This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
ArticleVideo Book This article was published as a part of the DataScience Blogathon. Introduction ETL pipelines look different today than they used to. The post Is manual ETL better than No-Code ETL: Are ETL tools dead? appeared first on Analytics Vidhya.
Remote work quickly transitioned from a perk to a necessity, and datascience—already digital at heart—was poised for this change. For data scientists, this shift has opened up a global market of remote datascience jobs, with top employers now prioritizing skills that allow remote professionals to thrive.
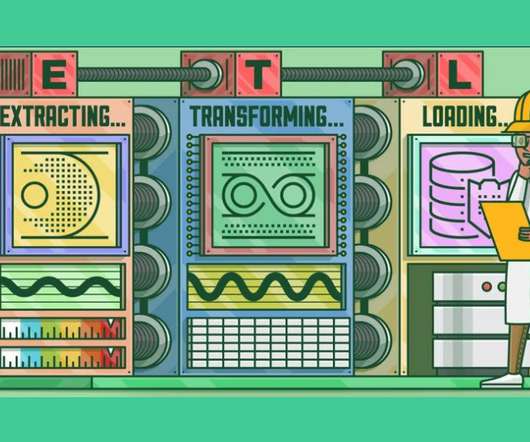
This article was published as a part of the DataScience Blogathon. Introduction to ETLETL is a type of three-step data integration: Extraction, Transformation, Load are processing, used to combine data from multiple sources. It is commonly used to build Big Data.
This article was published as a part of the DataScience Blogathon. Introduction Processing large amounts of raw data from various sources requires appropriate tools and solutions for effective data integration. Building an ETL pipeline using Apache […]. Building an ETL pipeline using Apache […].
This article was published as a part of the DataScience Blogathon. Introduction on ETL Pipeline ETL pipelines are a set of processes used to transfer data from one or more sources to a database, like a data warehouse.
This article was published as a part of the DataScience Blogathon. The post ETL and Workflow Orchestration Tools appeared first on Analytics Vidhya. We’ll continue […].
Also: How I Redesigned over 100 ETL into ELT Data Pipelines; Where NLP is heading; Don’t Waste Time Building Your DataScience Network; Data Scientists: How to Sell Your Project and Yourself.
This article was published as a part of the DataScience Blogathon. Introduction Data is ubiquitous in our modern life. Obtaining, structuring, and analyzing these data into new, relevant information is crucial in today’s world. The post ETL vs ELT in 2022: Do they matter?
This article was published as a part of the DataScience Blogathon. Introduction ETL pipelines can be built from bash scripts. You will learn about how shell scripting can implement an ETL pipeline, and how ETL scripts or tasks can be scheduled using shell scripting. What is shell scripting?
This article was published as a part of the DataScience Blogathon. Overview ETL (Extract, Transform, and Load) is a very common technique in data engineering. Traditionally, ETL processes are […]. The post Crafting Serverless ETL Pipeline Using AWS Glue and PySpark appeared first on Analytics Vidhya.
ArticleVideo Book This article was published as a part of the DataScience Blogathon Overview: Assume the job of a Data Engineer, extracting data from. The post Implementing ETL Process Using Python to Learn Data Engineering appeared first on Analytics Vidhya.
This article was published as a part of the DataScience Blogathon. Introduction At the highest level, ETL converts your data before uploading, while ELT converts data only after uploading to your repository. The post ETL & ELT – Data Engineering Essentials appeared first on Analytics Vidhya.
ArticleVideo Book This article was published as a part of the DataScience Blogathon Introduction to ETLETL as the name suggests, Extract Transform and. The post Pandas Vs PETL for ETL appeared first on Analytics Vidhya.
This article was published as a part of the DataScience Blogathon. Introduction on ETL Tools The amount of data being used or stored in today’s world is extremely huge. Many companies, organizations, and industries store the data and use it as per the requirement.
This article was published as a part of the DataScience Blogathon What is ETL? ETL is a process that extracts data from multiple source systems, changes it (through calculations, concatenations, and so on), and then puts it into the Data Warehouse system. ETL stands for Extract, Transform, and Load.
This article was published as a part of the DataScience Blogathon. Introduction Organizations with a separate transactional database and data warehouse typically have many data engineering activities. For example, they extract, transform and load data from various sources into their data warehouse.
This article was published as a part of the DataScience Blogathon A data scientist’s ability to extract value from data is closely related to how well-developed a company’s data storage and processing infrastructure is.
This article was published as a part of the DataScience Blogathon. Introduction ETL is the process that extracts the data from various data sources, transforms the collected data, and loads that data into a common data repository. Azure Data Factory […].
Navigating the realm of datascience careers is no longer a tedious task. In the current landscape, datascience has emerged as the lifeblood of organizations seeking to gain a competitive edge.
This article was published as a part of the DataScience Blogathon. Source: [link] Introduction If you are familiar with databases, or data warehouses, you have probably heard the term “ETL.” As the amount of data at organizations grow, making use of that data in analytics to derive business insights grows as well.
Introduction In the era of Data storehouse, the need for assimilating the data from contrasting sources into a single consolidated database requires you to Extract the data from its parent source, Transform and amalgamate it, and thus, Load it into the consolidated database (ETL).
Don’t Waste Time Building Your DataScience Network; 19 DataScience Project Ideas for Beginners; How I Redesigned over 100 ETL into ELT Data Pipelines; Anecdotes from 11 Role Models in Machine Learning; The Ultimate Guide To Different Word Embedding Techniques In NLP.
This article was published as a part of the DataScience Blogathon. Introduction Data acclimates to countless shapes and sizes to complete its journey from a source to a destination. Be it a streaming job or a batch job, ETL and ELT are irreplaceable.
How to Perform Motion Detection Using Python • The Complete Collection of DataScience Projects - Part 2 • What Does ETL Have to Do with Machine Learning? Data Transformation: Standardization vs Normalization • The Evolution From Artificial Intelligence to Machine Learning to DataScience.
This article was published as a part of the DataScience Blogathon. Introduction AWS Glue helps Data Engineers to prepare data for other data consumers through the Extract, Transform & Load (ETL) Process. It provides organizations with […].
The acronym ETL—Extract, Transform, Load—has long been the linchpin of modern data management, orchestrating the movement and manipulation of data across systems and databases. This methodology has been pivotal in data warehousing, setting the stage for analysis and informed decision-making.
Also: How I Redesigned over 100 ETL into ELT Data Pipelines; Where NLP is heading; Don’t Waste Time Building Your DataScience Network; Data Scientists: How to Sell Your Project and Yourself.
Don’t Waste Time Building Your DataScience Network; 19 DataScience Project Ideas for Beginners; How I Redesigned over 100 ETL into ELT Data Pipelines; Anecdotes from 11 Role Models in Machine Learning; The Ultimate Guide To Different Word Embedding Techniques In NLP.
How to Perform Motion Detection Using Python • The Complete Collection of DataScience Projects – Part 2 • Free AI for Beginners Course • Decision Tree Algorithm, Explained • What Does ETL Have to Do with Machine Learning?
This article was published as a part of the DataScience Blogathon. Introduction Azure data factory (ADF) is a cloud-based ETL (Extract, Transform, Load) tool and data integration service which allows you to create a data-driven workflow. In this article, I’ll show […].
By Santhosh Kumar Neerumalla , Niels Korschinsky & Christian Hoeboer Introduction This blogpost describes how to manage and orchestrate high volume Extract-Transform-Load (ETL) loads using a serverless process based on Code Engine. The source data is unstructured JSON, while the target is a structured, relational database.
A Brief Introduction to Papers With Code; Machine Learning Books You Need To Read In 2022; Building a Scalable ETL with SQL + Python; 7 Steps to Mastering SQL for DataScience; Top DataScience Projects to Build Your Skills.
This article was published as a part of the DataScience Blogathon. Introduction on ETL Tools The amount of data being used or stored in today’s world is extremely huge. Many companies, organizations, and industries store the data and use it as per the requirement.
This article was published as a part of the DataScience Blogathon. Introduction Data scientists, engineers, and BI analysts often need to analyze, process, or query different data sources.
Introduction Have you ever struggled with managing complex data transformations? In today’s data-driven world, extracting, transforming, and loading (ETL) data is crucial for gaining valuable insights. While many ETL tools exist, dbt (data build tool) is emerging as a game-changer.
Extract-Transform-Load vs Extract-Load-Transform: Data integration methods used to transfer data from one source to a data warehouse. Their aims are similar, but see how they differ.
Continuous Integration and Continuous Delivery (CI/CD) for Data Pipelines: It is a Game-Changer with AnalyticsCreator! The need for efficient and reliable data pipelines is paramount in datascience and data engineering. It supports a holistic data model, allowing for rapid prototyping of various models.
Rockets legacy datascience environment challenges Rockets previous datascience solution was built around Apache Spark and combined the use of a legacy version of the Hadoop environment and vendor-provided DataScience Experience development tools.
Datascience bootcamps are intensive short-term educational programs designed to equip individuals with the skills needed to enter or advance in the field of datascience. They cover a wide range of topics, ranging from Python, R, and statistics to machine learning and data visualization.
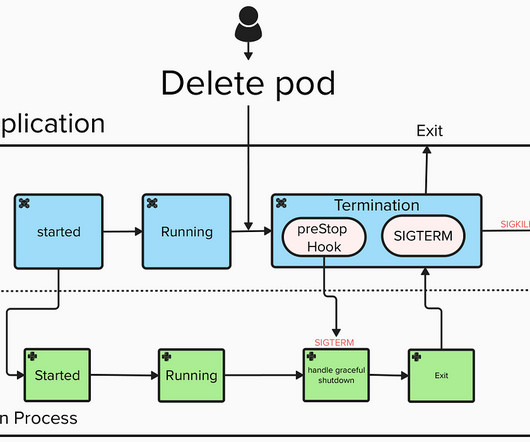
If not handled correctly, this can lead to locks, data issues, and a negative user experience. The need for handling this issue became more evident after we began implementing streaming jobs in our Apache Spark ETL platform. Consistency : The same mechanism works for any kind of ETL pipeline, either batch ingestions or streaming.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content