This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This article was published as a part of the DataScience Blogathon Overview 1. Rapid Automatic Keyword Extraction(RAKE) is a Domain-Independent keyword extraction algorithm in NaturalLanguageProcessing. It is an Individual document-oriented dynamic Information retrieval method.
This article was published as a part of the DataScience Blogathon Overview Sentence classification is one of the simplest NLP tasks that have a wide range of applications including document classification, spam filtering, and sentiment analysis. A sentence is classified into a class in sentence classification.
However, it: Validates input data automatically Returns meaningful responses with prediction confidence Logs every request to a file (api.log) Uses background tasks so the API stays fast and responsive Handles failures gracefully And all of it in under 100 lines of code. She co-authored the ebook "Maximizing Productivity with ChatGPT".
Step 1: Choose a Topic To we will start by selecting a topic within the fields of AI, machine learning, or datascience. Step 4: Leverage NotebookLM’s Tools Audio Overview This feature converts your document, slides, or PDFs into a dynamic, podcast-style conversation with two AI hosts that summarize and connect key points.
By combining pre-trained models with external knowledge sources, RAG systems provide accurate, up-to-date information while maintaining the naturallanguage capabilities of foundation models. Architecture Patterns : Simple RAG systems retrieve relevant documents and include them in prompts for context.
By Cornellius Yudha Wijaya , KDnuggets Technical Content Specialist on June 18, 2025 in DataScience Image by Author As a data scientist, Jupyter Notebook has become one of the first platforms we learn to use, as it allows for easier data manipulation compared to standard programming IDEs.
This article was published as a part of the DataScience Blogathon Introduction Analyzing texts is far more complicated than analyzing typical tabulated data (e.g. retail data) because texts fall under unstructured data. Different people express themselves quite differently when it comes to […].
Blog Top Posts About Topics AI Career Advice Computer Vision Data Engineering DataScienceLanguage Models Machine Learning MLOps NLP Programming Python SQL Datasets Events Resources Cheat Sheets Recommendations Tech Briefs Advertise Join Newsletter Go vs. Python for Modern Data Workflows: Need Help Deciding?
Data scientists use different tools for tasks like data visualization, data modeling, and even warehouse systems. Like this, AI has changed datascience from A to Z. If you are in the way of searching for jobs related to datascience, you probably heard the term RAG. What is a retriever?
Version Control : Maintain version control for code, data, and models. Document and Test : Keep thorough documentation and perform unit tests on ML workflows. Standardize Workflows : Use MLFlow Projects to ensure reproducibility. Monitor Models : Continuously track performance metrics for production models.
We’ll explore the specifics of DataScience Dojo’s LLM Bootcamp and why enrolling in it could be your first step in mastering LLM technology. It covers a range of topics including generative AI, LLM basics, naturallanguageprocessing, vector databases, prompt engineering, and much more.
Documentation Updates: Automatically update documentation based on code changes. Currently, he is focusing on content creation and writing technical blogs on machine learning and datascience technologies. Issue Triage: Analyze issues, categorize them, and suggest or implement fixes.
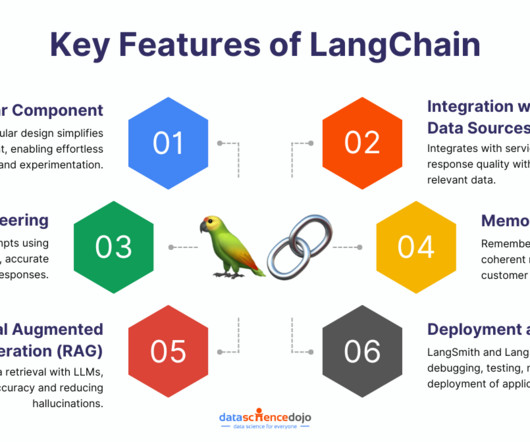
It will be used to extract the text from PDF files LangChain: A framework to build context-aware applications with language models (we’ll use it to process and chain document tasks). It will be used to process and organize the text properly.
You can find the complete installation guide in the official DuckDB documentation. He graduated in physics engineering and is currently working in the datascience field applied to human mobility. He is a part-time content creator focused on datascience and technology.
PDF Data Extraction: Upload a document, highlight the fields you need, and Magical AI will transfer them into online forms or databases, saving you hours of tedious work. You can find detailed step-by-step for many different workflows in Magical AIs own documentation. It even learns your tone over time.
Blog Top Posts About Topics AI Career Advice Computer Vision Data Engineering DataScienceLanguage Models Machine Learning MLOps NLP Programming Python SQL Datasets Events Resources Cheat Sheets Recommendations Tech Briefs Advertise Join Newsletter 10 FREE AI Tools That’ll Save You 10+ Hours a Week No tech skills needed.
Since some of these requests can lead to dangerous irreversible changes, like the deletion of critical data, we have had to actively pass the allow_dangerous_requests parameter to enable these. You can find more details about necessary headers in your API documentation. This is a simple step.
Here is the link to the data project we’ll be using in this article. It’s a data project from Uber called Partner’s Business Modeling. Uber used this data project in the recruitment process for the datascience positions, and you will be asked to analyze the data for two different scenarios.
An approach to requirements definition for vibe coding is using a language model to help produce a production requirements document (PRD). Look up the documentation for the functions it used. His professional interests include naturallanguageprocessing, language models, machine learning algorithms, and exploring emerging AI.
Traditional methods of understanding code structures involve reading through numerous files and documentation, which can be time-consuming and error-prone. Kanwal Mehreen Kanwal is a machine learning engineer and a technical writer with a profound passion for datascience and the intersection of AI with medicine.
This article was published as a part of the DataScience Blogathon. Introduction In the field of NaturalLanguageProcessing i.e., NLP, Lemmatization and Stemming are Text Normalization techniques. These techniques are used to prepare words, text, and documents for further processing.
Once the logs indicate that the server is running and ready, you can explore the automatically generated API documentation here. This interactive documentation provides details about all available endpoints and allows you to test them directly from your browser.
Downloading files for months until your desktop or downloads folder becomes an archaeological dig site of documents, images, and videos. Features to include: Auto-categorization by file type (documents, images, videos, etc.) She likes working at the intersection of math, programming, datascience, and content creation.
Blog Top Posts About Topics AI Career Advice Computer Vision Data Engineering DataScienceLanguage Models Machine Learning MLOps NLP Programming Python SQL Datasets Events Resources Cheat Sheets Recommendations Tech Briefs Advertise Join Newsletter 5 Ways to Transition Into AI from a Non-Tech Background You have a non-tech background?
Step 1: Cover the Fundamentals You can skip this step if you already know the basics of programming, machine learning, and naturallanguageprocessing. Step 2: Understand Core Architectures Behind Large Language Models Large language models rely on various architectures, with transformers being the most prominent foundation.
Cursor AI If you use Cursor for coding or editing, integrating multiple MCP servers has become essential for boosting its capabilities—giving you easy access to the web, databases, documentation, APIs, and external services. Abid holds a Masters degree in technology management and a bachelors degree in telecommunication engineering.
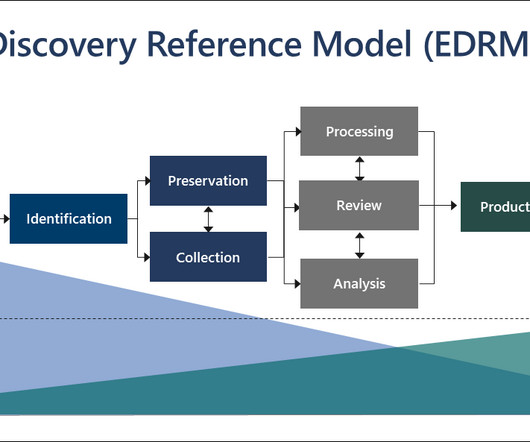
It is the process of identifying, collecting, and producing electronically stored information (ESI) in response to a request for production in a lawsuit or investigation. Anyhow, with the exponential growth of digital data, manual document review can be a challenging task.
LlamaIndex is an orchestration framework for large language model (LLM) applications. LLMs like GPT-4 are pre-trained on massive public datasets, allowing for incredible naturallanguageprocessing capabilities out of the box. However, their utility is limited without access to your own private or domain-specific data.
Introduction Transformers are revolutionizing naturallanguageprocessing, providing accurate text representations by capturing word relationships. The adaptability of transformers makes these models invaluable for handling various document formats. Applications span industries like law, finance, and academia.
Traditional keyword-based search mechanisms are often insufficient for locating relevant documents efficiently, requiring extensive manual review to extract meaningful insights. This solution improves the findability and accessibility of archival records by automating metadata enrichment, document classification, and summarization.
Blog Top Posts About Topics AI Career Advice Computer Vision Data Engineering DataScienceLanguage Models Machine Learning MLOps NLP Programming Python SQL Datasets Events Resources Cheat Sheets Recommendations Tech Briefs Advertise Join Newsletter 7 Popular LLMs Explained in 7 Minutes Get a quick overview of GPT, BERT, LLaMA, and more!
10+ Python packages for NaturalLanguageProcessing that you can’t miss, along with their corresponding code.Foto di Max Duzij su Unsplash NaturalLanguageProcessing is the field of Artificial Intelligence that involves text analysis. It combines statistics and mathematics with computational linguistics.
NaturalLanguageProcessing Applications : Develops and refines NLP applications, ensuring they can handle language tasks effectively, such as sentiment analysis and question answering. HELM contributes to the development of AI systems that can assist in decision-making processes.
In the field of software development, generative AI is already being used to automate tasks such as code generation, bug detection, and documentation. For example: Prompt: “Recommend a library for naturallanguageprocessing.” Prompt: "Generate documentation for the following function."
Sign Up for the Cloud DataScience Newsletter. Amazon Comprehend launches real-time classification Amazon Comprehend is a service which uses NaturalLanguageProcessing (NLP) to examine documents. Comprehend can now be used to classify documents in real-time. We will have to wait and see.
Over the past few years, a shift has shifted from NaturalLanguageProcessing (NLP) to the emergence of Large Language Models (LLMs). This evolution is fueled by the exponential expansion of available data and the successful implementation of the Transformer architecture.
The UAE’s commitment to developing cutting-edge technology like NOOR and Falcon demonstrates its determination to be a global leader in the field of AI and naturallanguageprocessing. This initiative addresses the gap in the availability of advanced language models for Arabic speakers.
As a global leader in agriculture, Syngenta has led the charge in using datascience and machine learning (ML) to elevate customer experiences with an unwavering commitment to innovation. It facilitates real-time data synchronization and updates by using GraphQL APIs, providing seamless and responsive user experiences.
Data scientists are continuously advancing with AI tools and technologies to enhance their capabilities and drive innovation in 2024. The integration of AI into datascience has revolutionized the way data is analyzed, interpreted, and utilized. – Example: Data scientists can employ H2O.ai
For example, if you’re building a chatbot, you can combine modules for naturallanguageprocessing (NLP), data retrieval, and user interaction. RAG Workflows RAG is a technique that helps LLMs fetch relevant information from external databases or documents to ground their responses in reality.
Looking back ¶ When we started DrivenData in 2014, the application of datascience for social good was in its infancy. There was rapidly growing demand for datascience skills at companies like Netflix and Amazon. Weve run 75+ datascience competitions awarding more than $4.7
Tools like LangChain , combined with a large language model (LLM) powered by Amazon Bedrock or Amazon SageMaker JumpStart , simplify the implementation process. Implementation includes the following steps: The first step is to break down the large document, such as a book, into smaller sections, or chunks.
Unlocking efficient legal document classification with NLP fine-tuning Image Created by Author Introduction In today’s fast-paced legal industry, professionals are inundated with an ever-growing volume of complex documents — from intricate contract provisions and merger agreements to regulatory compliance records and court filings.
Healthcare system faces persistent challenges due to its heavy reliance on manual processes and fragmented communication. Providers struggle with the administrative burden of documentation and coding, which consumes 2531% of total healthcare spending and detracts from their ability to deliver quality care.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content