This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This article was published as a part of the DataScience Blogathon. Table of Contents Introduction Working with dataset Creating loss dataframe Visualizations Analysis from Heatmap Overall Analysis Conclusion Introduction In this article, I am going to perform Exploratory Data Analysis on the Sample Superstore dataset.
ChatGPT plugins can be used to extend the capabilities of ChatGPT in a variety of ways, such as: Accessing and processing external data Performing complex computations Using third-party services In this article, we’ll dive into the top 6 ChatGPT plugins tailored for datascience.
Summary: Python for DataScience is crucial for efficiently analysing large datasets. Introduction Python for DataScience has emerged as a pivotal tool in the data-driven world. Key Takeaways Python’s simplicity makes it ideal for Data Analysis. in 2022, according to the PYPL Index.
Whether you’re a data scientist aiming to deepen your expertise in NLP or a machine learning engineer interested in domain-specific model fine-tuning, this tutorial will equip you with the tools and insights you need to get started. For this tutorial, we’ll download and prepare the dataset using Hugging Face’s datasets library.
Photo by Luke Chesser on Unsplash EDA is a powerful method to get insights from the data that can solve many unsolvable problems in business. In the increasingly competitive world, understanding the data and taking quicker actions based on that help create differentiation for the organization to stay ahead!
This article seeks to also explain fundamental topics in datascience such as EDA automation, pipelines, ROC-AUC curve (how results will be evaluated), and Principal Component Analysis in a simple way. One important stage of any data analysis/science project is EDA. Exploratory Data Analysis is a pre-study.
We give recommendations and examples below, with instructors of college or graduate level datascience or applied statistics courses in mind. Variations: For practice with data wrangling, students can find, download, and prepare data for analysis as part of the assignment. Difficulty: All skill levels.
How to create a DataScience Project on GitHub? DataScience being the most demanding career fields today with millions of job opportunities flooding in the market. in order to ensure that you have a great career in DataScience, one of the major requirements is to create and have a Github DataScience project.
Photo by Artem Beliaikin on Unsplash Recently, I worked on a prediction case study using the Kaggle Black Friday Prediction dataset, which was created six years ago and has been downloaded over 32,000 times. Let’s skip over the EDA.
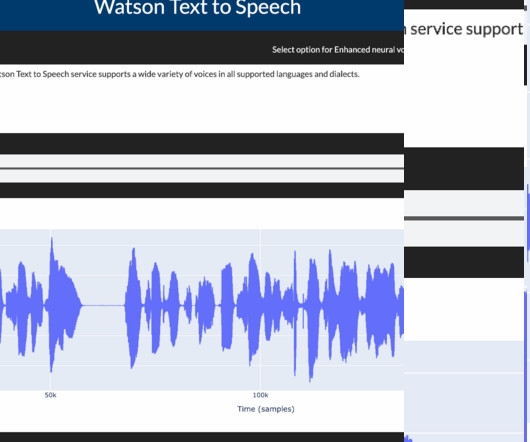
Data Processing and EDA (Exploratory Data Analysis) Speech synthesis services require that the data be in a JSON format. TTS app speech data output Conclusion This blog showed how you could easily use the Watson Speech Library to convert text to speech and control digital speech and pitch rates.
Those researches are often conducted on easily available benchmark datasets which you can easily download, often with corresponding ground truth data (label data) necessary for training. 7, Dealing with lack of labels in a single domain In many cases, data themselves are easily available, and only annotations costs matter.
This report took the data set provided in the challenge, as well as external data feeds and alternative sources. In the link above, you will find great detail in data visualization, script explanation, use of neural networks, and several different iterations of predictive analytics for each category of NFL player.
Objectives The challenge embraced several data analysis dimensions: from data cleaning and exploratory data analysis (EDA) to insightful data visualization and predictive modeling. To accompany so many high-value reports, the Ocean Data Challenge team approved allowing all 5 submissions to enter the podium finish.
Exploratory Data Analysis on Stock Market Data Photo by Lukas Blazek on Unsplash Exploratory Data Analysis (EDA) is a crucial step in datascience projects. It helps in understanding the underlying patterns and relationships in the data. The dataset can be downloaded from Kaggle. csv') 2.
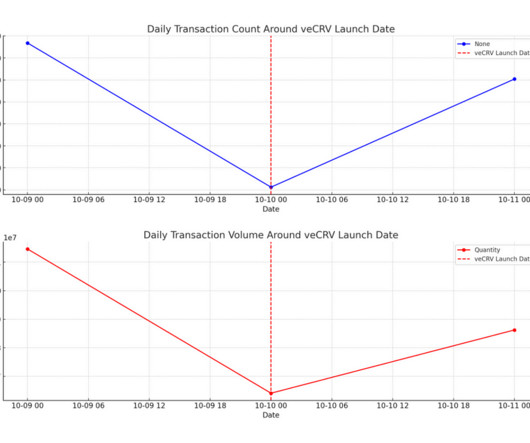
Abstract This research report encapsulates the findings from the Curve Finance Data Challenge , a competition that engaged 34 participants in a comprehensive analysis of the decentralized finance protocol. Part 1: Exploratory Data Analysis (EDA) MEV Over 25,000 MEV-related transactions have been executed through Curve.
This is a unique opportunity for data people to dive into real-world data and uncover insights that could shape the future of aviation safety, understanding, airline efficiency, and pilots driving planes. These AI/ML models become invaluable tools for aviation operations and safety by harnessing the extensive historical METAR data.
Introduction Welcome Back, Let's continue with our DataScience journey to create the Stock Price Prediction web application. The scope of this article is quite big, we will exercise the core steps of datascience, let's get started… Project Layout Here are the high-level steps for this project.
Download Dataset and Create a Virtual Environment First, you need to the download Reddit Threads dataset from Kaggle. Now you need to perform some EDA and cleaning on the data after loading it into the notebook. EDA and Data Cleaning First, you will check the frequency of the target variable: Category.
It is therefore important to carefully plan and execute data preparation tasks to ensure the best possible performance of the machine learning model. It is also essential to evaluate the quality of the dataset by conducting exploratory data analysis (EDA), which involves analyzing the dataset’s distribution, frequency, and diversity of text.
In this article, let’s dive deep into the Natural Language Toolkit (NLTK) data processing concepts for NLP data. Before building our model, we will also see how we can visualize this data with Kangas as part of exploratory data analysis (EDA). A lemma is a word that represents a whole group of words.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.





















Let's personalize your content