This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Navigating the realm of datascience careers is no longer a tedious task. In the current landscape, datascience has emerged as the lifeblood of organizations seeking to gain a competitive edge. They require strong programming skills, expertise in data processing, and knowledge of database management.
Summary: Big Data refers to the vast volumes of structured and unstructured data generated at high speed, requiring specialized tools for storage and processing. DataScience, on the other hand, uses scientific methods and algorithms to analyses this data, extract insights, and inform decisions.
The field of datascience is now one of the most preferred and lucrative career options available in the area of data because of the increasing dependence on data for decision-making in businesses, which makes the demand for datascience hires peak.
Summary: Python for DataScience is crucial for efficiently analysing large datasets. Introduction Python for DataScience has emerged as a pivotal tool in the data-driven world. Key Takeaways Python’s simplicity makes it ideal for Data Analysis. in 2022, according to the PYPL Index.
Though you may encounter the terms “datascience” and “data analytics” being used interchangeably in conversations or online, they refer to two distinctly different concepts. Meanwhile, data analytics is the act of examining datasets to extract value and find answers to specific questions.
With its decoupled compute and storage resources, Snowflake is a cloud-native data platform optimized to scale with the business. Dataiku is an advanced analytics and machine learning platform designed to democratize datascience and foster collaboration across technical and non-technical teams.
DataScience is a popular as well as vast field; till date, there are a lot of opportunities in this field, and most people, whether they are working professionals or students, everyone want a transition in datascience because of its scope. How much to learn? What to do next?
One of the most demanding fields in the business world today is of DataScience. With numerous job opportunities, DataScience skills have become essential in the market. The easiest skill that a DataScience aspirant might develop is SQL. SQL is the standard language that relational databases uses.
For budding data scientists and data analysts, there are mountains of information about why you should learn R over Python and the other way around. Though both are great to learn, what gets left out of the conversation is a simple yet powerful programming language that everyone in the datascience world can agree on, SQL.
Like any skill, there are some core skills you need to know before getting into datascience. Without basic foundational skills, your datascience journey will end as quickly as it begins. SQL Databases might sound scary, but honestly, they’re not all that bad. Learning is learning.
Summary : This article equips Data Analysts with a solid foundation of key DataScience terms, from A to Z. Introduction In the rapidly evolving field of DataScience, understanding key terminology is crucial for Data Analysts to communicate effectively, collaborate effectively, and drive data-driven projects.
These professionals will work with their colleagues to ensure that data is accessible, with proper access. So let’s go through each step one by one, and help you build a roadmap toward becoming a data engineer. Identify your existing datascience strengths. Stay on top of data engineering trends. Get more training!
With technological developments occurring rapidly within the world, Computer Science and DataScience are increasingly becoming the most demanding career choices. Moreover, with the oozing opportunities in DataScience job roles, transitioning your career from Computer Science to DataScience can be quite interesting.
Data Primer Available On-Demand Data is the essential building block of datascience, machine learning, and learning AI. This course is designed to teach you the foundational skills and knowledge required to understand, work with, and analyze data. You’ll also have access to the recordings on-demand.
ODSC Bootcamp Primer: DataWrangling with SQL Course January 25th @ 2PM EST This SQL coding course teaches students the basics of Structured Query Language, which is a standard programming language used for managing and manipulating data and an essential tool in AI.
What is DataScience? DataScience is the field of extracting data from large volumes of datasets and transformed into meaningful insights so that effective decision-making takes place. Based on the lucrative opportunities, many of you are aspiring to become DataScience experts and want to learn DataScience.
As the sibling of datascience, data analytics is still a hot field that garners significant interest. Companies have plenty of data at their disposal and are looking for people who can make sense of it and make deductions quickly and efficiently. Cloud Services: Google Cloud Platform, AWS, Azure.
There will also be an in-person career expo where you can find your next job in datascience! See what’s trending in datascience, take a deep dive into LLMs and Generative AI, upskill or start new skills, and connect with people from around the country! What’s next? We’ve got a lot planned for ODSC West 2023.
DataScience has emerged as one of the most prominent and demanding prospects in the with millions of job roles coming up in the market. Pursuing a career in DataScience can be highly promising and you can become a DataScience even without having prior knowledge on technical concepts.
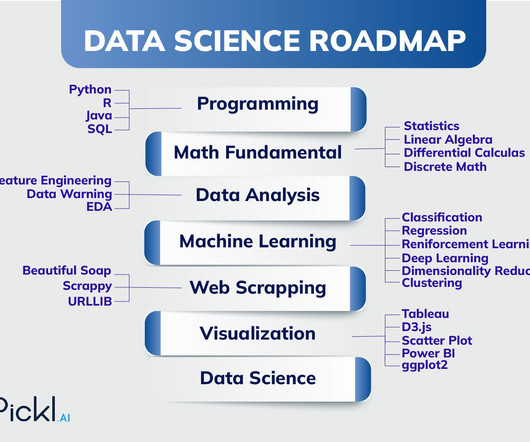
Companies are looking forward to hiring crème de la crème Data Scientists. This guide throws light on the roadmap to becoming a Data Scientist. Key Takeaways: DataScience is a multidisciplinary field bridging statistics, mathematics, and computer science to extract insights from data.
In this article we will provide a brief introduction to Pandas, one of the most famous Python libraries for DataScience and Machine learning. Introduction to Pandas – The fundamentals Pandas is a popular and powerful open-source data analysis and manipulation library for the Python programming language. Hello dear reader!
Introduction In the realm of databases, where information reigns supreme, attributes are the fundamental building blocks. They act as the defining characteristics of entities, providing the details that breathe life into our data. Check Out: Top DBMS Interview Questions and Answers Unveiling the Essence of Attributes Imagine a library.
Humans and machines Data scientists and analysts need to be aware of how this technology will affect their role, their processes, and their relationships with other stakeholders. There are clearly aspects of datawrangling that AI is going to be good at. Chat interfaces can be viewed as another step up the ladder of abstraction.
Cross-Column Analysis: Explore relationships between columns to uncover potential data dependencies or correlations. Identify potential foreign key relationships between tables in a relational database. Data Distribution Analysis: Create histograms, box plots, or scatter plots to visualize data distributions and relationships.
Agentic Systems for Competitive Intelligence: Enhancing Business Decision-Making Lets explore how Agentic systems can autonomously collect and filter relevant data while conducting sophisticated pattern analysis to draw preliminary conclusions and generate actionable insights.
They design intricate sequences of prompts, leveraging their knowledge of AI, machine learning, and datascience to guide powerful LLMs (Large Language Models) towards complex tasks. Datascience methodologies and skills can be leveraged to design these experiments, analyze results, and iteratively improve prompt strategies.
This is the data at the source step (the first step in the right hand side) before any datawrangling. This is to improve the data loading performance. And, this is not only for SQL queries but also works for MongoDB queries and other datawrangling steps such as Filter, Create Calculation, etc. ?
It’s everywhere such as Excel, database, etc. Exploratory Website If then do A else do B — ifelse function in R & Exploratory was originally published in learn datascience on Medium, where people are continuing the conversation by highlighting and responding to this story. Basics The ifelse function takes 3 arguments.
Jupyter notebooks have been one of the most controversial tools in the datascience community. Nevertheless, many data scientists will agree that they can be really valuable – if used well. I’ll show you best practices for using Jupyter Notebooks for exploratory data analysis. documentation.
This blog will delve into ETL Tools, exploring the top contenders and their roles in modern data integration. Let’s unlock the power of ETL Tools for seamless data handling. Also Read: Top 10 DataScience tools for 2024. It is a process for moving and managing data from various sources to a central data warehouse.
Velocity It indicates the speed at which data is generated and processed, necessitating real-time analytics capabilities. Businesses need to analyse data as it streams in to make timely decisions. This diversity requires flexible data processing and storage solutions.
LLMs, AI agents, and generative AI are the buzzwords lighting up the datascience world. Because no modelno matter how powerfulcan perform well on poorly prepared data or without a solid development pipeline based on AIbasics. DataWrangling: Taming the RawData Why it matters : Real-world data is messy.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






































Let's personalize your content