This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In contemporary times, datascience has emerged as a substantial and progressively expanding domain that has an impact on virtually every sphere of human ingenuity: be it commerce, technology, healthcare, education, governance, and beyond. This piece will concentrate on the elemental constituents constituting datascience.
By making your models accessible, you enable a wider range of users to benefit from the predictive capabilities of machine learning, driving decision-making processes and generating valuable outcomes. They work by dividing the data into smaller and smaller groups until each group can be classified with a high degree of accuracy.
Image Credit: Pinterest – Problem solving tools In last week’s post , DS-Dojo introduced our readers to this blog-series’ three focus areas, namely: 1) software development, 2) project-management, and 3) datascience. This week, we continue that metaphorical (learning) journey with a fun fact. Better yet, a riddle. IoT, Web 3.0,
In this blog, we will discuss one of the feature transformation techniques called feature scaling with examples and see how it will be the game changer for our machine learning model accuracy. In the world of datascience and machine learning, feature transformation plays a crucial role in achieving accurate and reliable results.
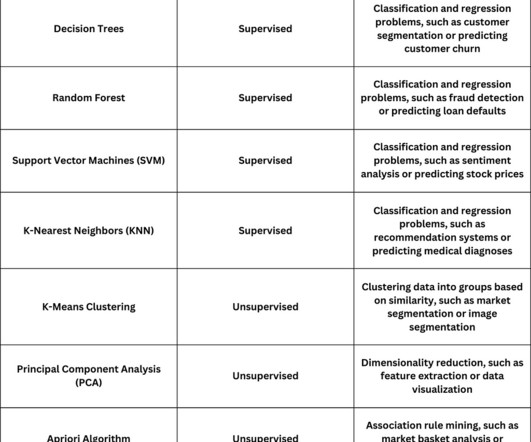
Some common models used are as follows: Logistic Regression – it classifies by predicting the probability of a data point belonging to a class instead of a continuous value DecisionTrees – uses a tree structure to make predictions by following a series of branching decisionsSupportVectorMachines (SVMs) – create a clear decision (..)
It identifies hidden patterns in data, making it useful for decision-making across industries. Compared to decisiontrees and SVM, it provides interpretable rules but can be computationally intensive. Key applications include fraud detection, customer segmentation, and medical diagnosis.
decisiontrees, supportvector regression) that can model even more intricate relationships between features and the target variable. SupportVectorMachines (SVM): This algorithm finds a hyperplane that best separates data points of different classes in high-dimensional space.
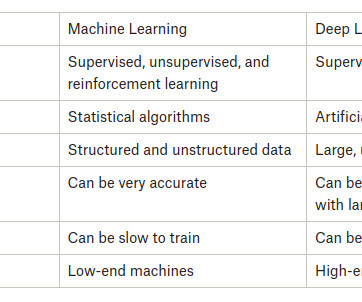
While datascience and machine learning are related, they are very different fields. In a nutshell, datascience brings structure to big data while machine learning focuses on learning from the data itself. What is datascience? What is machine learning?
R has simplified the most complex task of geospatial machine learning and datascience. As GIS is slowly embracing datascience, mastery of programming is very necessary regardless of your perception of programming. data = trainData) 5.
Demand forecasting, powered by datascience, helps predict customer needs. Optimize inventory, streamline operations, and make data-driven decisions for success. DataScience empowers businesses to leverage the power of data for accurate and insightful demand forecasts.
In data mining, popular algorithms include decisiontrees, supportvectormachines, and k-means clustering. This is similar as you consider many factors while you pay someone for essay , which may include referencing, evidence-based argument, cohesiveness, etc.
DataScience interviews are pivotal moments in the career trajectory of any aspiring data scientist. Having the knowledge about the datascience interview questions will help you crack the interview. DataScience skills that will help you excel professionally.
Summary : This article equips Data Analysts with a solid foundation of key DataScience terms, from A to Z. Introduction In the rapidly evolving field of DataScience, understanding key terminology is crucial for Data Analysts to communicate effectively, collaborate effectively, and drive data-driven projects.
Summary: In the tech landscape of 2024, the distinctions between DataScience and Machine Learning are pivotal. DataScience extracts insights, while Machine Learning focuses on self-learning algorithms. The collective strength of both forms the groundwork for AI and DataScience, propelling innovation.
Machine learning is playing a very important role in improving the functionality of task management applications. In January, Towards DataScience published an article on this very topic. “In Project managers should be aware of the changes that machine learning has brought to task management applications.
Feature Engineering Encoding categorical data is a crucial part of feature engineering, which involves creating features that make ML models more effective. Learn about 101 ML algorithms for datascience with cheat sheets 5. Effective feature engineering, including proper encoding, can significantly enhance model performance.
With the expanding field of DataScience, the need for efficient and skilled professionals is increasing. Its efficacy may allow kids from a young age to learn Python and explore the field of DataScience. Its efficacy may allow kids from a young age to learn Python and explore the field of DataScience.
Summary: The blog explores the synergy between Artificial Intelligence (AI) and DataScience, highlighting their complementary roles in Data Analysis and intelligent decision-making. This article explores how AI and DataScience complement each other, highlighting their combined impact and potential.
Hey guys, in this blog we will see some of the most asked DataScience Interview Questions by interviewers in [year]. Datascience has become an integral part of many industries, and as a result, the demand for skilled data scientists is soaring. What is DataScience?
Mastering Tree-Based Models in Machine Learning: A Practical Guide to DecisionTrees, Random Forests, and GBMs Image created by the author on Canva Ever wondered how machines make complex decisions? Just like a tree branches out, tree-based models in machine learning do something similar.
What is machine learning? ML is a computer science, datascience and artificial intelligence (AI) subset that enables systems to learn and improve from data without additional programming interventions. Here, we’ll discuss the five major types and their applications.
For larger datasets, more complex algorithms such as Random Forest, SupportVectorMachines (SVM), or Neural Networks may be more suitable. ▶ Type of Data : The type of data you have can also affect the choice of the classification algorithm. ⚠ Bonus tip ⚠ Always start with KNN!!!!!!! .
Common Machine Learning Algorithms Machine learning algorithms are not limited to those mentioned below, but these are a few which are very common. Linear Regression DecisionTreesSupportVectorMachines Neural Networks Clustering Algorithms (e.g.,
Machine Learning is a subset of Artificial Intelligence and Computer Science that makes use of data and algorithms to imitate human learning and improving accuracy. Being an important component of DataScience, the use of statistical methods are crucial in training algorithms in order to make classification.
Examples of supervised learning models include linear regression, decisiontrees, supportvectormachines, and neural networks. Common examples include: Linear Regression: It is the best Machine Learning model and is used for predicting continuous numerical values based on input features.
Correctly predicting the tags of the questions is a very challenging problem as it involves the prediction of a large number of labels among several hundred thousand possible labels.
You can start with simpler algorithms such as decisiontrees, Naive Bayes , and logistic regression, and steadily move to more complex ones like neural networks and supportvectormachines (SVM). Experiment and evaluate: Implement the algorithms you have selected and evaluate their performance on your data.
What makes it popular is that it is used in a wide variety of fields, including datascience, machine learning, and computational physics. Without this library, data analysis wouldn’t be the same without pandas, which reign supreme with its powerful data structures and manipulation tools. Not a bad list right?
These algorithms are carefully selected based on the specific decision problem and are trained using the prepared data. Machine learning algorithms, such as neural networks or decisiontrees, learn from the data to make predictions or generate recommendations.
Anomalies are not inherently bad, but being aware of them, and having data to put them in context, is integral to understanding and protecting your business. The challenge for IT departments working in datascience is making sense of expanding and ever-changing data points.
The datascience job market is rapidly evolving, reflecting shifts in technology and business needs. Heres what we noticed from analyzing this data, highlighting whats remained the same over the years, and what additions help make the modern data scientist in2025. Joking aside, this does infer particular skills.
Before we discuss the above related to kernels in machine learning, let’s first go over a few basic concepts: SupportVectorMachine , S upport Vectors and Linearly vs. Non-linearly Separable Data. The linear kernel is suitable for use when the data is linearly separable. Support-vector networks.
NRE is a complex task that involves multiple steps and requires sophisticated machine learning algorithms like Hidden Markov Models (HMMs) , Conditional Random Fields (CRFs), and SupportVectorMachines (SVMs) be present. We’re committed to supporting and inspiring developers and engineers from all walks of life.
They identify patterns in existing data and use them to predict unknown events. Techniques like linear regression, time series analysis, and decisiontrees are examples of predictive models. In more complex cases, you may need to explore non-linear models like decisiontrees, supportvectormachines, or time series models.
Feel free to try other algorithms such as Random Forests, DecisionTrees, Neural Networks, etc., among supervised models and k-nearest neighbors, DBSCAN, etc., among unsupervised models.
Background Information Decisiontrees, random forests, and linear regression are just a few examples of classic machine-learning models that have been used extensively in business for years. The n_estimators argument is set to 100, meaning that 100 decisiontrees will be used in the forest.
R: R is a programming language that is widely used in datascience and AI development. R provides a range of libraries and tools that make it easier to analyze and visualize data. Data preprocessing: Preprocess the data to identify and remove biases, such as gender or race bias.
Model Complexity Machine Learning : Traditional machine learning models have fewer parameters and a simpler structure than deep learning models. They typically rely on simpler algorithms like decisiontrees, supportvectormachines, or linear regression.
Machine Learning and Neural Networks (1990s-2000s): Machine Learning (ML) became a focal point, enabling systems to learn from data and improve performance without explicit programming. Techniques such as decisiontrees, supportvectormachines, and neural networks gained popularity.
DecisionTrees These trees split data into branches based on feature values, providing clear decision rules. SupportVectorMachines (SVM) SVMs are powerful classifiers that separate data into distinct categories by finding an optimal hyperplane.
They process data, identify patterns, and adjust the model accordingly. Common algorithms include decisiontrees, neural networks, and supportvectormachines. Data : Data serves as the foundation for ML.
Students should learn how to leverage Machine Learning algorithms to extract insights from large datasets. Key topics include: Supervised Learning Understanding algorithms such as linear regression, decisiontrees, and supportvectormachines, and their applications in Big Data.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content