This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The post Predicting SONAR Rocks Against Mines with ML appeared first on Analytics Vidhya. It uses sound waves to detect objects underwater. Machine learning-based tactics, and deep learning-based approaches have applications in […].
From Solo Notebooks to Collaborative Powerhouse: VS Code Extensions for DataScience and ML Teams Photo by Parabol | The Agile Meeting Toolbox on Unsplash In this article, we will explore the essential VS Code extensions that enhance productivity and collaboration for data scientists and machine learning (ML) engineers.
Summary: Python for DataScience is crucial for efficiently analysing large datasets. Introduction Python for DataScience has emerged as a pivotal tool in the data-driven world. Key Takeaways Python’s simplicity makes it ideal for DataAnalysis. in 2022, according to the PYPL Index.
Machine learning engineer vs data scientist: two distinct roles with overlapping expertise, each essential in unlocking the power of data-driven insights. As businesses strive to stay competitive and make data-driven decisions, the roles of machine learning engineers and data scientists have gained prominence.
Introduction DataScience is one of the most promising careers of 2022 and beyond. Do you know that, for the past 5 years, ‘Data Scientist’ consistently ranked among the top 3 job professions in the US market? Keeping this in mind, many working professionals and students have started upskilling themselves.
Google Releases a tool for Automated ExploratoryDataAnalysis Exploring data is one of the first activities a data scientist performs after getting access to the data. This command-line tool helps to determine the properties and quality of the data as well the predictive power.
As part of the 2023 DataScience Conference (DSCO 23), AWS partnered with the Data Institute at the University of San Francisco (USF) to conduct a datathon. Participants, both high school and undergraduate students, competed on a datascience project that focused on air quality and sustainability.
Machine Learning (ML) is a powerful tool that can be used to solve a wide variety of problems. Getting your ML model ready for action: This stage involves building and training a machine learning model using efficient machine learning algorithms. Cleaning data: Once the data has been gathered, it needs to be cleaned.
Making visualizations is one of the finest ways for data scientists to explain dataanalysis to people outside the business. Exploratorydataanalysis can help you comprehend your data better, which can aid in future data preprocessing. ExploratoryDataAnalysis What is EDA?
There are also plenty of data visualization libraries available that can handle exploration like Plotly, matplotlib, D3, Apache ECharts, Bokeh, etc. In this article, we’re going to cover 11 data exploration tools that are specifically designed for exploration and analysis. Output is a fully self-contained HTML application.
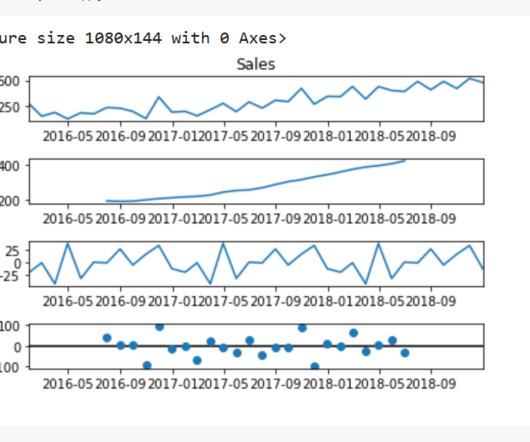
ExploratoryDataAnalysis on Stock Market Data Photo by Lukas Blazek on Unsplash ExploratoryDataAnalysis (EDA) is a crucial step in datascience projects. It helps in understanding the underlying patterns and relationships in the data. pct_change().dropna(),
Summary: In the tech landscape of 2024, the distinctions between DataScience and Machine Learning are pivotal. DataScience extracts insights, while Machine Learning focuses on self-learning algorithms. The collective strength of both forms the groundwork for AI and DataScience, propelling innovation.
Photo by Joshua Sortino on Unsplash Dataanalysis is an essential part of any research or business project. Before conducting any formal statistical analysis, it’s important to conduct exploratorydataanalysis (EDA) to better understand the data and identify any patterns or relationships.
Comet is an MLOps platform that offers a suite of tools for machine-learning experimentation and dataanalysis. It is designed to make it easy to track and monitor experiments and conduct exploratorydataanalysis (EDA) using popular Python visualization frameworks.
On November 30, 2021, we announced the general availability of Amazon SageMaker Canvas , a visual point-and-click interface that enables business analysts to generate highly accurate machine learning (ML) predictions without having to write a single line of code. The key to scaling the use of ML is making it more accessible.
DataScience is a popular as well as vast field; till date, there are a lot of opportunities in this field, and most people, whether they are working professionals or students, everyone want a transition in datascience because of its scope. How much to learn? What to do next?
Leverage the Watson NLP library to build the best classification models by combining the power of classic ML, Deep Learning, and Transformed based models. In this blog, you will walk through the steps of building several ML and Deep learning-based models using the Watson NLP library. So, let’s get started with this. Dataframe head 2.
Because answering these questions requires understanding complex relationships between many different factors—often changing and dynamic—one powerful tool we have at our disposal is machine learning (ML), which can be deployed to analyze, predict, and solve these complex quantitative problems. So how do we remove these bottlenecks?
While specific requirements may vary depending on the organization and the role, here are the key skills and educational background that are required for entry-level data scientists — Skillset Mathematical and Statistical Foundation Datascience heavily relies on mathematical and statistical concepts.
The machine learning (ML) model classifies new incoming customer requests as soon as they arrive and redirects them to predefined queues, which allows our dedicated client success agents to focus on the contents of the emails according to their skills and provide appropriate responses.
Some projects may necessitate a comprehensive LLMOps approach, spanning tasks from data preparation to pipeline production. ExploratoryDataAnalysis (EDA) Data collection: The first step in LLMOps is to collect the data that will be used to train the LLM.
So, if you are eyeing your career in the data domain, this blog will take you through some of the best colleges for DataScience in India. There is a growing demand for employees with digital skills The world is drifting towards data-based decision making In India, a technology analyst can make between ₹ 5.5
Integrating different systems, data sources, and technologies within an ecosystem can be difficult and time-consuming, leading to inefficiencies, data silos, broken machine learning models, and locked ROI. ExploratoryDataAnalysis After we connect to Snowflake, we can start our ML experiment.
From Predicting the behavior of a customer to automating many tasks, Machine learning has shown its capacity to convert raw data into actionable insights. Even though converting raw data into actionable insights, it is not determined by ML algorithms alone. The success of any ML project depends on a well-structured lifecycle.
Machine learning (ML) technologies can drive decision-making in virtually all industries, from healthcare to human resources to finance and in myriad use cases, like computer vision , large language models (LLMs), speech recognition, self-driving cars and more. However, the growing influence of ML isn’t without complications.
Today, we’re going to discuss about the often overlooked but incredibly crucial aspect of Building ML models, i.e, Why learning to deploy the ML model is important? This involves visualizing the data and analyzing key statistics. Deploying machine learning models.
Before embarking on a datascience transition, it’s crucial to be aware of these key factors. Before diving into the world of datascience, it is essential to familiarize yourself with certain key aspects. In the datascience industry, effective communication and collaboration play a crucial role.
DataScience Project — Predictive Modeling on Biological Data Part III — A step-by-step guide on how to design a ML modeling pipeline with scikit-learn Functions. Photo by Unsplash Earlier we saw how to collect the data and how to perform exploratorydataanalysis.
In this post, we show how to configure a new OAuth-based authentication feature for using Snowflake in Amazon SageMaker Data Wrangler. Snowflake is a cloud data platform that provides data solutions for data warehousing to datascience. Shut down the Studio app and relaunch for the changes to take effect.
Advanced users will appreciate tunable parameters and full access to configuring how DataRobot processes data and builds models with composable ML. Explanations around data, models , and blueprints are extensive throughout the platform so you’ll always understand your results. and train models with a single click of a button.
Check out more of the talks and workshops from industry-leading datascience and AI organizations coming to ODSC East 2023 below. a comprehensive approach to the ML pipeline. DataScience Software Acceleration at the Edge Audrey Reznik Guidera|Sr. You can see our first round of sessions here. Guillaume Moutier|Sr.
Drawing from their extensive experience in the field, the authors share their strategies, methodologies, tools and best practices for designing and building a continuous, automated and scalable ML pipeline that delivers business value. The book contains a full chapter dedicated to generative AI. Why Did the Authors Decide to Write this Book?
Introduction In the rapidly evolving landscape of Machine Learning , Google Cloud’s Vertex AI stands out as a unified platform designed to streamline the entire Machine Learning (ML) workflow. This unified approach enables seamless collaboration among data scientists, data engineers, and ML engineers.
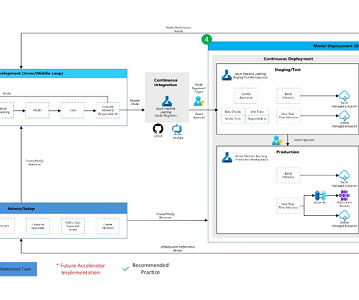
Machine Learning Operations (MLOps) can significantly accelerate how data scientists and ML engineers meet organizational needs. A well-implemented MLOps process not only expedites the transition from testing to production but also offers ownership, lineage, and historical data about ML artifacts used within the team.
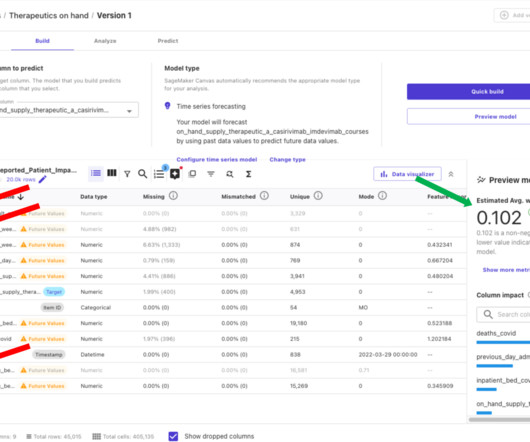
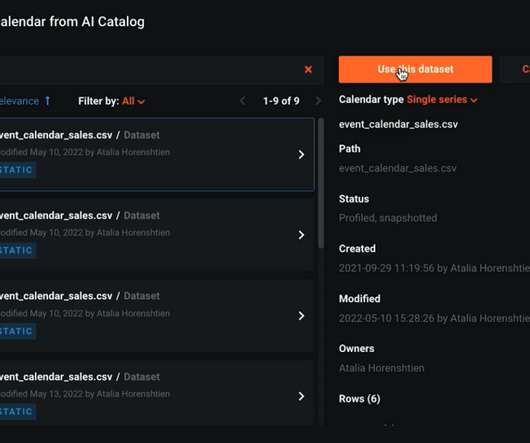
By simplifying Time Series Forecasting models and accelerating the AI lifecycle, DataRobot can centralize collaboration across the business—especially datascience and IT teams—and maximize ROI. Prepare your data for Time Series Forecasting. Perform exploratorydataanalysis. Configuring an ML project.
Although machine learning (ML) can provide valuable insights, ML experts were needed to build customer churn prediction models until the introduction of Amazon SageMaker Canvas. Additional key topics Advanced metrics are not the only important tools available to you for evaluating and improving ML model performance.
Challenge Overview Objective : Building upon the insights gained from ExploratoryDataAnalysis (EDA), participants in this datascience competition will venture into hands-on, real-world artificial intelligence (AI) & machine learning (ML). You can download the dataset directly through Desights.
Once databases are added to your Snowflake account, they can be explored in Hex with the Data sources tab. ExploratoryDataAnalysis with Hex and Snowpark Using the Snowpark dataframe API, we can quickly explore the data. It’s possible to train ML models using the Snowpark UDF API, but it’s a more niche use case.
ExploratoryDataAnalysis(EDA)on Biological Data: A Hands-On Guide Unraveling the Structural Data of Proteins, Part II — ExploratoryDataAnalysis Photo from Pexels In a previous post, I covered the background of this protein structure resolution data set, including an explanation of key data terminology and details on how to acquire the data.
Machine Learning (ML) is a subset of AI that involves using statistical techniques to enable machines to improve their performance on tasks through experience. On the other hand, ML focuses specifically on developing algorithms that allow machines to learn and make predictions or decisions based on data.
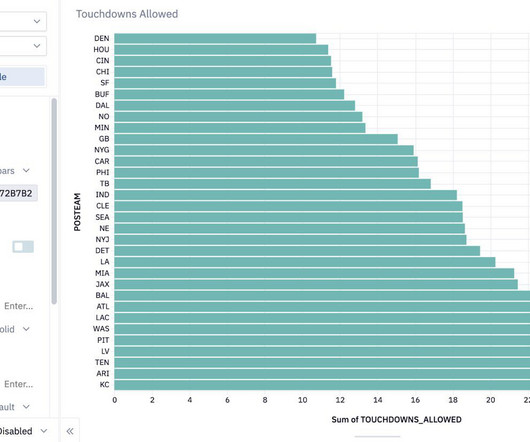
This data challenge took NFL player performance data and fantasy points from the last 6 seasons to calculate forecasted points to be scored in the 2024 NFL season that began Sept. AI / ML offers tools to give a competitive edge in predictive analytics, business intelligence, and performance metrics.
Michal Wierzbinski ¶ Place: 2nd Place Prize: $3,000 Hometown: Rabka-Zdroj (near the city of Cracow), Poland Username: xultaeculcis Social Media: GitHub , LinkedIn Background: ML Engineer specializing in building Deep Learning solutions for Geospatial industry in a cloud native fashion. What motivated you to compete in this challenge?
Comet has another noteworthy feature: it allows us to conduct exploratorydataanalysis. To acquire a deeper knowledge of the dataset and undertake exploratorydataanalysis, the train.head() function is frequently used in conjunction with other methods such as train.info() and train.describe().
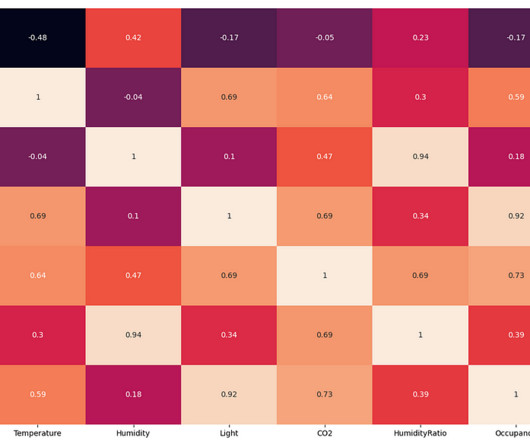
The exploratorydataanalysis found that the change in room temperature, CO levels, and light intensity can be used to predict the occupancy of the room in place of humidity and humidity ratio. We will also be looking at the correlation between the variables.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











































Let's personalize your content