This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
ArticleVideos This article was published as a part of the DataScience Blogathon. Introduction This article concerns one of the supervised ML classification algorithm-KNN(K. The post A Quick Introduction to K – NearestNeighbor (KNN) Classification Using Python appeared first on Analytics Vidhya.
This article was published as a part of the DataScience Blogathon. Introduction Knearestneighbors are one of the most popular and best-performing algorithms in supervised machine learning. Therefore, the data […].
ArticleVideo Book This article was published as a part of the DataScience Blogathon. Overview: KNearestNeighbor (KNN) is intuitive to understand and. The post Simple understanding and implementation of KNN algorithm! appeared first on Analytics Vidhya.
This article was published as a part of the DataScience Blogathon. Introduction KNN stands for K-NearestNeighbors, the supervised machine learning algorithm that can operate with both classification and regression tasks.
This article was published as a part of the DataScience Blogathon. Introduction Knearestneighbor or KNN is one of the most famous algorithms in classical AI. KNN is a great algorithm to find the nearestneighbors and thus can be used as a classifier or similarity finding algorithm.
This article was published as a part of the DataScience Blogathon. In this article, we will try to classify Food Reviews using multiple Embedded techniques with the help of one of the simplest classifying machine learning models called the K-NearestNeighbor. Objective Loading DataData […].
Image Credit: Pinterest – Problem solving tools In last week’s post , DS-Dojo introduced our readers to this blog-series’ three focus areas, namely: 1) software development, 2) project-management, and 3) datascience. This week, we continue that metaphorical (learning) journey with a fun fact. Better yet, a riddle. IoT, Web 3.0,
In the world of datascience and machine learning, feature transformation plays a crucial role in achieving accurate and reliable results. In this blog, we will discuss one of the feature transformation techniques called feature scaling with examples and see how it will be the game changer for our machine learning model accuracy.
Some common models used are as follows: Logistic Regression – it classifies by predicting the probability of a data point belonging to a class instead of a continuous value Decision Trees – uses a tree structure to make predictions by following a series of branching decisions Support Vector Machines (SVMs) – create a clear decision (..)
By New Africa In this article, I will show how to implement a K-NearestNeighbor classification with Tensorflow.js. KNN KNN (K-NearestNeighbors) classification is a supervised machine learning algorithm used for classification tasks. TensorFlow.js TensorFlow.js
We shall look at various types of machine learning algorithms such as decision trees, random forest, Knearestneighbor, and naïve Bayes and how you can call their libraries in R studios, including executing the code. In-depth Documentation- R facilitates repeatability by analyzing data using a script-based methodology.
Data mining refers to the systematic process of analyzing large datasets to uncover hidden patterns and relationships that inform and address business challenges. It’s an integral part of data analytics and plays a crucial role in datascience.
Nearestneighbor search algorithms : Efficiently retrieving the closest patient vec t o r s to a given query. Techniques like k-NearestNeighbors ( kNN ) and Annoy trees excel in this area, enabling rapid identification of sim i l a r patients.
Support Vector Machines (SVM): This algorithm finds a hyperplane that best separates data points of different classes in high-dimensional space. Decision Trees: These work by asking a series of yes/no questions based on data features to classify data points.
Photo Mosaics with NearestNeighbors: Machine Learning for Digital Art In this post, we focus on a color-matching strategy that is of particular interest to a datascience or machine learning audience because it utilizes a K-nearestneighbors (KNN) modeling approach. Learn more here!
Created by the author with DALL E-3 Statistics, regression model, algorithm validation, Random Forest, KNearestNeighbors and Naïve Bayes— what in God’s name do all these complicated concepts have to do with you as a simple GIS analyst? Author(s): Stephen Chege-Tierra Insights Originally published on Towards AI.
Nevertheless, its applications across classification, regression, and anomaly detection tasks highlight its importance in modern data analytics methodologies. The KNearestNeighbors (KNN) algorithm of machine learning stands out for its simplicity and effectiveness. What are KNearestNeighbors in Machine Learning?
Convolutional neural networks offer high accuracy in video analysis but require considerable amounts of data. K-nearestneighbors are sufficient for detecting specific medialike in copyright protectionbut less reliable when analyzing a broad range of factors.
R has simplified the most complex task of geospatial machine learning and datascience. As GIS is slowly embracing datascience, mastery of programming is very necessary regardless of your perception of programming. In-depth Documentation- R facilitates repeatability by analyzing data using a script-based methodology.
The KNN (KNearestNeighbors) algorithm analyzes all available data points and classifies this data, then classifies new cases based on these established categories. Click to learn more about author Kartik Patel. In this article, we will discuss the KNN Classification method of analysis.
Summary : This article equips Data Analysts with a solid foundation of key DataScience terms, from A to Z. Introduction In the rapidly evolving field of DataScience, understanding key terminology is crucial for Data Analysts to communicate effectively, collaborate effectively, and drive data-driven projects.
Whether you are just cleaning your data for analysis, monitoring the health of your computer systems, looking out for cybersecurity threats, or sifting through claims and transactions looking for fraud, anomalies drastically impact any analysis to be done. LaBarr holds a B.S. in economics, as well as a B.S.,
Hey guys, in this blog we will see some of the most asked DataScience Interview Questions by interviewers in [year]. Datascience has become an integral part of many industries, and as a result, the demand for skilled data scientists is soaring. What is DataScience?
The prediction is then done using a k-nearestneighbor method within the embedding space. Distance preserving embeddings: The name of this method is straightforward. The embedding space is generated by preserving the distances between the labels.
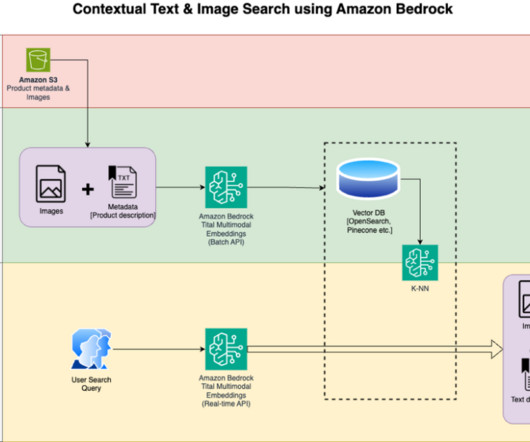
We detail the steps to use an Amazon Titan Multimodal Embeddings model to encode images and text into embeddings, ingest embeddings into an OpenSearch Service index, and query the index using the OpenSearch Service k-nearestneighbors (k-NN) functionality. Open the titan_mm_embed_search_blog.ipynb notebook.
ML is a computer science, datascience and artificial intelligence (AI) subset that enables systems to learn and improve from data without additional programming interventions. Classification algorithms include logistic regression, k-nearestneighbors and support vector machines (SVMs), among others.
What makes it popular is that it is used in a wide variety of fields, including datascience, machine learning, and computational physics. Without this library, data analysis wouldn’t be the same without pandas, which reign supreme with its powerful data structures and manipulation tools. Not a bad list right?
Word2Vec, BERT, ResNet) and capture the semantic meaning or features of the data. But heres the catch scanning millions of vectors one by one (a brute-force k-NearestNeighbors or KNN search) is painfully slow. These vectors are typically generated by machine learning models (e.g.,
Figure 7: TF-IDF calculation (source: Towards DataScience ). K-NearestNeighborK-nearestneighbor (KNN) ( Figure 8 ) is an algorithm that can be used to find the closest points for a data point based on a distance measure (e.g.,
Instead of treating each input as entirely unique, we can use a distance-based approach like k-nearestneighbors (k-NN) to assign a class based on the most similar examples surrounding the input. To make this work, we need to transform the textual interactions into a format that allows algebraic operations.
Anomalies are not inherently bad, but being aware of them, and having data to put them in context, is integral to understanding and protecting your business. The challenge for IT departments working in datascience is making sense of expanding and ever-changing data points.
We perform a k-nearestneighbor (k-NN) search to retrieve the most relevant embeddings matching the user query. He is also an adjunct lecturer in the MS datascience and analytics program at Georgetown University in Washington D.C. An OpenSearch Service vector search is performed using these embeddings.
“GraphStorm enables our team to train GNN embedding in a self-supervised manner on a graph with 288 million nodes and 2 billion edges,” Says Haining Yu, Principal Applied Scientist at Amazon Measurement, Ad Tech, and DataScience. python3 -m graphstorm.run.gs_link_prediction --inference --num_trainers 8 --part-config /data/oagv2.1/mag_bert_constructed/mag.json
We perform a k-nearestneighbor (k=1) search to retrieve the most relevant embedding matching the user query. Setting k=1 retrieves the most relevant slide to the user question. He is also an adjunct lecturer in the MS datascience and analytics program at Georgetown University in Washington D.C.
In contrast, for datasets with low dimensionality, simpler algorithms such as Naive Bayes or K-NearestNeighbors may be sufficient. ▶ Distribution of the Data : The distribution of the data can also affect the choice of algorithm.
In this post, we present a solution to handle OOC situations through knowledge graph-based embedding search using the k-nearestneighbor (kNN) search capabilities of OpenSearch Service. Solution overview. The key AWS services used to implement this solution are OpenSearch Service, SageMaker, Lambda, and Amazon S3.
This includes preparing data, creating a SageMaker model, and performing batch transform using the model. Data overview and preparation You can use a SageMaker Studio notebook with a Python 3 (DataScience) kernel to run the sample code. For this post, we use the Amazon Berkeley Objects Dataset.
K-NearestNeighbors (KNN) Classifier: The KNN algorithm relies on selecting the right number of neighbors and a power parameter p. The n_neighbors parameter determines how many data points are considered for making predictions. random_state=0) 3.3.
Some common quantitative evaluations are linear probing , Knearestneighbors (KNN), and fine-tuning. Evaluation Matrix In SSL, the performance evaluation is usually conducted while doing transfer learning in the downstream task. Besides that, there is also qualitative evaluation.
Open the notebook synthetic-data-generation.ipynb. Choose the default Python 3 kernel and DataScience 3.0 find_similar_items performs semantic search using the k-nearestneighbors (kNN) algorithm on the input image prompt. image, then follow the instructions in the notebook.
We design a K-NearestNeighbors (KNN) classifier to automatically identify these plays and send them for expert review. Thompson Bliss is a Manager, Football Operations, Data Scientist at the National Football League. Some plays are mixed into other coverage types, as shown in the following figure (right).
Figure 6: Recurrent neural networks (source: Venkatachalam, 2019, Towards DataScience ). text mining, K-nearestneighbor, clustering, matrix factorization, and neural networks). Similarly, at each time step, the RNN produces an output as a non-linear function of input and previous hidden state. Gosthipaty, S.
index.add(xb) # xq are query vectors, for which we need to search in xb to find the knearestneighbors. # The search returns D, the pairwise distances, and I, the indices of the nearestneighbors. D, I = index.search(xq, k) #Source: [link] Check this out to learn more. . # Creating the index. While neptune.ai
Similarly, autoencoders can be trained to reconstruct input data, and data points with high reconstruction errors can be flagged as anomalies. Proximity-Based Methods Proximity-based methods can detect anomalies based on the distance between data points. This technique is widely used in various fields (e.g.,
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content