses the challenges of operationalizing ML in a recent talk.
Unfortunately accessing data across various locations and file types and then operationalizing that data for AI usage has traditionally been a painfully manual, time-consuming, and costly process. Ahmad Khan, Head of AI/ML Strategy at Snowflake, discusses the challenges of operationalizing ML in a recent talk.
Building a machine learning (ML) pipeline can be a challenging and time-consuming endeavor. Inevitably concept and data drift over time cause degradation in a model’s performance. For an ML project to be successful, teams must build an end-to-end MLOps workflow that is scalable, auditable, and adaptable.
Building a machine learning (ML) pipeline can be a challenging and time-consuming endeavor. Inevitably concept and data drift over time cause degradation in a model’s performance. For an ML project to be successful, teams must build an end-to-end MLOps workflow that is scalable, auditable, and adaptable.
Tuesday is the first day of the AI Expo and Demo Hall , where you can connect with our conference partners and check out the latest developments and research from leading tech companies. Finally, get ready for some All Hallows Eve fun with Halloween Data After Dark , featuring a costume contest, candy, and more. What’s next?
Artificial intelligence and machine learning (AI/ML) offer new avenues for credit scoring solutions and could usher in a new era of fairness, efficiency, and risk management. Traditional credit scoring models rely on static variables and historical data like income, employment, and debt-to-income ratio. Supercharge predictive modeling.
Databricks customers can now access millions of rows of data seamlessly within the Snorkel Flow platform thanks to a new Databricks connector. Weeks later, on June 29, Snorkel AI Founding Engineer and Product Director Vincent Chen will present at “ Building AI-Powered Products with Foundation Models ” at the Databricks Data + AI Summit.
Databricks customers can now access millions of rows of data seamlessly within the Snorkel Flow platform thanks to a new Databricks connector. Weeks later, on June 29, Snorkel AI Founding Engineer and Product Director Vincent Chen will present at “ Building AI-Powered Products with Foundation Models ” at the Databricks Data + AI Summit.
From gathering and processing data to building models through experiments, deploying the best ones, and managing them at scale for continuous value in production—it’s a lot. As the number of ML-powered apps and services grows, it gets overwhelming for data scientists and ML engineers to build and deploy models at scale.
Request a demo to see how watsonx can put AI to work There’s no AI, without IA AI is only as good as the data that informs it, and the need for the right data foundation has never been greater. A data lakehouse with multiple query engines and storage can allow engineers to share data in open formats.
Artificial intelligence and machine learning (AI/ML) offer new avenues for credit scoring solutions and could usher in a new era of fairness, efficiency, and risk management. Traditional credit scoring models rely on static variables and historical data like income, employment, and debt-to-income ratio. Book a demo today.
It went from simple rule-based systems to advanced data-driven algorithms. Today, real-time trading choices are made by AI using the combined power of big data, machine learning (ML), and predictive analytics. Algorithms for ML: AI models employ ML to adjust and find correlations, gradually improving accuracy.
Snorkel AI and Google Cloud have partnered to help organizations successfully transform raw, unstructured data into actionable AI-powered systems. Snorkel Flow easily deploys on Google Cloud infrastructure, ingests data from Google Cloud data sources, and integrates with Google Cloud’s AI and Data Cloud services.
Snorkel AI and Google Cloud have partnered to help organizations successfully transform raw, unstructured data into actionable AI-powered systems. Snorkel Flow easily deploys on Google Cloud infrastructure, ingests data from Google Cloud data sources, and integrates with Google Cloud’s AI and Data Cloud services.
Key Takeaways Data Fabric is a modern data architecture that facilitates seamless data access, sharing, and management across an organization. Data management recommendations and data products emerge dynamically from the fabric through automation, activation, and AI/ML analysis of metadata.
They are characterized by their enormous size, complexity, and the vast amount of data they process. These elements need to be taken into consideration when managing, streamlining and deploying LLMs in ML pipelines, hence the specialized discipline of LLMOps. Data Pipeline - Manages and processes various data sources.
Few nonusers (2%) report that lack of data or dataquality is an issue, and only 1.3% AI users are definitely facing these problems: 7% report that dataquality has hindered further adoption, and 4% cite the difficulty of training a model on their data. Deploying and managing AI products isn’t simple.
This is where visualizations in ML come in. Graphical representations of structures and data flow within a deep learning model make its complexity easier to comprehend and enable insight into its decision-making process. Data scientists and ML engineers: Creating and training deep learning models is no easy feat.
Businesses face significant hurdles when preparing data for artificial intelligence (AI) applications. The existence of data silos and duplication, alongside apprehensions regarding dataquality, presents a multifaceted environment for organizations to manage.
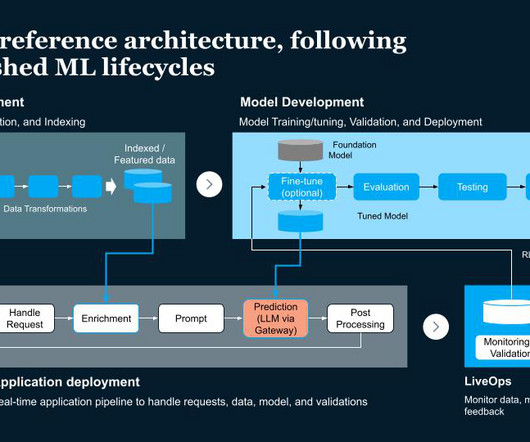
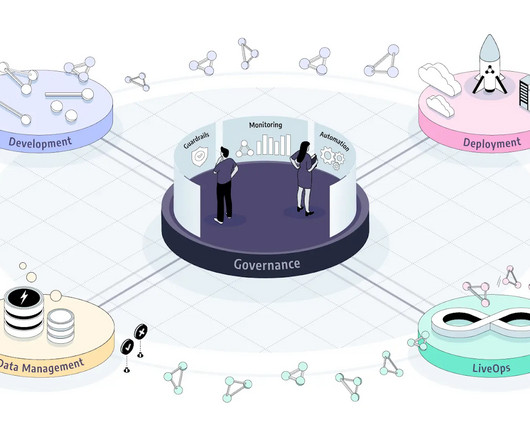
Data management - Ensuring dataquality through data ingestion, transformation, cleansing, versioning, tagging, labeling, indexing, and more. Development - High quality model training, fine-tuning or prompt tuning, validation and deployment with CI/CD for ML.
Our advanced search capability means that we can build the easiest-to-use and massively powerful interfaces for data stewards. Our ability to leverage ML for each allows us to make operations teams far more efficient. Our comprehensive connectors mean that we can build lineage much more efficiently. However, we can’t do it alone.
If your dataset is not in time order (time consistency is required for accurate Time Series projects), DataRobot can fix those gaps using the DataRobot Data Prep tool , a no-code tool that will get your data ready for Time Series forecasting. Prepare your data for Time Series Forecasting. Configuring an ML project.
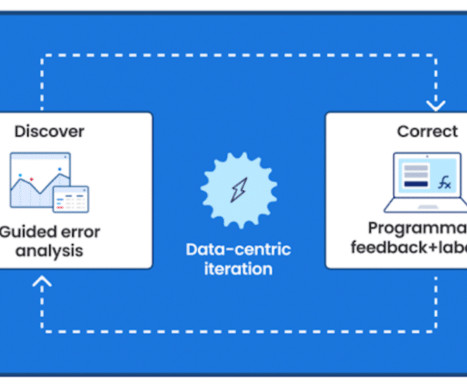
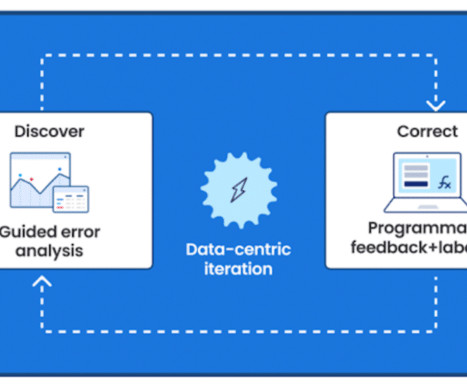
Instead of exclusively relying on a singular data development technique, leverage a variety of techniques such as promoting, RAG, and fine-tuning for the most optimal outcome. Focus on improving dataquality and transforming manual data development processes into programmatic operations to scale fine-tuning.
In the next section, let’s take a deeper look into how these key attributes help data scientists and analysts make faster, more informed decisions, while supporting stewards in their quest to scale governance policies on the Data Cloud easily. Find Trusted Data. Verifying quality is time consuming.
Large Model Quality and Evaluation Anoop Sinha | Research Director, AI & Future Technologies | Google Large model development faces many challenges when it comes to MLquality and evaluation, including the coverage, scale, and wide use cases for what LLMs are used for. Check out a few of them below.
We also show a banking chatbot demo that includes fine-tuning a model and adding guardrails. Data Management - Ensuring dataquality through data ingestion, transformation, cleansing, versioning, tagging, labeling, indexing, and more. Using the same data for model improvement. The four pipelines include: 1.
We also show a banking chatbot demo that includes fine-tuning a model and adding guardrails. Data Management - Ensuring dataquality through data ingestion, transformation, cleansing, versioning, tagging, labeling, indexing, and more. Using the same data for model improvement. The four pipelines include: 1.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



































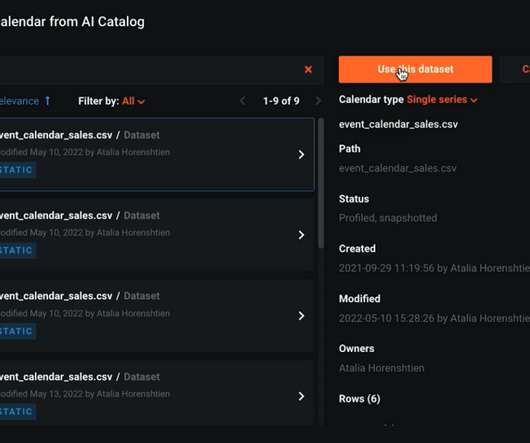



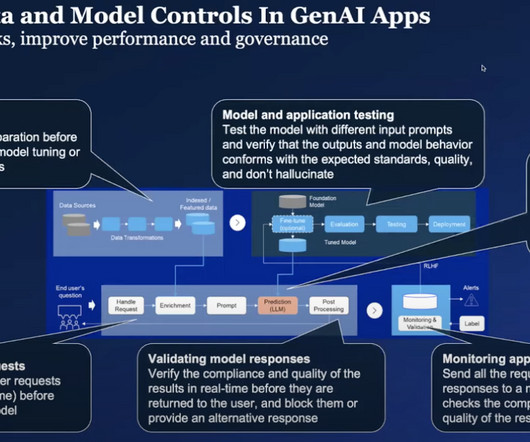
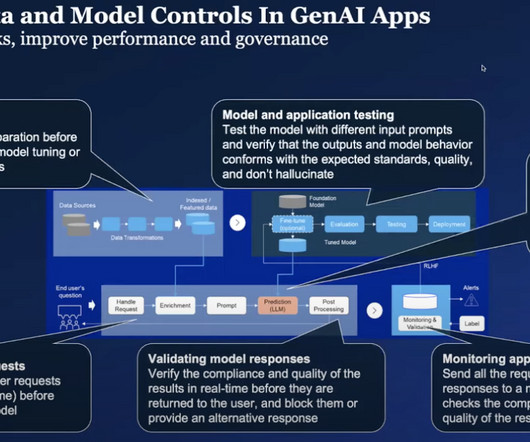






Let's personalize your content