This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Introduction Machinelearning has become an essential tool for organizations of all sizes to gain insights and make data-driven decisions. However, the success of ML projects is heavily dependent on the quality of data used to train models. appeared first on Analytics Vidhya.
generally available on May 24, Alation introduces the Open DataQuality Initiative for the modern data stack, giving customers the freedom to choose the dataquality vendor that’s best for them with the added confidence that those tools will integrate seamlessly with Alation’s Data Catalog and Data Governance application.
These tools provide data engineers with the necessary capabilities to efficiently extract, transform, and load (ETL) data, build data pipelines, and prepare data for analysis and consumption by other applications. It provides a scalable and fault-tolerant ecosystem for big data processing.
Summary: This article explores the significance of ETLData in Data Management. It highlights key components of the ETL process, best practices for efficiency, and future trends like AI integration and real-time processing, ensuring organisations can leverage their data effectively for strategic decision-making.
However, efficient use of ETL pipelines in ML can help make their life much easier. This article explores the importance of ETL pipelines in machinelearning, a hands-on example of building ETL pipelines with a popular tool, and suggests the best ways for data engineers to enhance and sustain their pipelines.
Summary: The ETL process, which consists of data extraction, transformation, and loading, is vital for effective data management. Following best practices and using suitable tools enhances data integrity and quality, supporting informed decision-making. What is ETL? ETL stands for Extract, Transform, Load.
Summary: Selecting the right ETL platform is vital for efficient data integration. Consider your business needs, compare features, and evaluate costs to enhance data accuracy and operational efficiency. Introduction In today’s data-driven world, businesses rely heavily on ETL platforms to streamline data integration processes.
Dataquality plays a significant role in helping organizations strategize their policies that can keep them ahead of the crowd. Hence, companies need to adopt the right strategies that can help them filter the relevant data from the unwanted ones and get accurate and precise output.
He specializes in large language models, cloud infrastructure, and scalable data systems, focusing on building intelligent solutions that enhance automation and data accessibility across Amazons operations. He specializes in building scalable machinelearning infrastructure, distributed systems, and containerization technologies.
Beyond Scale: DataQuality for AI Infrastructure The trajectory of AI over the past decade has been driven largely by the scale of data available for training and the ability to process it with increasingly powerful compute & experimental models. Author(s): Richie Bachala Originally published on Towards AI.
Amazon Lookout for Metrics is a fully managed service that uses machinelearning (ML) to detect anomalies in virtually any time-series business or operational metrics—such as revenue performance, purchase transactions, and customer acquisition and retention rates—with no ML experience required. To learn more, see the documentation.
Summary: Choosing the right ETL tool is crucial for seamless data integration. Top contenders like Apache Airflow and AWS Glue offer unique features, empowering businesses with efficient workflows, high dataquality, and informed decision-making capabilities. Also Read: Top 10 Data Science tools for 2024.
Cloud-based business intelligence (BI): Cloud-based BI tools enable organizations to access and analyze data from cloud-based sources and on-premises databases. Machinelearning and AI analytics: Machinelearning and AI analytics leverage advanced algorithms to automate the analysis of data, discover hidden patterns, and make predictions.
Zeta’s AI innovation is powered by a proprietary machinelearning operations (MLOps) system, developed in-house. Context In early 2023, Zeta’s machinelearning (ML) teams shifted from traditional vertical teams to a more dynamic horizontal structure, introducing the concept of pods comprising diverse skill sets.
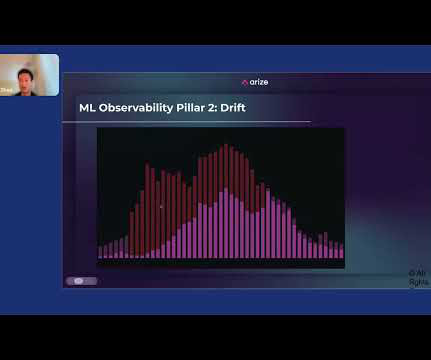
Jack Zhou, product manager at Arize , gave a lightning talk presentation entitled “How to Apply MachineLearning Observability to Your ML System” at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. You have to make sure that your ETLs are locked down. Arize AI The third pillar is dataquality.
Jack Zhou, product manager at Arize , gave a lightning talk presentation entitled “How to Apply MachineLearning Observability to Your ML System” at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. You have to make sure that your ETLs are locked down. Arize AI The third pillar is dataquality.
Jack Zhou, product manager at Arize , gave a lightning talk presentation entitled “How to Apply MachineLearning Observability to Your ML System” at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. You have to make sure that your ETLs are locked down. Arize AI The third pillar is dataquality.
In this first post, we introduce mobility data, its sources, and a typical schema of this data. We then discuss the various use cases and explore how you can use AWS services to clean the data, how machinelearning (ML) can aid in this effort, and how you can make ethical use of the data in generating visuals and insights.
The batch views within the Lambda architecture allow for the application of more complex or resource-intensive rules, resulting in superior dataquality and reduced bias over time. On the other hand, the real-time views provide immediate access to the most current data.
Summary: Data transformation tools streamline data processing by automating the conversion of raw data into usable formats. These tools enhance efficiency, improve dataquality, and support Advanced Analytics like MachineLearning. Why Are Data Transformation Tools Important?
Unstructured data makes up 80% of the world's data and is growing. Managing unstructured data is essential for the success of machinelearning (ML) projects. Without structure, data is difficult to analyze and extracting meaningful insights and patterns is challenging. Unstructured.io
Data engineers are essential professionals responsible for designing, constructing, and maintaining an organization’s data infrastructure. They create data pipelines, ETL processes, and databases to facilitate smooth data flow and storage. Read more to know.
Data engineers play a crucial role in managing and processing big data Ensuring dataquality and integrity Dataquality and integrity are essential for accurate data analysis. Data engineers are responsible for ensuring that the data collected is accurate, consistent, and reliable.
Data Engineering emphasises the infrastructure and tools necessary for data collection, storage, and processing, while Data Engineers concentrate on the architecture, pipelines, and workflows that facilitate data access. Key components of data warehousing include: ETL Processes: ETL stands for Extract, Transform, Load.
Businesses face significant hurdles when preparing data for artificial intelligence (AI) applications. The existence of data silos and duplication, alongside apprehensions regarding dataquality, presents a multifaceted environment for organizations to manage.
Here are some effective strategies to break down data silos: Data Integration Solutions Employing tools for data integration such as Extract, Transform, Load (ETL) processes can help consolidate data from various sources into a single repository. This allows for easier access and analysis across departments.
In the digital age, the abundance of textual information available on the internet, particularly on platforms like Twitter, blogs, and e-commerce websites, has led to an exponential growth in unstructured data. Text data is often unstructured, making it challenging to directly apply machinelearning algorithms for sentiment analysis.
These technologies include the following: Data governance and management — It is crucial to have a solid data management system and governance practices to ensure data accuracy, consistency, and security. It is also important to establish dataquality standards and strict access controls.
Let’s delve into the key components that form the backbone of a data warehouse: Source Systems These are the operational databases, CRM systems, and other applications that generate the raw data feeding the data warehouse. Data Extraction, Transformation, and Loading (ETL) This is the workhorse of architecture.
Based on the McKinsey survey , 56% of orgs today are using machinelearning in at least one business function. AWS Sagemeaker is in fact a great tool for machinelearning operations (MLOps) to automate and standardize processes across the ML lifecycle. This includes dataquality, privacy, and compliance.
Amazon SageMaker Studio provides a fully managed solution for data scientists to interactively build, train, and deploy machinelearning (ML) models. Amazon SageMaker notebook jobs allow data scientists to run their notebooks on demand or on a schedule with a few clicks in SageMaker Studio.
Amazon SageMaker Data Wrangler reduces the time it takes to collect and prepare data for machinelearning (ML) from weeks to minutes. Account A is the data lake account that houses all the ML-ready data obtained through extract, transform, and load (ETL) processes.
The advent of big data, affordable computing power, and advanced machinelearning algorithms has fueled explosive growth in data science across industries. However, research shows that up to 85% of data science projects fail to move beyond proofs of concept to full-scale deployment.
Skills like effective verbal and written communication will help back up the numbers, while data visualization (specific frameworks in the next section) can help you tell a complete story. Data Wrangling: DataQuality, ETL, Databases, Big Data The modern data analyst is expected to be able to source and retrieve their own data for analysis.
Data within a data fabric is defined using metadata and may be stored in a data lake, a low-cost storage environment that houses large stores of structured, semi-structured and unstructured data for business analytics, machinelearning and other broad applications.
Innovators in the industry understand that leading-edge technologies such as AI and machinelearning will be a deciding factor in the quest for competitive advantage when moving to the cloud. To learn more, read our ebook. Insufficient skills, limited budgets, and poor dataquality also present significant challenges.
There are various architectural design patterns in data engineering that are used to solve different data-related problems. This article discusses five commonly used architectural design patterns in data engineering and their use cases. Finally, the transformed data is loaded into the target system.
Summary: Data ingestion is the process of collecting, importing, and processing data from diverse sources into a centralised system for analysis. This crucial step enhances dataquality, enables real-time insights, and supports informed decision-making. It supports both batch and real-time processing.
Data Integration Tools Technologies such as Apache NiFi and Talend help in the seamless integration of data from various sources into a unified system for analysis. Understanding ETL (Extract, Transform, Load) processes is vital for students. Students should learn about data wrangling and the importance of dataquality.
Salam noted that organizations are offloading computational horsepower and data from on-premises infrastructure to the cloud. This provides developers, engineers, data scientists and leaders with the opportunity to more easily experiment with new data practices such as zero-ETL or technologies like AI/ML.
The story is all too common – a business user requests some data, the data team creates/prioritizes a ticket, and said ticket is completed after some number of months (or weeks if you’re lucky) – just to have the data be wrong, and the whole process starts again. Those are scary for data teams to change.
This comprehensive blog outlines vital aspects of Data Analyst interviews, offering insights into technical, behavioural, and industry-specific questions. It covers essential topics such as SQL queries, data visualization, statistical analysis, machinelearning concepts, and data manipulation techniques.
This makes it easier to compare and contrast information and provides organizations with a unified view of their data. MachineLearningData pipelines feed all the necessary data into machinelearning algorithms, thereby making this branch of Artificial Intelligence (AI) possible.
Data Integration Once data is collected from various sources, it needs to be integrated into a cohesive format. DataQuality Management : Ensures that the integrated data is accurate, consistent, and reliable for analysis. These tools work together to facilitate efficient data management and analysis processes.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content