This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Introduction Machine learning has become an essential tool for organizations of all sizes to gain insights and make data-driven decisions. However, the success of ML projects is heavily dependent on the quality of data used to train models. Poor dataquality can lead to inaccurate predictions and poor model performance.
generally available on May 24, Alation introduces the Open DataQuality Initiative for the modern data stack, giving customers the freedom to choose the dataquality vendor that’s best for them with the added confidence that those tools will integrate seamlessly with Alation’s Data Catalog and Data Governance application.
From data processing to quick insights, robust pipelines are a must for any ML system. Often the Data Team, comprising Data and ML Engineers , needs to build this infrastructure, and this experience can be painful. However, efficient use of ETL pipelines in ML can help make their life much easier.
Organizations require reliable data for robust AI models and accurate insights, yet the current technology landscape presents unparalleled dataquality challenges. Two of the more popular methods, extract, transform, load (ETL ) and extract, load, transform (ELT) , are both highly performant and scalable.
Summary: This article explores the significance of ETLData in Data Management. It highlights key components of the ETL process, best practices for efficiency, and future trends like AI integration and real-time processing, ensuring organisations can leverage their data effectively for strategic decision-making.
Dataquality plays a significant role in helping organizations strategize their policies that can keep them ahead of the crowd. Hence, companies need to adopt the right strategies that can help them filter the relevant data from the unwanted ones and get accurate and precise output.
Amazon Lookout for Metrics is a fully managed service that uses machine learning (ML) to detect anomalies in virtually any time-series business or operational metrics—such as revenue performance, purchase transactions, and customer acquisition and retention rates—with no ML experience required. To learn more, see the documentation.
In this first post, we introduce mobility data, its sources, and a typical schema of this data. We then discuss the various use cases and explore how you can use AWS services to clean the data, how machine learning (ML) can aid in this effort, and how you can make ethical use of the data in generating visuals and insights.
Previously, he was a Data & Machine Learning Engineer at AWS, where he worked closely with customers to develop enterprise-scale data infrastructure, including data lakes, analytics dashboards, and ETL pipelines. He specializes in designing, building, and optimizing large-scale data solutions.
Businesses face significant hurdles when preparing data for artificial intelligence (AI) applications. The existence of data silos and duplication, alongside apprehensions regarding dataquality, presents a multifaceted environment for organizations to manage.
Amazon SageMaker Studio provides a fully managed solution for data scientists to interactively build, train, and deploy machine learning (ML) models. Amazon SageMaker notebook jobs allow data scientists to run their notebooks on demand or on a schedule with a few clicks in SageMaker Studio.
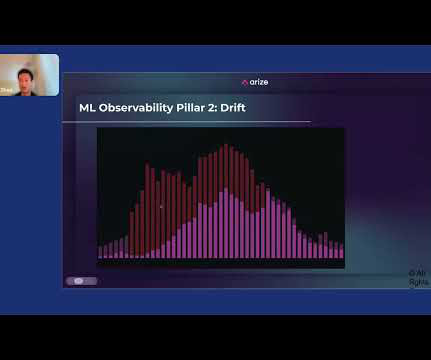
Jack Zhou, product manager at Arize , gave a lightning talk presentation entitled “How to Apply Machine Learning Observability to Your ML System” at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. So ML ends up being a huge part of many large companies’ core functions. Why is this important?
Jack Zhou, product manager at Arize , gave a lightning talk presentation entitled “How to Apply Machine Learning Observability to Your ML System” at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. So ML ends up being a huge part of many large companies’ core functions. Why is this important?
Jack Zhou, product manager at Arize , gave a lightning talk presentation entitled “How to Apply Machine Learning Observability to Your ML System” at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. So ML ends up being a huge part of many large companies’ core functions. Why is this important?
This article was originally an episode of the ML Platform Podcast , a show where Piotr Niedźwiedź and Aurimas Griciūnas, together with ML platform professionals, discuss design choices, best practices, example tool stacks, and real-world learnings from some of the best ML platform professionals. Stefan: Yeah.
This includes the tools and techniques we used to streamline the ML model development and deployment processes, as well as the measures taken to monitor and maintain models in a production environment. Costs: Oftentimes, cost is the most important aspect of any ML model deployment. This includes dataquality, privacy, and compliance.
Salam noted that organizations are offloading computational horsepower and data from on-premises infrastructure to the cloud. This provides developers, engineers, data scientists and leaders with the opportunity to more easily experiment with new data practices such as zero-ETL or technologies like AI/ML.
As companies strive to leverage AI/ML, location intelligence, and cloud analytics into their portfolio of tools, siloed mainframe data often stands in the way of forward momentum. Insufficient skills, limited budgets, and poor dataquality also present significant challenges.
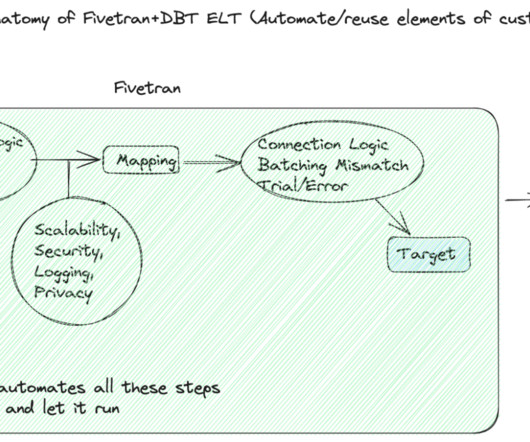
Data pipeline stages But before delving deeper into the technical aspects of these tools, let’s quickly understand the core components of a data pipeline succinctly captured in the image below: Data pipeline stages | Source: Author What does a good data pipeline look like?
To power AI and analytics workloads across your transactional and purpose-built databases, you must ensure they can seamlessly integrate with an open data lakehouse architecture without duplication or additional extract, transform, load (ETL) processes. Effective dataquality management is crucial to mitigating these risks.
Tools such as Python’s Pandas library, Apache Spark, or specialised data cleaning software streamline these processes, ensuring data integrity before further transformation. Step 3: Data Transformation Data transformation focuses on converting cleaned data into a format suitable for analysis and storage.
Amazon SageMaker Data Wrangler reduces the time it takes to collect and prepare data for machine learning (ML) from weeks to minutes. Account A is the data lake account that houses all the ML-ready data obtained through extract, transform, and load (ETL) processes. Let’s go back to our data flow.
There are various architectural design patterns in data engineering that are used to solve different data-related problems. This article discusses five commonly used architectural design patterns in data engineering and their use cases. Finally, the transformed data is loaded into the target system.
Skills like effective verbal and written communication will help back up the numbers, while data visualization (specific frameworks in the next section) can help you tell a complete story. Data Wrangling: DataQuality, ETL, Databases, Big Data The modern data analyst is expected to be able to source and retrieve their own data for analysis.
In general, this data has no clear structure because it may manifest real-world complexity, such as the subtlety of language or the details in a picture. Advanced methods are needed to process unstructured data, but its unstructured nature comes from how easily it is made and shared in today's digital world.
The project I did to land my business intelligence internship — CAR BRAND SEARCH ETL PROCESS WITH PYTHON, POSTGRESQL & POWER BI 1. Section 2: Explanation of the ETL diagram for the project. Section 4: Reporting data for the project insights. ETL ARCHITECTURE DIAGRAM ETL stands for Extract, Transform, Load.
Managing unstructured data is essential for the success of machine learning (ML) projects. Without structure, data is difficult to analyze and extracting meaningful insights and patterns is challenging. This article will discuss managing unstructured data for AI and ML projects. What is Unstructured Data?
ThoughSpot can easily connect to top cloud data platforms such as Snowflake AI Data Cloud , Oracle, SAP HANA, and Google BigQuery. In that case, ThoughtSpot also leverages ELT/ETL tools and Mode, a code-first AI-powered data solution that gives data teams everything they need to go from raw data to the modern BI stack.
This “analysis” is made possible in large part through machine learning (ML); the patterns and connections ML detects are then served to the data catalog (and other tools), which these tools leverage to make people- and machine-facing recommendations about data management and data integrations.
You can use stored procedures to handle complex ETL processes, make API calls, and perform data validation. Data Validation With stored procedures, you can validate data fields, data types, and constraints on data input to maintain dataquality.
If the event log is your customer’s diary, think of persistent staging as their scrapbook – a place where raw customer data is collected, organized, and kept for future reference. In traditional ETL (Extract, Transform, Load) processes in CDPs, staging areas were often temporary holding pens for data.
Data scientists use data-driven approaches to enable AI systems to make better predictions, optimize decision-making, and uncover hidden patterns that ultimately drive innovation and improve performance across various domains. You don’t need massive data sets because “dataquality scales better than data size.”
The ZMP analyzes billions of structured and unstructured data points to predict consumer intent by using sophisticated artificial intelligence (AI) to personalize experiences at scale. Hosted on Amazon ECS with tasks run on Fargate, this platform streamlines the end-to-end ML workflow, from data ingestion to model deployment.
Let’s delve into the key components that form the backbone of a data warehouse: Source Systems These are the operational databases, CRM systems, and other applications that generate the raw data feeding the data warehouse. Data Extraction, Transformation, and Loading (ETL) This is the workhorse of architecture.
The story is all too common – a business user requests some data, the data team creates/prioritizes a ticket, and said ticket is completed after some number of months (or weeks if you’re lucky) – just to have the data be wrong, and the whole process starts again. Those are scary for data teams to change.
Why Migrate to a Modern Data Stack? Slow Response to New Information: Legacy data systems often lack the computation power necessary to run efficiently and can be cost-inefficient to scale. This typically results in long-running ETL pipelines that cause decisions to be made on stale or old data.
Data mesh Another approach to data democratization uses a data mesh , a decentralized architecture that organizes data by a specific business domain. It uses knowledge graphs, semantics and AI/ML technology to discover patterns in various types of metadata.
There are various technologies that help operationalize and optimize the process of field trials, including data management and analytics, IoT, remote sensing, robotics, machine learning (ML), and now generative AI. Multi-source data is initially received and stored in an Amazon Simple Storage Service (Amazon S3) data lake.
To handle the log data efficiently, raw logs were centralized into an Amazon Simple Storage Service (Amazon S3) bucket. An Amazon EventBridge schedule checked this bucket hourly for new files and triggered log transformation extract, transform, and load (ETL) pipelines built using AWS Glue and Apache Spark.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












































Let's personalize your content