This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This article was published as a part of the DataScience Blogathon. Introduction to DataWarehouseSQLDataWarehouse is also a cloud-based datawarehouse that uses Massively Parallel Processing (MPP) to run complex queries across petabytes of data rapidly. Import big […].
This article was published as a part of the DataScience Blogathon. Introduction Data from different sources are brought to a single location and then converted into a format that the datawarehouse can process and store. A boss may […].
ArticleVideo Book This article was published as a part of the DataScience Blogathon Introduction Datawarehouse generalizes and mingles data in multidimensional space. The post How to Build a DataWarehouse Using PostgreSQL in Python? appeared first on Analytics Vidhya.
This article was published as a part of the DataScience Blogathon. Introduction Amazon’s Redshift Database is a cloud-based large data warehousing solution. Companies may store petabytes of data in easy-to-access “clusters” that can be searched in parallel using the platform’s storage system.
SQL (Structured Query Language) is an important tool for data scientists. It is a programming language used to manipulate data stored in relational databases. Mastering SQL concepts allows a data scientist to quickly analyze large amounts of data and make decisions based on their findings.
In the contemporary age of Big Data, DataWarehouse Systems and DataScience Analytics Infrastructures have become an essential component for organizations to store, analyze, and make data-driven decisions. So why using IaC for Cloud Data Infrastructures?
This article was published as a part of the DataScience Blogathon. Introduction Big Query is a serverless enterprise datawarehouse service fully managed by Google. Big Query provides nearly real-time analytics of massive data.
This article was published as a part of the DataScience Blogathon. Introduction Apache Hive is a datawarehouse system built on top of Hadoop which gives the user the flexibility to write complex MapReduce programs in form of SQL- like queries.
The database is the major element of a datascience project. So, we are […] The post How to Normalize Relational Databases With SQL Code? To generate actionable insights, the database must be centralized and organized efficiently. appeared first on Analytics Vidhya.
This article was published as a part of the DataScience Blogathon What is the need for Hive? The official description of Hive is- ‘Apache Hive datawarehouse software project built on top of Apache Hadoop for providing data query and analysis.
This article was published as a part of the DataScience Blogathon. “Preponderance data opens doorways to complex and Avant analytics.” ” Introduction to SQL Queries Data is the premium product of the 21st century.
Conventional ML development cycles take weeks to many months and requires sparse datascience understanding and ML development skills. Business analysts’ ideas to use ML models often sit in prolonged backlogs because of data engineering and datascience team’s bandwidth and data preparation activities.
When it comes to data, there are two main types: data lakes and datawarehouses. What is a data lake? An enormous amount of raw data is stored in its original format in a data lake until it is required for analytics applications. Which one is right for your business? Let’s take a closer look.
This article was published as a part of the DataScience Blogathon Introduction Google’s BigQuery is an enterprise-grade cloud-native datawarehouse. Since its inception, BigQuery has evolved into a more economical and fully managed datawarehouse that can run lightning-fast […].
Continuous Integration and Continuous Delivery (CI/CD) for Data Pipelines: It is a Game-Changer with AnalyticsCreator! The need for efficient and reliable data pipelines is paramount in datascience and data engineering. It offers full BI-Stack Automation, from source to datawarehouse through to frontend.
This article was published as a part of the DataScience Blogathon. Introduction Hive is a popular datawarehouse built on top of Hadoop that is used by companies like Walmart, Tiktok, and AT&T. It is an important technology for data engineers to learn and master.
These experiences facilitate professionals from ingesting data from different sources into a unified environment and pipelining the ingestion, transformation, and processing of data to developing predictive models and analyzing the data by visualization in interactive BI reports.
Introduction Dedicated SQL pools offer fast and reliable data import and analysis, allowing businesses to access accurate insights while optimizing performance and reducing costs. DWUs (DataWarehouse Units) can customize resources and optimize performance and costs.
The field of datascience is now one of the most preferred and lucrative career options available in the area of data because of the increasing dependence on data for decision-making in businesses, which makes the demand for datascience hires peak.
Microsoft just held one of its largest conferences of the year, and a few major announcements were made which pertain to the cloud datascience world. Azure Synapse Analytics can be seen as a merge of Azure SQLDataWarehouse and Azure Data Lake. Those are the big datascience announcements of the week.
While not all of us are tech enthusiasts, we all have a fair knowledge of how DataScience works in our day-to-day lives. All of this is based on DataScience which is […]. The post Step-by-Step Roadmap to Become a Data Engineer in 2023 appeared first on Analytics Vidhya.
Thats where data normalization comes in. Its a structured process that organizes data to reduce redundancy and improve efficiency. Whether you’re working with relational databases, datawarehouses , or machine learning pipelines, normalization helps maintain clean, accurate, and optimized datasets. Simple, right?
The main solutions on the market are decentralized file storage networks (DSFN) like Filecoin and Arweave, and decentralized datawarehouses like Space and Time (SxT). Built to seamlessly integrate with existing enterprise systems, the datawarehouse lets businesses tap into blockchain data while publishing query results back on-chain.
In the process of working on their ML tasks, data scientists typically start their workflow by discovering relevant data sources and connecting to them. They then use SQL to explore, analyze, visualize, and integrate data from various sources before using it in their ML training and inference.
Data engineering tools offer a range of features and functionalities, including data integration, data transformation, data quality management, workflow orchestration, and data visualization. Essential data engineering tools for 2023 Top 10 data engineering tools to watch out for in 2023 1.
Though you may encounter the terms “datascience” and “data analytics” being used interchangeably in conversations or online, they refer to two distinctly different concepts. Meanwhile, data analytics is the act of examining datasets to extract value and find answers to specific questions.
With its decoupled compute and storage resources, Snowflake is a cloud-native data platform optimized to scale with the business. Dataiku is an advanced analytics and machine learning platform designed to democratize datascience and foster collaboration across technical and non-technical teams.
Dating back to the 1970s, the data warehousing market emerged when computer scientist Bill Inmon first coined the term ‘datawarehouse’. Created as on-premise servers, the early datawarehouses were built to perform on just a gigabyte scale. Big data and data warehousing.
In many of the conversations we have with IT and business leaders, there is a sense of frustration about the speed of time-to-value for big data and datascience projects. We often hear that organizations have invested in datascience capabilities but are struggling to operationalize their machine learning models.
In this blog post, we will be discussing 7 tips that will help you become a successful data engineer and take your career to the next level. Learn SQL: As a data engineer, you will be working with large amounts of data, and SQL is the most commonly used language for interacting with databases.
Discover the nuanced dissimilarities between Data Lakes and DataWarehouses. Data management in the digital age has become a crucial aspect of businesses, and two prominent concepts in this realm are Data Lakes and DataWarehouses. It acts as a repository for storing all the data.
While datascience and machine learning are related, they are very different fields. In a nutshell, datascience brings structure to big data while machine learning focuses on learning from the data itself. What is datascience? This post will dive deeper into the nuances of each field.
In this article, we will delve into the concept of data lakes, explore their differences from datawarehouses and relational databases, and discuss the significance of data version control in the context of large-scale data management. Schema Enforcement: Datawarehouses use a “schema-on-write” approach.
This tool democratizes data access across the organization, enabling even nontechnical users to gain valuable insights. A standout application is the SQL-to-natural language capability, which translates complex SQL queries into plain English and vice versa, bridging the gap between technical and business teams.
In this post, we discuss a Q&A bot use case that Q4 has implemented, the challenges that numerical and structured datasets presented, and how Q4 concluded that using SQL may be a viable solution. This would have required a dedicated cross-disciplinary team with expertise in datascience, machine learning, and domain knowledge.
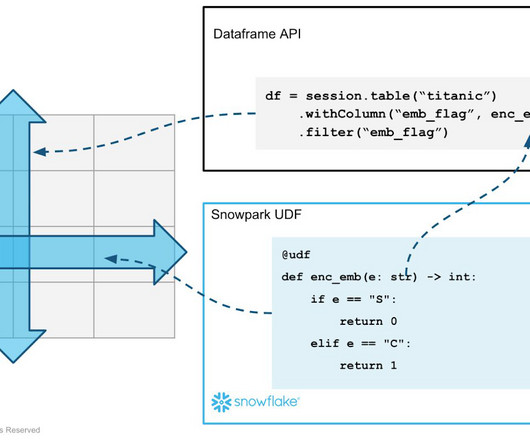
In this blog, we will dive deeper into the capabilities of Snowpark for Python and how combining with Hex supports datascience by providing faster and more efficient data processing and analytics capabilities on top of Hex’s easy notebook collaboration and sharing. How Does Snowpark Enable DataScience?
The blog post explains how the Internal Cloud Analytics team leveraged cloud resources like Code-Engine to improve, refine, and scale the data pipelines. Background One of the Analytics teams tasks is to load data from multiple sources and unify it into a datawarehouse. Thus, it has only a minimal footprint.
Unified data storage : Fabric’s centralized data lake, Microsoft OneLake, eliminates data silos and provides a unified storage system, simplifying data access and retrieval. Flexible compute capacity One of the key advantages of Microsoft Fabric is its ability to optimize compute capacity across different workloads.
With Great Expectations , data teams can express what they “expect” from their data using simple assertions. Great Expectations provides support for different data backends such as flat file formats, SQL databases, Pandas dataframes and Sparks, and comes with built-in notification and data documentation functionality.
Data engineers are essential professionals responsible for designing, constructing, and maintaining an organization’s data infrastructure. They create data pipelines, ETL processes, and databases to facilitate smooth data flow and storage. Role of Data Scientists Data Scientists are the architects of data analysis.
Space and Time’s creator SxT Labs has created three technologies that underpin its verifiable compute layer, including a blockchain indexer, a distributed datawarehouse and a zero-knowledge coprocessor.
Be sure to check out her talk, “ Scaling your DataScience Workflows by Changing a Single Line of Code ,” there! pandas is one of the most popular datascience libraries today. It is also the de-facto datascience library taught in almost all introductory datascience courses and bootcamps.
Datascience is both a rewarding and challenging profession. One study found that 44% of companies that hire data scientists say the departments are seriously understaffed. Fortunately, data scientists can make due with fewer staff if they use their resources more efficiently, which involves leveraging the right tools.
These professionals will work with their colleagues to ensure that data is accessible, with proper access. So let’s go through each step one by one, and help you build a roadmap toward becoming a data engineer. Identify your existing datascience strengths. Stay on top of data engineering trends. Get more training!
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content