This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
the data intelligence company, launched its AI Governance solution to help organizations realize value from their data and AI initiatives. The solution ensures that AI models are developed using secure, compliant, and well-documenteddata. Alation Inc.,
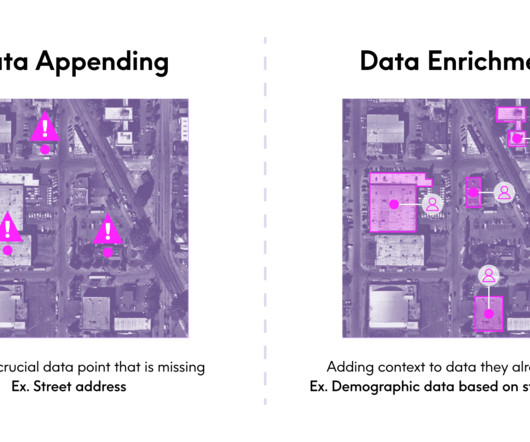
Read Challenges in Ensuring DataQuality Through Appending and Enrichment The benefits of enriching and appending additional context and information to your existing data are clear but adding that data makes achieving and maintaining dataquality a bigger task.
One study by Think With Google shows that marketing leaders are 130% as likely to have a documenteddata strategy. Data strategies are becoming more dependent on new technology that is arising. One of the newest ways data-driven companies are collecting data is through the use of OCR.
Many Data Governance or DataQuality programs focus on “critical data elements,” but what are they and what are some key features to document for them? A critical data element is any data element in your organization that has a high impact on your organization’s ability to execute its business strategy.
generally available on May 24, Alation introduces the Open DataQuality Initiative for the modern data stack, giving customers the freedom to choose the dataquality vendor that’s best for them with the added confidence that those tools will integrate seamlessly with Alation’s Data Catalog and Data Governance application.
However, the success of any data project hinges on a critical, often overlooked phase: gathering requirements. Conversely, clear, well-documented requirements set the foundation for a project that meets objectives, aligns with stakeholder expectations, and delivers measurable value. Key questions to ask: What data sources are required?
This approach is ideal for use cases requiring accuracy and up-to-date information, like providing technical product documentation or customer support. Data preparation for LLM fine-tuning Proper data preparation is key to achieving high-quality results when fine-tuning LLMs for specific purposes.
Summary: Dataquality is a fundamental aspect of Machine Learning. Poor-qualitydata leads to biased and unreliable models, while high-qualitydata enables accurate predictions and insights. What is DataQuality in Machine Learning? Bias in data can result in unfair and discriminatory outcomes.
This enables sales teams to interact with our internal sales enablement collateral, including sales plays and first-call decks, as well as customer references, customer- and field-facing incentive programs, and content on the AWS website, including blog posts and service documentation.
As such, the quality of their data can make or break the success of the company. This article will guide you through the concept of a dataquality framework, its essential components, and how to implement it effectively within your organization. What is a dataquality framework?
Dataquality plays a significant role in helping organizations strategize their policies that can keep them ahead of the crowd. Hence, companies need to adopt the right strategies that can help them filter the relevant data from the unwanted ones and get accurate and precise output.
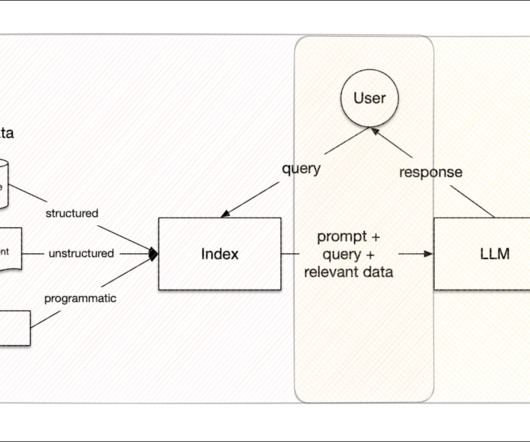
These connectors enable direct data ingestion from native formats and sources, eliminating the need for time-consuming data conversions. Engines: LLamaIndex Engines are the driving force that bridges LLMs and data sources, ensuring straightforward access to real-world information.
Beyond Scale: DataQuality for AI Infrastructure The trajectory of AI over the past decade has been driven largely by the scale of data available for training and the ability to process it with increasingly powerful compute & experimental models. Author(s): Richie Bachala Originally published on Towards AI.
How Artificial Intelligence is Impacting DataQuality. Artificial intelligence has the potential to combat human error by taking up the tasking responsibilities associated with the analysis, drilling, and dissection of large volumes of data. Dataquality is crucial in the age of artificial intelligence. Conclusion.
. — Peter Norvig, The Unreasonable Effectiveness of Data. Edited Photo by Taylor Vick on Unsplash In ML engineering, dataquality isn’t just critical — it’s foundational. Since 2011, Peter Norvig’s words underscore the power of a data-centric approach in machine learning. Using biased or low-qualitydata?
In this blog, we are going to unfold the two key aspects of data management that is Data Observability and DataQuality. Data is the lifeblood of the digital age. Today, every organization tries to explore the significant aspects of data and its applications.
Here’s a simple rough sketch of RAG: Start with a collection of documents about a domain. Split each document into chunks. One more embellishment is to use a graph neural network (GNN) trained on the documents. Chunk your documents from unstructured data sources, as usual in GraphRAG. at Facebook—both from 2020.
By Vatsal Saglani This article explores the creation of PDF2Pod, a NotebookLM clone that transforms PDF documents into engaging, multi-speaker podcasts. It also demonstrates how to store and retrieve embedded documents using vector stores and visualize embeddings for better understanding.
Follow five essential steps for success in making your data AI ready with data integration. Define clear goals, assess your data landscape, choose the right tools, ensure dataquality and governance, and continuously optimize your integration processes.
How to Scale Your DataQuality Operations with AI and ML: In the fast-paced digital landscape of today, data has become the cornerstone of success for organizations across the globe. Every day, companies generate and collect vast amounts of data, ranging from customer information to market trends.
“Quality over Quantity” is a phrase we hear regularly in life, but when it comes to the world of data, we often fail to adhere to this rule. DataQuality Monitoring implements quality checks in operational data processes to ensure that the data meets pre-defined standards and business rules.
He uses the biomedical field as an example, where currently LLMs are focused on clinical documentation. It serves as a dedicated workspace where the model can generate code snippets, design websites, and even draft documents and infographics in real time. Comparing benchmark scores of Claude 3.5 As of now, Claude 3.5
A NoSQl database can use documents for the storage and retrieval of data. The central concept is the idea of a document. Documents encompass and encode data (or information) in a standard format. A document is susceptible to change. The documents can be in PDF format. Speaking of which.
The service, which was launched in March 2021, predates several popular AWS offerings that have anomaly detection, such as Amazon OpenSearch , Amazon CloudWatch , AWS Glue DataQuality , Amazon Redshift ML , and Amazon QuickSight. To learn more, see the documentation. To learn more, see the documentation.
Text analytics: Text analytics, also known as text mining, deals with unstructured text data, such as customer reviews, social media comments, or documents. It uses natural language processing (NLP) techniques to extract valuable insights from textual data. Poor data integration can lead to inaccurate insights.
This framework creates a central hub for feature management and governance with enterprise feature store capabilities, making it straightforward to observe the data lineage for each feature pipeline, monitor dataquality , and reuse features across multiple models and teams.
Ask computer vision, machine learning, and data science questions : VoxelGPT is a comprehensive educational resource providing insights into fundamental concepts and solutions to common dataquality issues.
This includes ensuring that data is properly labeled and processed, managing dataquality, and ensuring that the right data is used for training and testing models. Collaboration and Communication: Collaboration and communication between data scientists, engineers, and other stakeholders is essential for successful MLOps.
This includes ensuring that data is properly labeled and processed, managing dataquality, and ensuring that the right data is used for training and testing models.
Document understanding Fine-tuning is particularly effective for extracting structured information from document images. This includes tasks like form field extraction, table data retrieval, and identifying key elements in invoices, receipts, or technical diagrams. When working with documents, note that Meta Llama 3.2
These vary from challenges in getting data, maintaining various data forms and kinds, and coping with inconsistent dataquality to the crucial need for current information.
When needed, the system can access an ODAP data warehouse to retrieve additional information. Document management Documents are securely stored in Amazon S3, and when new documents are added, a Lambda function processes them into chunks.
Document categorization or classification has significant benefits across business domains – Improved search and retrieval – By categorizing documents into relevant topics or categories, it makes it much easier for users to search and retrieve the documents they need. This allows for better monitoring and auditing.
User support arrangements Consider the availability and quality of support from the provider or vendor, including documentation, tutorials, forums, customer service, etc. Check out the Kubeflow documentation. Metaflow Metaflow helps data scientists and machine learning engineers build, manage, and deploy data science projects.
Key Takeaways: Data integrity is essential for AI success and reliability – helping you prevent harmful biases and inaccuracies in AI models. Robust data governance for AI ensures data privacy, compliance, and ethical AI use. Proactive dataquality measures are critical, especially in AI applications.
Dataquality dependency: Success depends heavily on having high-quality preference data. When choosing an alignment method, organizations must weigh trade-offs like complexity, computational cost, and dataquality requirements. Learn how to get more value from your PDF documents!
Therefore, the cost of using Claude API isn’t static; it’s shaped by several factors including the volume of requests, dataquality and type, and the standard of service needed. Checking the official Anthropic API documents can offer valuable insights here. The estimated cost is around $11.02
To quickly explore the loan data, choose Get data insights and select the loan_status target column and Classification problem type. The generated DataQuality and Insight report provides key statistics, visualizations, and feature importance analyses. Now you have a balanced target column.
Database standards are common practices and procedures that are documented and […]. Rigidly adhering to a standard, any standard, without being reasonable and using your ability to think through changing situations and circumstances is itself a bad standard.
Our experiments demonstrate that careful attention to dataquality, hyperparameter optimization, and best practices in the fine-tuning process can yield substantial gains over base models. This decision should be based either on the provided context or your general knowledge and memory.
Amazon DocumentDB is a fully managed native JSON document database that makes it straightforward and cost-effective to operate critical document workloads at virtually any scale without managing infrastructure. On the Analyses tab, choose DataQuality and Insights Report. Choose Predictive analysis , then choose Create.
We also detail the steps that data scientists can take to configure the data flow, analyze the dataquality, and add data transformations. Finally, we show how to export the data flow and train a model using SageMaker Autopilot. Data Wrangler creates the report from the sampled data.
Though not specific to finance, the challenge comes to play when it comes to extracting specialized financial data. From APIs, photos, web platforms PDF documents, and Excel files, all of this data is critical when it comes to training language models specific to the banking and finance industry.
It helps you locate and discover data that fit your search criteria. With data catalogs, you won’t have to waste time looking for information you think you have. What Does a Data Catalog Do? Advanced data catalogs can update metadata based on the data’s origins. How Does a Data Catalog Impact Employees?
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content