This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
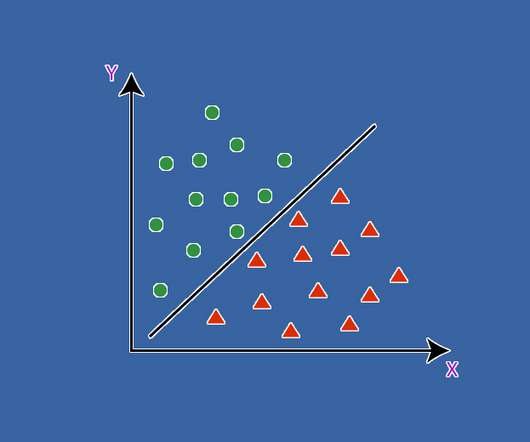
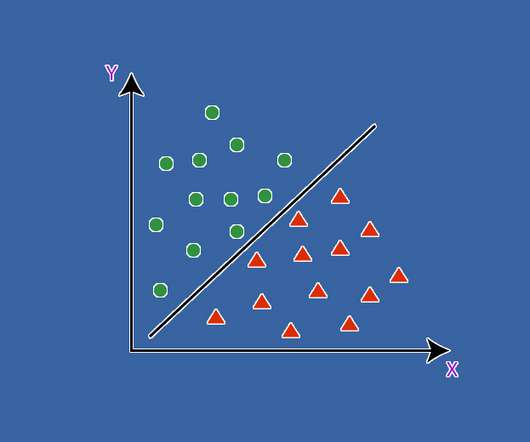
ArticleVideo Book This article was published as a part of the DataScience Blogathon Introduction In this article, we will be discussing SupportVectorMachines. The post SupportVectorMachine: Introduction appeared first on Analytics Vidhya.
This article was published as a part of the DataScience Blogathon Introduction to SupportVectorMachine(SVM) SVM is a powerful supervised algorithm that works best on smaller datasets but on complex ones. The post SupportVectorMachine(SVM): A Complete guide for beginners appeared first on Analytics Vidhya.
This article was published as a part of the DataScience Blogathon. The post Understanding Naïve Bayes and SupportVectorMachine and their implementation in Python appeared first on Analytics Vidhya. Introduction In this digital world, spam is the most troublesome challenge that.
This article was published as a part of the DataScience Blogathon. Later, we will discuss the Maximal-Margin Classifier and Soft Margin Classifier for SupportVectorMachine. The post SupportVectorMachine with Kernels and Python Iterators appeared first on Analytics Vidhya.
ArticleVideo Book This article was published as a part of the DataScience Blogathon Introduction SupportVectorMachine (SVM) is one of the Machine Learning. The post The A-Z guide to SupportVectorMachine appeared first on Analytics Vidhya.
This article was published as a part of the DataScience Blogathon. Introduction Classification problems are often solved using supervised learning algorithms such as Random Forest Classifier, SupportVectorMachine, Logistic Regressor (for binary class classification) etc. One-Class […].
This article was published as a part of the DataScience Blogathon Introduction Hello Everyone, I hope you are doing well. Ever wondered, how great would it be, if we could predict, whether our request for a loan, will be approved or not, simply by the use of machine learning, from the ease and comfort […].
This article was published as a part of the DataScience Blogathon. The post The Mathematics Behind SupportVectorMachine Algorithm (SVM) appeared first on Analytics Vidhya. Introduction One of the classifiers that we come across while learning about.
ArticleVideo Book This article was published as a part of the DataScience Blogathon Introduction A SupportVectorMachine (SVM) is a very powerful and. The post SupportVectorMachine and Principal Component Analysis Tutorial for Beginners appeared first on Analytics Vidhya.
ArticleVideo Book This article was published as a part of the DataScience Blogathon Source Overview In this article, we will learn the working of. The post Start Learning SVM (SupportVectorMachine) Algorithm Here! appeared first on Analytics Vidhya.
ArticleVideo Book This article was published as a part of the DataScience Blogathon. The post Introduction to SVM(SupportVectorMachine) Along with Python Code appeared first on Analytics Vidhya. Introduction This article aims to provide a basic understanding.
This article was published as a part of the DataScience Blogathon. Introduction Supportvectormachine is one of the most famous and decorated machine learning algorithms in classification problems.
ArticleVideo Book This article was published as a part of the DataScience Blogathon Introduction Before the sudden rise of neural networks, SupportVectorMachines. The post Top 15 Questions to Test your DataScience Skills on SVM appeared first on Analytics Vidhya.
Datascience techniques are the backbone of modern analytics, enabling professionals to transform raw data into meaningful insights. By employing various methodologies, analysts uncover hidden patterns, predict outcomes, and supportdata-driven decision-making. What are datascience techniques?
In contemporary times, datascience has emerged as a substantial and progressively expanding domain that has an impact on virtually every sphere of human ingenuity: be it commerce, technology, healthcare, education, governance, and beyond. This piece will concentrate on the elemental constituents constituting datascience.
Python is a powerful and versatile programming language that has become increasingly popular in the field of datascience. One of the main reasons for its popularity is the vast array of libraries and packages available for data manipulation, analysis, and visualization.
Top statistical techniques – DataScience Dojo Counterfactual causal inference: Counterfactual causal inference is a statistical technique that is used to evaluate the causal significance of historical events. These algorithms are often used to solve optimization problems, such as gradient descent and conjugate gradient.
Image Credit: Pinterest – Problem solving tools In last week’s post , DS-Dojo introduced our readers to this blog-series’ three focus areas, namely: 1) software development, 2) project-management, and 3) datascience. This week, we continue that metaphorical (learning) journey with a fun fact. Better yet, a riddle. IoT, Web 3.0,
They work by dividing the data into smaller and smaller groups until each group can be classified with a high degree of accuracy. It works by finding a line that best fits the data. Supportvectormachines : Supportvectormachines are a more complex algorithm that can be used for both classification and regression tasks.
Python is a powerful and versatile programming language that has become increasingly popular in the field of datascience. One of the main reasons for its popularity is the vast array of libraries and packages available for data manipulation, analysis, and visualization.
Surrogate models have become essential tools in engineering and datascience, transforming how we approach complex simulations. Their usefulness ranges from optimizing designs to performing sensitivity analyses, making them invaluable in today’s data-driven world. What is a surrogate model?
In this blog, we will discuss one of the feature transformation techniques called feature scaling with examples and see how it will be the game changer for our machine learning model accuracy. In the world of datascience and machine learning, feature transformation plays a crucial role in achieving accurate and reliable results.
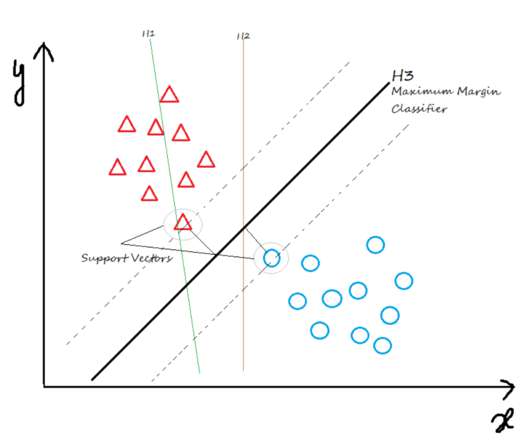
SupportVectorMachine: A Comprehensive Guide — Part1 SupportVectorMachines (SVMs) are a type of supervised learning algorithm used for classification and regression analysis. Submission Suggestions SupportVectorMachine: A Comprehensive Guide — Part1 was originally published in MLearning.ai
SupportVectorMachine: A Comprehensive Guide — Part2 In my last article, we discussed SVMs, the geometric intuition behind SVMs, and also Soft and Hard margins. So we can use SVM kernels here to transform the data into higher dimensions. But the model can create only 1 best-fit line. BECOME a WRITER at MLearning.ai.
While datascience and machine learning are related, they are very different fields. In a nutshell, datascience brings structure to big data while machine learning focuses on learning from the data itself. What is datascience? What is machine learning?
Some common models used are as follows: Logistic Regression – it classifies by predicting the probability of a data point belonging to a class instead of a continuous value Decision Trees – uses a tree structure to make predictions by following a series of branching decisions SupportVectorMachines (SVMs) – create a clear decision (..)
In DataScience, clustering is used to group similar instances together, discovering patterns, hidden structures, and fundamental relationships within a dataset. In this introduction guide, I will formally introduce you to clustering in Machine Learning. You are certainly capable of identifying groups of related books.
Rico Angell (CDS Postdoctoral Researcher) Monitoring LLM Agents for Sequentially Contextual Harm (Building Trust WorkshopPaper) Sam Bowman (CDS Associate Professor of Linguistics and DataScience) Language Models Learn to Mislead Humans via RLHF (Poster) Inverse Scaling: When Bigger Isnt Better (Poster) Beyond the Imitation Game: Quantifying (..)
The field of datascience changes constantly, and some frameworks, tools, and algorithms just can’t get the job done anymore. Machine Learning for Beginners Learn the essentials of machine learning including how SupportVectorMachines, Naive Bayesian Classifiers, and Upper Confidence Bound algorithms work.
DataScience interviews are pivotal moments in the career trajectory of any aspiring data scientist. Having the knowledge about the datascience interview questions will help you crack the interview. DataScience skills that will help you excel professionally.
Summary: The blog explores the synergy between Artificial Intelligence (AI) and DataScience, highlighting their complementary roles in Data Analysis and intelligent decision-making. Introduction Artificial Intelligence (AI) and DataScience are revolutionising how we analyse data, make decisions, and solve complex problems.
Summary: In the tech landscape of 2024, the distinctions between DataScience and Machine Learning are pivotal. DataScience extracts insights, while Machine Learning focuses on self-learning algorithms. The collective strength of both forms the groundwork for AI and DataScience, propelling innovation.
Common Classification Algorithms: Logistic Regression: A popular choice for binary classification, it uses a mathematical function to model the probability of a data point belonging to a particular class. Decision Trees: These work by asking a series of yes/no questions based on data features to classify data points.
Demand forecasting, powered by datascience, helps predict customer needs. Optimize inventory, streamline operations, and make data-driven decisions for success. DataScience empowers businesses to leverage the power of data for accurate and insightful demand forecasts.
Comparison with Other Classification Techniques Associative classification differs from traditional classification methods like decision trees and supportvectormachines (SVM). Understanding these differences can help determine when to use each technique based on the nature of the data and the problem at hand.
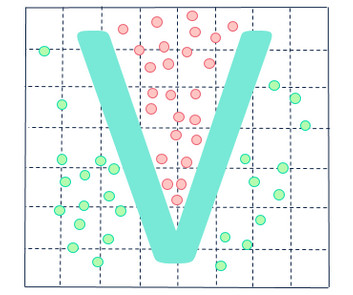
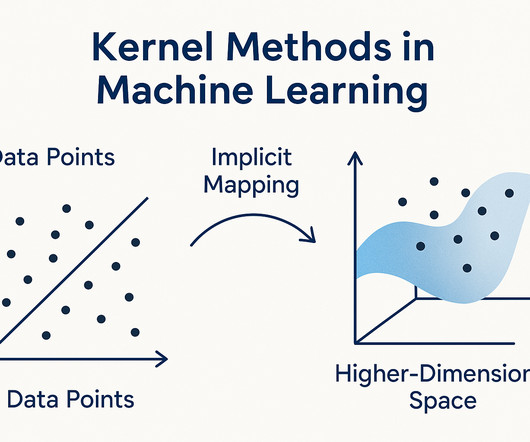
Learn how they work and how to apply them in real-world projects through Pickl.AIs datascience courses. Introduction Machine learning often struggles when the data isnt in a straight lineliterally! This is where kernel methods in machine learning come in like superheroes.
With the expanding field of DataScience, the need for efficient and skilled professionals is increasing. Its efficacy may allow kids from a young age to learn Python and explore the field of DataScience. Its efficacy may allow kids from a young age to learn Python and explore the field of DataScience.
Summary : This article equips Data Analysts with a solid foundation of key DataScience terms, from A to Z. Introduction In the rapidly evolving field of DataScience, understanding key terminology is crucial for Data Analysts to communicate effectively, collaborate effectively, and drive data-driven projects.
R has simplified the most complex task of geospatial machine learning and datascience. As GIS is slowly embracing datascience, mastery of programming is very necessary regardless of your perception of programming. data = trainData) 5.
Hey guys, in this blog we will see some of the most asked DataScience Interview Questions by interviewers in [year]. Datascience has become an integral part of many industries, and as a result, the demand for skilled data scientists is soaring. What is DataScience?
Photo by David Schultz on Unsplash Linfa Linfa is a Rust-based machine-learning library that offers a wide range of algorithms for regression, classification, clustering, and other tasks. One of Linfa’s most notable features is its emphasis on interoperability, achieved through a standardized API for machine learning algorithms.
Understanding the Principles, Challenges, and Applications of Gradient Descent Image by Author with @MidJourney Introduction to Gradient Descent Gradient descent is a fundamental optimization algorithm used in machine learning and datascience to find the optimal values of the parameters in a model.
Machine learning is playing a very important role in improving the functionality of task management applications. In January, Towards DataScience published an article on this very topic. “In Project managers should be aware of the changes that machine learning has brought to task management applications.
In data mining, popular algorithms include decision trees, supportvectormachines, and k-means clustering. This is similar as you consider many factors while you pay someone for essay , which may include referencing, evidence-based argument, cohesiveness, etc.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content