This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This article was published as a part of the DataScience Blogathon What is HypothesisTesting? Any datascience project starts with exploring the data. When we perform an analysis on a sample through exploratorydataanalysis and inferential statistics we get information about the sample.
In this blog, we will discuss exploratorydataanalysis, also known as EDA, and why it is important. We will also be sharing code snippets so you can try out different analysis techniques yourself. EDA is an iterative process of conglomerative activities which include data cleaning, manipulation and visualization.
Summary: Python for DataScience is crucial for efficiently analysing large datasets. Introduction Python for DataScience has emerged as a pivotal tool in the data-driven world. Key Takeaways Python’s simplicity makes it ideal for DataAnalysis. in 2022, according to the PYPL Index.
Photo by Joshua Sortino on Unsplash Dataanalysis is an essential part of any research or business project. Before conducting any formal statistical analysis, it’s important to conduct exploratorydataanalysis (EDA) to better understand the data and identify any patterns or relationships.
Machine learning engineer vs data scientist: two distinct roles with overlapping expertise, each essential in unlocking the power of data-driven insights. As businesses strive to stay competitive and make data-driven decisions, the roles of machine learning engineers and data scientists have gained prominence.
Summary: The DataScience and DataAnalysis life cycles are systematic processes crucial for uncovering insights from raw data. Quality data is foundational for accurate analysis, ensuring businesses stay competitive in the digital landscape. billion INR by 2026, with a CAGR of 27.7%.
DataScience is a popular as well as vast field; till date, there are a lot of opportunities in this field, and most people, whether they are working professionals or students, everyone want a transition in datascience because of its scope. How much to learn? What to do next?
DataScience interviews are pivotal moments in the career trajectory of any aspiring data scientist. Having the knowledge about the datascience interview questions will help you crack the interview. DataScience skills that will help you excel professionally.
What is R in DataScience? As a programming language it provides objects, operators and functions allowing you to explore, model and visualise data. How is R Used in DataScience? R is a popular programming language and environment widely used in the field of datascience.
Summary : Combining Python and R enriches DataScience workflows by leveraging Python’s Machine Learning and data handling capabilities alongside R’s statistical analysis and visualisation strengths. Python’s key libraries make data manipulation and Machine Learning workflows seamless. million by 2030.
Together, data engineers, data scientists, and machine learning engineers form a cohesive team that drives innovation and success in data analytics and artificial intelligence. Their collective efforts are indispensable for organizations seeking to harness data’s full potential and achieve business growth.
Summary : This article equips Data Analysts with a solid foundation of key DataScience terms, from A to Z. Introduction In the rapidly evolving field of DataScience, understanding key terminology is crucial for Data Analysts to communicate effectively, collaborate effectively, and drive data-driven projects.
Learning Objectives Recap: Paradigms in DataScience: We explored the two main paradigms in datascience: descriptive analytics (understanding what happened in the past) and predictive analytics (using models to forecast future outcomes). This allows us to make generalizations about populations based on samples.
Summary: Dive into programs at Duke University, MIT, and more, covering DataAnalysis, Statistical quality control, and integrating Statistics with DataScience for diverse career paths. It emphasises probabilistic modeling and Statistical inference for analysing big data and extracting information.
F1 :: 2024 Strategy Analysis Poster ‘The Formula 1 Racing Challenge’ challenges participants to analyze race strategies during the 2024 season. They will work with lap-by-lap data to assess how pit stop timing, tire selection, and stint management influence race performance.
Statsmodels Allows users to explore data, estimate statistical models, and perform statistical tests. It is particularly useful for regression analysis and hypothesistesting. Pingouin A library designed for statistical analysis, providing a comprehensive collection of statistical tests.
Statistics is an important part of DataScience where using Statistical Analysis, organisations can derive the value of the data input and evaluate meaningful conclusions. Prescriptive Analysis : Significantly, the use of Prescriptive Analysis helps in prescribing the best possible outcome for assessing datasets.
Data Collection: Based on the question or problem identified, you need to collect data that represents the problem that you are studying. ExploratoryDataAnalysis: You need to examine the data for understanding the distribution, patterns, outliers and relationships between variables.
ExploratoryDataAnalysis (EDA) ExploratoryDataAnalysis (EDA) is an approach to analyse datasets to uncover patterns, anomalies, or relationships. The primary purpose of EDA is to explore the data without any preconceived notions or hypotheses.
I conducted thorough data validation, collaborated with stakeholders to identify the root cause, and implemented corrective measures to ensure data integrity. I would perform exploratorydataanalysis to understand the distribution of customer transactions and identify potential segments.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


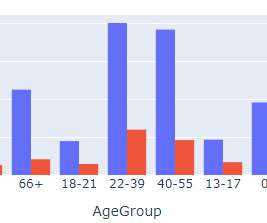























Let's personalize your content