This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Top statistical techniques – DataScience Dojo Counterfactual causal inference: Counterfactual causal inference is a statistical technique that is used to evaluate the causal significance of historical events. This technique can be used in a wide range of fields such as economics, history, and social sciences.
Common Classification Algorithms: Logistic Regression: A popular choice for binary classification, it uses a mathematical function to model the probability of a data point belonging to a particular class. Decision Trees: These work by asking a series of yes/no questions based on data features to classify data points.
Demand forecasting, powered by datascience, helps predict customer needs. Optimize inventory, streamline operations, and make data-driven decisions for success. DataScience empowers businesses to leverage the power of data for accurate and insightful demand forecasts.
Summary : This article equips Data Analysts with a solid foundation of key DataScience terms, from A to Z. Introduction In the rapidly evolving field of DataScience, understanding key terminology is crucial for Data Analysts to communicate effectively, collaborate effectively, and drive data-driven projects.
Hey guys, in this blog we will see some of the most asked DataScience Interview Questions by interviewers in [year]. Datascience has become an integral part of many industries, and as a result, the demand for skilled data scientists is soaring. What is DataScience?
First, a robust data platform (such as a customer data platform; CDP) that can integrate data from various sources, such as tracking systems, ERP systems, e-commerce platforms to effectively perform data analytics. In contrast, multi-touch attribution leverages individual user-level data from various channels.
What makes it popular is that it is used in a wide variety of fields, including datascience, machine learning, and computational physics. Without this library, data analysis wouldn’t be the same without pandas, which reign supreme with its powerful data structures and manipulation tools. Not a bad list right?
The datascience job market is rapidly evolving, reflecting shifts in technology and business needs. Heres what we noticed from analyzing this data, highlighting whats remained the same over the years, and what additions help make the modern data scientist in2025. Joking aside, this does infer particular skills.
As organizations collect larger data sets with potential insights into business activity, detecting anomalous data, or outliers in these data sets, is essential in discovering inefficiencies, rare events, the root cause of issues, or opportunities for operational improvements.
Revolutionizing Healthcare through DataScience and Machine Learning Image by Cai Fang on Unsplash Introduction In the digital transformation era, healthcare is experiencing a paradigm shift driven by integrating datascience, machine learning, and information technology.
Schematic diagram of the overall framework of Emotion Recognition System [ Source ] The models that are used for AI emotion recognition can be based on linear models like SupportVectorMachines (SVMs) or non-linear models like Convolutional Neural Networks (CNNs). Thanks for reading!!
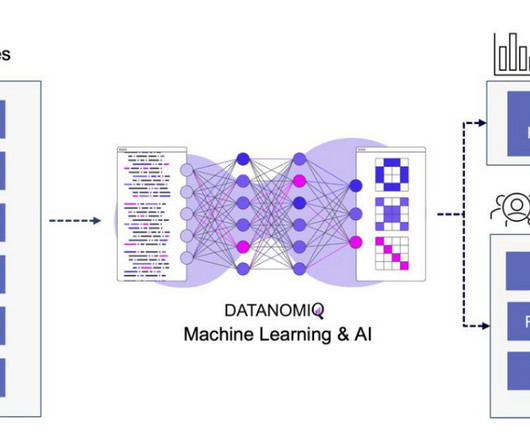
Machine Learning is a subset of Artificial Intelligence and Computer Science that makes use of data and algorithms to imitate human learning and improving accuracy. Being an important component of DataScience, the use of statistical methods are crucial in training algorithms in order to make classification.
NRE is a complex task that involves multiple steps and requires sophisticated machine learning algorithms like Hidden Markov Models (HMMs) , Conditional Random Fields (CRFs), and SupportVectorMachines (SVMs) be present. We’re committed to supporting and inspiring developers and engineers from all walks of life.
This data challenge used carbon emission rates sorted by each country to prove or debunk common climate change assumptions with datascience. Understanding trends of the past and simulating future outcomes through available data seeks to lead to better awareness, business intelligence, and policy shaping in years to come.
It is possible to improve the performance of these algorithms with machine learning algorithms such as SupportVectorMachines. We’re committed to supporting and inspiring developers and engineers from all walks of life. Another advantage is that these algorithms are not limited to working independently.
Bioinformatics: A Haven for Data Scientists and Machine Learning Engineers: Bioinformatics offers an unparalleled opportunity for data scientists and machine learning engineers to apply their expertise in solving complex biological problems.
Editor's Note: Heartbeat is a contributor-driven online publication and community dedicated to providing premier educational resources for datascience, machine learning, and deep learning practitioners. We're committed to supporting and inspiring developers and engineers from all walks of life.
Hinge Losses — Another set of losses for classification problems, but commonly used in supportvectormachines. We’re committed to supporting and inspiring developers and engineers from all walks of life. Regression Losses — When our predictions are going to be continuous.
Machine Learning and Neural Networks (1990s-2000s): Machine Learning (ML) became a focal point, enabling systems to learn from data and improve performance without explicit programming. Techniques such as decision trees, supportvectormachines, and neural networks gained popularity.
Supportvectormachine classifiers as applied to AVIRIS data.” Cross Validated] Editor’s Note: Heartbeat is a contributor-driven online publication and community dedicated to providing premier educational resources for datascience, machine learning, and deep learning practitioners. PMLR, 2017. [2]
Its popularity is due to its relatively small size, simple and well-defined task, and high quality of the data. It has been used to train and test a variety of machine learning models, including artificial neural networks, convolutional neural networks, and supportvectormachines, among others.
These features can then be used as input to another machine learning model, such as a supportvectormachine (SVM) or a random forest classifier, to perform tasks such as image classification or object detection. We’re committed to supporting and inspiring developers and engineers from all walks of life.
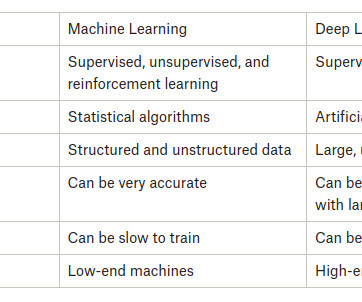
Model Complexity Machine Learning : Traditional machine learning models have fewer parameters and a simpler structure than deep learning models. They typically rely on simpler algorithms like decision trees, supportvectormachines, or linear regression.
Data Streaming Learning about real-time data collection methods using tools like Apache Kafka and Amazon Kinesis. Students should understand the concepts of event-driven architecture and stream processing. Once data is collected, it needs to be stored efficiently.
The e1071 package provides a suite of statistical classification functions, including supportvectormachines (SVMs), which are commonly used for spam detection. Naive Bayes, according to Nagesh Singh Chauhan in KDnuggets, is a straightforward machine learning technique that uses Bayes’ theorem to create predictions.
Hinge Loss (SVM Loss): Used for supportvectormachine (SVM) and binary classification problems. İrem KÖMÜRCÜ Editor's Note: Heartbeat is a contributor-driven online publication and community dedicated to providing premier educational resources for datascience, machine learning, and deep learning practitioners.
Predictive Models Predictive models are designed to forecast future outcomes based on historical data. They identify patterns in existing data and use them to predict unknown events. In more complex cases, you may need to explore non-linear models like decision trees, supportvectormachines, or time series models.
Classifier Integration: The HOG features are fed into a classifier, often a SupportVectorMachine (SVM), which learns to distinguish between pedestrian and non-pedestrian patterns. We’re committed to supporting and inspiring developers and engineers from all walks of life. HOGDescriptor() hog.setSVMDetector(cv2.HOGDescriptor_getDefaultPeopleDetector())
Anomaly detection ( Figure 2 ) is a critical technique in data analysis used to identify data points, events, or observations that deviate significantly from the norm. Supervised Learning These methods require labeled data to train the model. The model learns to distinguish between normal and abnormal data points.
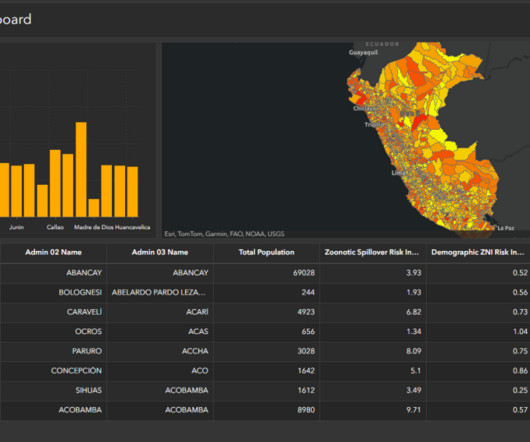
According to health organizations such as the Centers for Disease Control and Prevention ( CDC ) and the World Health Organization ( WHO ), a spillover event at a wet market in Wuhan, China most likely caused the coronavirus disease 2019 (COVID-19). One of the models used is a supportvectormachine (SVM). min()) * 100).round(2)
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



































Let's personalize your content