This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This article was published as a part of the DataScience Blogathon. Machine Learning: Machine Learning (ML) is a highly. What is Machine Learning? The post Understand Machine Learning and It’s End-to-End Process appeared first on Analytics Vidhya.
This article was published as a part of the DataScience Blogathon. The ML life cycle helps to build an efficient […]. The post Get to Know About Machine Learning Life Cycle appeared first on Analytics Vidhya.
Summary: Python for DataScience is crucial for efficiently analysing large datasets. Introduction Python for DataScience has emerged as a pivotal tool in the data-driven world. Key Takeaways Python’s simplicity makes it ideal for Data Analysis. in 2022, according to the PYPL Index.
Machine Learning (ML) is a powerful tool that can be used to solve a wide variety of problems. Getting your ML model ready for action: This stage involves building and training a machine learning model using efficient machine learning algorithms. Cleaning data: Once the data has been gathered, it needs to be cleaned.
Comet is an MLOps platform that offers a suite of tools for machine-learning experimentation and data analysis. It is designed to make it easy to track and monitor experiments and conduct exploratory data analysis (EDA) using popular Python visualization frameworks. Please consider signing up using my referral link.
The onset of the pandemic has triggered a rapid increase in the demand and adoption of ML technology. Building ML team Following the surge in ML use cases that have the potential to transform business, the leaders are making a significant investment in ML collaboration, building teams that can deliver the promise of machine learning.
Learn how to develop an ML project from development to production. Many beginners in datascience and machine learning only focus on the data analysis and model development part, which is understandable, as the other department often does the deployment process. Establish a DataScience Project2.
This is particularly important for relational databases, where data is stored in tables with defined relationships. Another interesting read: Master EDA Importance of Data Normalization So, we defined data normalization, and hopefully, youve got the idea. And thats why data normalization matters everywhere!
DataScience is a popular as well as vast field; till date, there are a lot of opportunities in this field, and most people, whether they are working professionals or students, everyone want a transition in datascience because of its scope. How much to learn? What to do next?
These tools will help make your initial data exploration process easy. ydata-profiling GitHub | Website The primary goal of ydata-profiling is to provide a one-line Exploratory Data Analysis (EDA) experience in a consistent and fast solution. This tool automatically detects problems in an ML dataset.
The importance of EDA in the machine learning world is well known to its users. Making visualizations is one of the finest ways for data scientists to explain data analysis to people outside the business. Exploratory data analysis can help you comprehend your data better, which can aid in future data preprocessing.
Embark on Your DataScience Journey through In-Depth Projects and Hands-on Learning Photo by Wes Hicks on Unsplash Datascience, as an emerging field, is constantly evolving and bringing forth innovative solutions to complex problems. I’ve handpicked a few Kaggle projects covering a range of datascience concepts.
How to create a DataScience Project on GitHub? DataScience being the most demanding career fields today with millions of job opportunities flooding in the market. in order to ensure that you have a great career in DataScience, one of the major requirements is to create and have a Github DataScience project.
While specific requirements may vary depending on the organization and the role, here are the key skills and educational background that are required for entry-level data scientists — Skillset Mathematical and Statistical Foundation Datascience heavily relies on mathematical and statistical concepts.
The machine learning (ML) model classifies new incoming customer requests as soon as they arrive and redirects them to predefined queues, which allows our dedicated client success agents to focus on the contents of the emails according to their skills and provide appropriate responses.
Some projects may necessitate a comprehensive LLMOps approach, spanning tasks from data preparation to pipeline production. Exploratory Data Analysis (EDA) Data collection: The first step in LLMOps is to collect the data that will be used to train the LLM.
Before embarking on a datascience transition, it’s crucial to be aware of these key factors. Before diving into the world of datascience, it is essential to familiarize yourself with certain key aspects. In the datascience industry, effective communication and collaboration play a crucial role.
The ’31 Questions that Shape Fortune 500 ML Strategy’ highlighted key questions to assess the maturity of an ML system. A robust ML platform offers managed solutions to easily address these aspects. An MLOps workflow consists of a series of steps from data acquisition and feature engineering to training and deployment.
From Predicting the behavior of a customer to automating many tasks, Machine learning has shown its capacity to convert raw data into actionable insights. Even though converting raw data into actionable insights, it is not determined by ML algorithms alone. The success of any ML project depends on a well-structured lifecycle.
Today, we’re going to discuss about the often overlooked but incredibly crucial aspect of Building ML models, i.e, Why learning to deploy the ML model is important? This involves visualizing the data and analyzing key statistics. Deploying machine learning models.
Check out more of the talks and workshops from industry-leading datascience and AI organizations coming to ODSC East 2023 below. a comprehensive approach to the ML pipeline. DataScience Software Acceleration at the Edge Audrey Reznik Guidera|Sr. You can see our first round of sessions here. Guillaume Moutier|Sr.
Drawing from their extensive experience in the field, the authors share their strategies, methodologies, tools and best practices for designing and building a continuous, automated and scalable ML pipeline that delivers business value. The book contains a full chapter dedicated to generative AI. Why Did the Authors Decide to Write this Book?
Although machine learning (ML) can provide valuable insights, ML experts were needed to build customer churn prediction models until the introduction of Amazon SageMaker Canvas. Additional key topics Advanced metrics are not the only important tools available to you for evaluating and improving ML model performance.
Machine Learning Operations (MLOps) can significantly accelerate how data scientists and ML engineers meet organizational needs. A well-implemented MLOps process not only expedites the transition from testing to production but also offers ownership, lineage, and historical data about ML artifacts used within the team.
Introduction In the rapidly evolving landscape of Machine Learning , Google Cloud’s Vertex AI stands out as a unified platform designed to streamline the entire Machine Learning (ML) workflow. This unified approach enables seamless collaboration among data scientists, data engineers, and ML engineers.
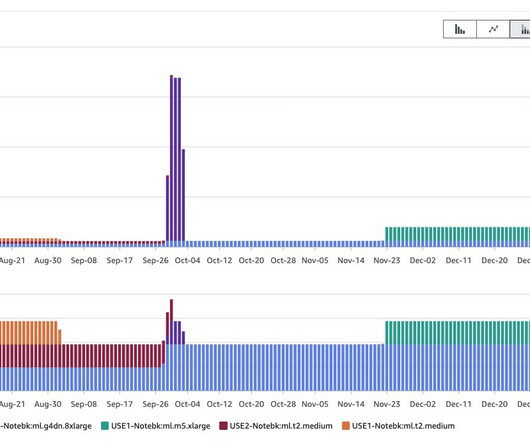
Since its introduction, we have helped hundreds of customers optimize their workloads, set guardrails, and improve the visibility of their machine learning (ML) workloads’ cost and usage. Notebooks contain everything needed to run or recreate an ML workflow. SageMaker manages creating the instance and related resources.
Exploratory Data Analysis(EDA)on Biological Data: A Hands-On Guide Unraveling the Structural Data of Proteins, Part II — Exploratory Data Analysis Photo from Pexels In a previous post, I covered the background of this protein structure resolution data set, including an explanation of key data terminology and details on how to acquire the data.
Before conducting any formal statistical analysis, it’s important to conduct exploratory data analysis (EDA) to better understand the data and identify any patterns or relationships. EDA is an approach that involves using graphical and numerical methods to summarize and visualize the data. Thank you for reading!
To address this challenge, data scientists harness the power of machine learning to predict customer churn and develop strategies for customer retention. Continuous Experiment Tracking with Comet ML Comet ML is a versatile tool that helps data scientists optimize machine learning experiments.
Challenge Overview Objective : Building upon the insights gained from Exploratory Data Analysis (EDA), participants in this datascience competition will venture into hands-on, real-world artificial intelligence (AI) & machine learning (ML). You can download the dataset directly through Desights.
Exploratory Data Analysis on Stock Market Data Photo by Lukas Blazek on Unsplash Exploratory Data Analysis (EDA) is a crucial step in datascience projects. It helps in understanding the underlying patterns and relationships in the data. Data Visualization The next step is to visualize the data.
We will carry out some EDA on our dataset, and then we will log the visualizations onto the Comet experimentation website or platform. Time Series Models Time series models are a type of statistical model that are used to analyze and make predictions about data that is collected over time. Without further ado, let’s begin.
Michal Wierzbinski ¶ Place: 2nd Place Prize: $3,000 Hometown: Rabka-Zdroj (near the city of Cracow), Poland Username: xultaeculcis Social Media: GitHub , LinkedIn Background: ML Engineer specializing in building Deep Learning solutions for Geospatial industry in a cloud native fashion. What motivated you to compete in this challenge?
This data challenge took NFL player performance data and fantasy points from the last 6 seasons to calculate forecasted points to be scored in the 2024 NFL season that began Sept. AI / ML offers tools to give a competitive edge in predictive analytics, business intelligence, and performance metrics.
This free, virtual event takes place over two days with 25+ speakers discussing the latest cutting-edge innovations in datascience and machine learning. In order to accomplish this, we will perform some EDA on the Disneyland dataset, and then we will view the visualization on the Comet experimentation website or platform.
In the unceasingly dynamic arena of datascience, discerning and applying the right instruments can significantly shape the outcomes of your machine learning initiatives. A cordial greeting to all datascience enthusiasts! You can also get datascience training on-demand wherever you are with our Ai+ Training platform.
How I cleared AWS Machine Learning Specialty with three weeks of preparation (I will burst some myths of the online exam) How I prepared for the test, my emotional journey during preparation, and my actual exam experience Certified AWS ML Specialty Badge source Introduction:- I recently gave and cleared AWS ML certification on 29th Dec 2022.
But they need a lot of labeled training data, and the dataset could be biased. In order to accomplish this, we will perform some EDA on the Disneyland dataset, and then we will view the visualization on the Comet experimentation website or platform. In this article, we’ll learn how to link Comet with Disneyland Sentiment Analysis.
Introduction Welcome Back, Let's continue with our DataScience journey to create the Stock Price Prediction web application. The scope of this article is quite big, we will exercise the core steps of datascience, let's get started… Project Layout Here are the high-level steps for this project.
But deep down, we know we could achieve better results with a different approach, after all in ML, there’s no one-size-fits-all solution. You may need to import more libraries for EDA, preprocessing, and so on depending on the dataset you’re dealing with. Different datasets and problems may require different models for optimal results.
Create DataGrids with image data using Kangas, and load and visualize image data from hugging face Photo by Genny Dimitrakopoulou on Unsplash Visualizing data to carry out a detailed EDA, especially for image data, is critical.
Exploratory Data Analysis (EDA) Univariate EDA Price: The price of a used car is the target variable and has a highly skewed distribution, with a median value of around 53.5 Bivariate EDA Contrary to intuition, Kilometers_Driven does not seem to have a relationship with the price.
tolist(),columns = ["PC1","PC2","PC3"]) Array.info() Array["stroke"] = list(df["stroke"]) px.scatter_3d(Array,x = "PC1" , y= "PC2" ,z = "PC3" ,color = "stroke") Although faint, one can clearly see a linear separation in the data at the 0 of the x-axis.
Build and deploy your own sentiment classification app using Python and Streamlit Source:Author Nowadays, working on tabular data is not the only thing in Machine Learning (ML). Data formats like image, video, text, etc., This approach is mostly referred to for small datasets where ML models can not be effective.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











































Let's personalize your content