This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Introduction Machine learning has become an essential tool for organizations of all sizes to gain insights and make data-driven decisions. However, the success of ML projects is heavily dependent on the quality of data used to train models. Poor dataquality can lead to inaccurate predictions and poor model performance.
Introduction Whether you’re a fresher or an experienced professional in the Data industry, did you know that ML models can experience up to a 20% performance drop in their first year? Monitoring these models is crucial, yet it poses challenges such as data changes, concept alterations, and dataquality issues.
iMerit, a leading artificial intelligence (AI) data solutions company, released its 2023 State of ML Ops report, which includes a study outlining the impact of data on wide-scale commercial-ready AI projects.
Machine learning (ML) models are fundamentally shaped by data, and building inclusive ML systems requires significant considerations around how to design representative datasets.
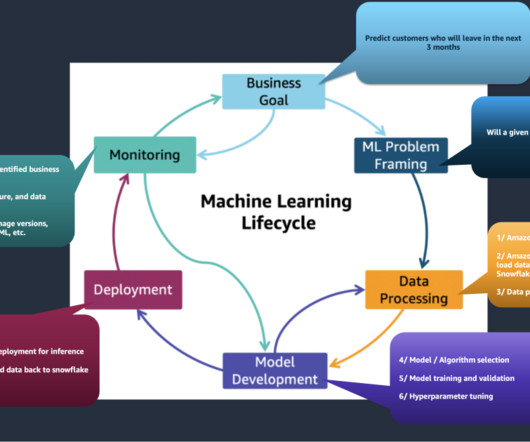
This post is part of an ongoing series about governing the machine learning (ML) lifecycle at scale. This post dives deep into how to set up data governance at scale using Amazon DataZone for the data mesh. The data mesh is a modern approach to data management that decentralizes data ownership and treats data as a product.
Look no further than ML Ops – the future of ML deployment. Machine Learning (ML) has become an increasingly valuable tool for businesses and organizations to gain insights and make data-driven decisions. However, deploying and maintaining ML models can be a complex and time-consuming process. What is ML Ops?
Modern businesses are embracing machine learning (ML) models to gain a competitive edge. Hence, improving the overall efficiency of the business and allow them to make data-driven decisions. Deploying ML models in their day-to-day processes allows businesses to adopt and integrate AI-powered solutions into their businesses.
However, while RPA and ML share some similarities, they differ in functionality, purpose, and the level of human intervention required. In this article, we will explore the similarities and differences between RPA and ML and examine their potential use cases in various industries. What is machine learning (ML)?
Data preparation is a crucial step in any machine learning (ML) workflow, yet it often involves tedious and time-consuming tasks. Amazon SageMaker Canvas now supports comprehensive data preparation capabilities powered by Amazon SageMaker Data Wrangler. Now you have a balanced target column.
With the increasing use of large models, requiring a large number of accelerated compute instances, observability plays a critical role in ML operations, empowering you to improve performance, diagnose and fix failures, and optimize resource utilization. This data makes sure models are being trained smoothly and reliably.
generally available on May 24, Alation introduces the Open DataQuality Initiative for the modern data stack, giving customers the freedom to choose the dataquality vendor that’s best for them with the added confidence that those tools will integrate seamlessly with Alation’s Data Catalog and Data Governance application.
Augmented analytics is revolutionizing how organizations interact with their data. By harnessing the power of machine learning (ML) and natural language processing (NLP), businesses can streamline their data analysis processes and make more informed decisions. What is augmented analytics?
Golden datasets play a pivotal role in the realms of artificial intelligence (AI) and machine learning (ML). As AI technology continues to evolve, the significance of these meticulously curated data collections becomes increasingly apparent.
Businesses are under pressure to show return on investment (ROI) from AI use cases, whether predictive machine learning (ML) or generative AI. Only 54% of ML prototypes make it to production, and only 5% of generative AI use cases make it to production. Using SageMaker, you can build, train and deploy ML models.
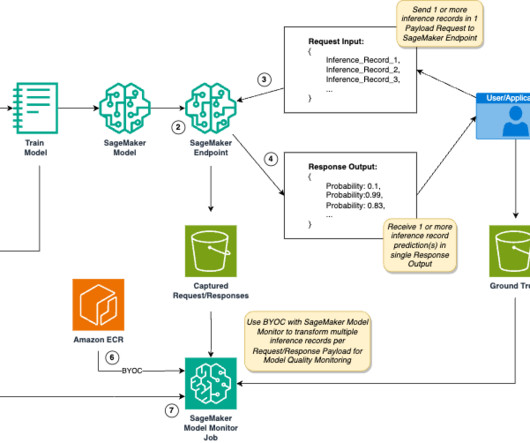
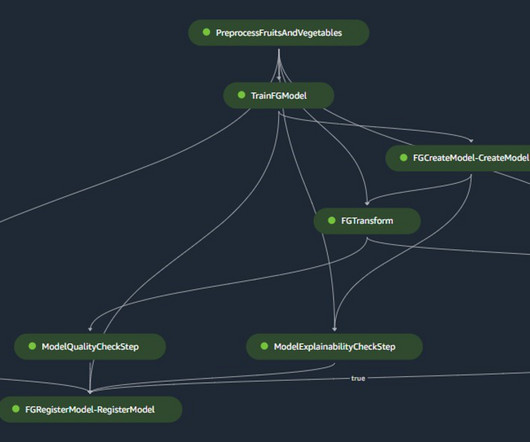
Real-world applications vary in inference requirements for their artificial intelligence and machine learning (AI/ML) solutions to optimize performance and reduce costs. SageMaker Model Monitor monitors the quality of SageMaker ML models in production.
The post When It Comes to DataQuality, Businesses Get Out What They Put In appeared first on DATAVERSITY. The stakes are high, so you search the web and find the most revered chicken parmesan recipe around. At the grocery store, it is immediately clear that some ingredients are much more […].
Do you need help to move your organization’s Machine Learning (ML) journey from pilot to production? Most executives think ML can apply to any business decision, but on average only half of the ML projects make it to production. Challenges Customers may face several challenges when implementing machine learning (ML) solutions.
ML and business should discuss these things in advance, such as how to ensure fairness, Krotkikh said. One similar example is the absence of price changes during sales; ML can, on its part, analyze how best to engage the model with such constraints to achieve good results overall for the entire sale.
Be sure to check out her talk, “ Power trusted AI/ML Outcomes with Data Integrity ,” there! Due to the tsunami of data available to organizations today, artificial intelligence (AI) and machine learning (ML) are increasingly important to businesses seeking competitive advantage through digital transformation.
How to Scale Your DataQuality Operations with AI and ML: In the fast-paced digital landscape of today, data has become the cornerstone of success for organizations across the globe. Every day, companies generate and collect vast amounts of data, ranging from customer information to market trends.
Posted by Peter Mattson, Senior Staff Engineer, ML Performance, and Praveen Paritosh, Senior Research Scientist, Google Research, Brain Team Machine learning (ML) offers tremendous potential, from diagnosing cancer to engineering safe self-driving cars to amplifying human productivity. Each step can introduce issues and biases.
Look no further than MLOps – the future of ML deployment. Machine Learning (ML) has become an increasingly valuable tool for businesses and organizations to gain insights and make data-driven decisions. However, deploying and maintaining ML models can be a complex and time-consuming process.
This reliance has spurred a significant shift across industries, driven by advancements in artificial intelligence (AI) and machine learning (ML), which thrive on comprehensive, high-qualitydata.
ML models have grown significantly in recent years, and businesses increasingly rely on them to automate and optimize their operations. However, managing ML models can be challenging, especially as models become more complex and require more resources to train and deploy. What is MLOps?
Data wrangling and cleaning: The ability to handle and preprocess large and complex datasets, dealing with missing values, outliers, and data inconsistencies, is critical for data scientists to ensure dataquality and integrity.
The new web data gathering tool, powered by AI and machine learning (ML) algorithms, promises a staggering 100% success rate for scraping sessions, among many other advantages. Revolutionizing the approach to web data gathering. Therefore, dataquality assurance is essential.
Most of task-specific labeled data comes from human annotation, such as classification task or RLHF labeling (which can be constructed as classification format) for LLM alignment training.
Read the full series here: Building the foundation for customer dataquality. The rapid advancement of artificial intelligence (AI) and machine learning (ML) technologies is pushing the boundaries of what can be achieved in marketing, customer experience … This article is part of a VB special issue.
In this post, we share how Axfood, a large Swedish food retailer, improved operations and scalability of their existing artificial intelligence (AI) and machine learning (ML) operations by prototyping in close collaboration with AWS experts and using Amazon SageMaker. This is a guest post written by Axfood AB.
The growth of the AI and Machine Learning (ML) industry has continued to grow at a rapid rate over recent years. Hidden Technical Debt in Machine Learning Systems More money, more problems — Rise of too many ML tools 2012 vs 2023 — Source: Matt Turck People often believe that money is the solution to a problem.
As such, the quality of their data can make or break the success of the company. This article will guide you through the concept of a dataquality framework, its essential components, and how to implement it effectively within your organization. What is a dataquality framework?
Alignment to other tools in the organization’s tech stack Consider how well the MLOps tool integrates with your existing tools and workflows, such as data sources, data engineering platforms, code repositories, CI/CD pipelines, monitoring systems, etc. and Pandas or Apache Spark DataFrames.
Data has become a driving force behind change and innovation in 2025, fundamentally altering how businesses operate. Across sectors, organizations are using advancements in artificial intelligence (AI), machine learning (ML), and data-sharing technologies to improve decision-making, foster collaboration, and uncover new opportunities.
However, while RPA and ML share some similarities, they differ in functionality, purpose, and the level of human intervention required. In this article, we will explore the similarities and differences between RPA and ML and examine their potential use cases in various industries. What is machine learning (ML)?
Beginner’s Guide to ML-001: Introducing the Wonderful World of Machine Learning: An Introduction Everyone is using mobile or web applications which are based on one or other machine learning algorithms. Machine learning(ML) is evolving at a very fast pace. Machine learning(ML) is evolving at a very fast pace.
Dataquality plays a significant role in helping organizations strategize their policies that can keep them ahead of the crowd. Hence, companies need to adopt the right strategies that can help them filter the relevant data from the unwanted ones and get accurate and precise output.
However, once deployed in a real-world setting, its performance plummeted due to dataquality issues and unforeseen biases. This scenario highlights a common reality in the Machine Learning landscape: despite the hype surrounding ML capabilities, many projects fail to deliver expected results due to various challenges.
Amazon Lookout for Metrics is a fully managed service that uses machine learning (ML) to detect anomalies in virtually any time-series business or operational metrics—such as revenue performance, purchase transactions, and customer acquisition and retention rates—with no ML experience required. To learn more, see the documentation.
As industries begin adopting processes dependent on machine learning (ML) technologies, it is critical to establish machine learning operations (MLOps) that scale to support growth and utilization of this technology. There were noticeable challenges when running ML workflows in the cloud.
Jacomo Corbo is a Partner and Chief Scientist, and Bryan Richardson is an Associate Partner and Senior Data Scientist, for QuantumBlack AI by McKinsey. They presented “Automating DataQuality Remediation With AI” at Snorkel AI’s The Future of Data-Centric AI Summit in 2022. The macro view will not be surprising.
Jacomo Corbo is a Partner and Chief Scientist, and Bryan Richardson is an Associate Partner and Senior Data Scientist, for QuantumBlack AI by McKinsey. They presented “Automating DataQuality Remediation With AI” at Snorkel AI’s The Future of Data-Centric AI Summit in 2022. The macro view will not be surprising.
Amazon DataZone makes it straightforward for engineers, data scientists, product managers, analysts, and business users to access data throughout an organization so they can discover, use, and collaborate to derive data-driven insights.
An AI database is not merely a repository of information but a dynamic and specialized system meticulously crafted to cater to the intricate demands of AI and ML applications. Herein lies the crux of the AI database’s significance: it is tailored to meet the intricate requirements that underpin the success of AI and ML endeavors.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content