This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
SQL (Structured Query Language) is an important tool for datascientists. It is a programming language used to manipulate data stored in relational databases. Mastering SQL concepts allows a datascientist to quickly analyze large amounts of data and make decisions based on their findings.
In the contemporary age of Big Data, DataWarehouse Systems and Data Science Analytics Infrastructures have become an essential component for organizations to store, analyze, and make data-driven decisions. So why using IaC for Cloud Data Infrastructures?
When it comes to data, there are two main types: data lakes and datawarehouses. What is a data lake? An enormous amount of raw data is stored in its original format in a data lake until it is required for analytics applications. To preserve your digital assets, data must lastly be secured.
It allows datascientists and machine learning engineers to interact with their data and models and to visualize and share their work with others with just a few clicks. SageMaker Canvas has also integrated with Data Wrangler , which helps with creating data flows and preparing and analyzing your data.
Amazon SageMaker Studio provides a fully managed solution for datascientists to interactively build, train, and deploy machine learning (ML) models. In the process of working on their ML tasks, datascientists typically start their workflow by discovering relevant data sources and connecting to them.
These experiences facilitate professionals from ingesting data from different sources into a unified environment and pipelining the ingestion, transformation, and processing of data to developing predictive models and analyzing the data by visualization in interactive BI reports.
Many of these applications are complex to build because they require collaboration across teams and the integration of data, tools, and services. Data engineers use datawarehouses, data lakes, and analytics tools to load, transform, clean, and aggregate data. option("multiLine", "true").option("header",
Data is reported from one central repository, enabling management to draw more meaningful business insights and make faster, better decisions. By running reports on historical data, a datawarehouse can clarify what systems and processes are working and what methods need improvement.
One study found that 44% of companies that hire datascientists say the departments are seriously understaffed. Fortunately, datascientists can make due with fewer staff if they use their resources more efficiently, which involves leveraging the right tools. The data is processed and modified after it has been extracted.
Discover the nuanced dissimilarities between Data Lakes and DataWarehouses. Data management in the digital age has become a crucial aspect of businesses, and two prominent concepts in this realm are Data Lakes and DataWarehouses. It acts as a repository for storing all the data.
Azure Synapse Analytics can be seen as a merge of Azure SQLDataWarehouse and Azure Data Lake. Synapse allows one to use SQL to query petabytes of data, both relational and non-relational, with amazing speed. I have not gotten a chance to try it out yet, so I am not sure its usecase for data science yet.
Summary: This blog provides a comprehensive roadmap for aspiring Azure DataScientists, outlining the essential skills, certifications, and steps to build a successful career in Data Science using Microsoft Azure. This roadmap aims to guide aspiring Azure DataScientists through the essential steps to build a successful career.
In this article, we will delve into the concept of data lakes, explore their differences from datawarehouses and relational databases, and discuss the significance of data version control in the context of large-scale data management. Schema Enforcement: Datawarehouses use a “schema-on-write” approach.
Many of the RStudio on SageMaker users are also users of Amazon Redshift , a fully managed, petabyte-scale, massively parallel datawarehouse for data storage and analytical workloads. It makes it fast, simple, and cost-effective to analyze all your data using standard SQL and your existing business intelligence (BI) tools.
Amazon Redshift is the most popular cloud datawarehouse that is used by tens of thousands of customers to analyze exabytes of data every day. You can use query_string to filter your dataset by SQL and unload it to Amazon S3. If you’re familiar with SageMaker and writing Spark code, option B could be your choice.
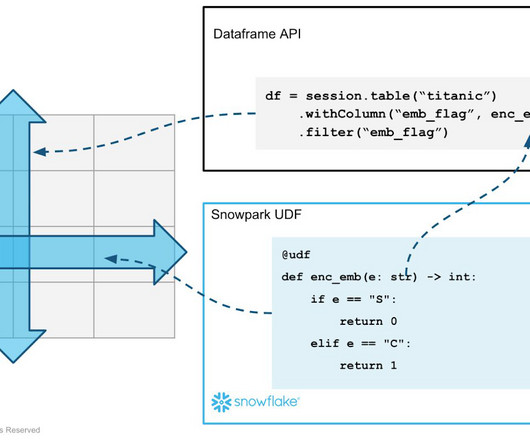
[link] Ahmad Khan, head of artificial intelligence and machine learning strategy at Snowflake gave a presentation entitled “Scalable SQL + Python ML Pipelines in the Cloud” about his company’s Snowpark service at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. Welcome everybody.
[link] Ahmad Khan, head of artificial intelligence and machine learning strategy at Snowflake gave a presentation entitled “Scalable SQL + Python ML Pipelines in the Cloud” about his company’s Snowpark service at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. Welcome everybody.
Overview: Data science vs data analytics Think of data science as the overarching umbrella that covers a wide range of tasks performed to find patterns in large datasets, structure data for use, train machine learning models and develop artificial intelligence (AI) applications.
They are also designed to handle concurrent access by multiple users and applications, while ensuring data integrity and transactional consistency. Examples of OLTP databases include Oracle Database, Microsoft SQL Server, and MySQL. OLAP systems support business intelligence, data mining, and other decision support applications.
The Microsoft Certified Solutions Associate and Microsoft Certified Solutions Expert certifications cover a wide range of topics related to Microsoft’s technology suite, including Windows operating systems, Azure cloud computing, Office productivity software, Visual Studio programming tools, and SQL Server databases.
Its goal is to help with a quick analysis of target characteristics, training vs testing data, and other such data characterization tasks. Apache Superset GitHub | Website Apache Superset is a must-try project for any ML engineer, datascientist, or data analyst.
Run pandas at scale on your datawarehouse Most enterprise data teams store their data in a database or datawarehouse, such as Snowflake, BigQuery, or DuckDB. Ponder solves this problem by translating your pandas code to SQL that can be understood by your datawarehouse.
These days, datascientists are in high demand. Across the country, datascientists have an unemployment rate of 2% and command an average salary of nearly $100,000. For these reasons, finding and evaluating data is often time-consuming. How Data Catalogs Help DataScientists Ask Better Questions.
Codd published his famous paper “ A Relational Model of Data for Large Shared Data Banks.” Boyce to create Structured Query Language (SQL). Developers can leverage features like REST APIs, JSON support and enhanced SQL compatibility to easily build cloud-native applications. Chamberlin and Raymond F.
Unfolding the difference between data engineer, datascientist, and data analyst. Data engineers are essential professionals responsible for designing, constructing, and maintaining an organization’s data infrastructure. Role of DataScientistsDataScientists are the architects of data analysis.
Each snapshot has a separate manifest file that keeps track of the data files associated with that snapshot and hence can be restored/queries whenever needed. Versioning also ensures a safer experimentation environment, where datascientists can test new models or hypotheses on historical data snapshots without impacting live data.
In the previous blog , we discussed how Alation provides a platform for datascientists and analysts to complete projects and analysis at speed. In this blog we will discuss how Alation helps minimize risk with active data governance. But governance is a time-consuming process (for users and data stewards alike).
It is a crucial data integration process that involves moving data from multiple sources into a destination system, typically a datawarehouse. This process enables organisations to consolidate their data for analysis and reporting, facilitating better decision-making. ETL stands for Extract, Transform, and Load.
The modern data stack is a combination of various software tools used to collect, process, and store data on a well-integrated cloud-based data platform. It is known to have benefits in handling data due to its robustness, speed, and scalability. A typical modern data stack consists of the following: A datawarehouse.
The ultimate need for vast storage spaces manifests in datawarehouses: specialized systems that aggregate data coming from numerous sources for centralized management and consistency. In this article, you’ll discover what a Snowflake datawarehouse is, its pros and cons, and how to employ it efficiently.
A rigid data model such as Kimball or Data Vault would ruin this flexibility and essentially transform your data lake into a datawarehouse. However, some flexible data modeling techniques can be used to allow for some organization while maintaining the ease of new data additions.
The rules in this engine were predefined and written in SQL, which aside from posing a challenge to manage, also struggled to cope with the proliferation of data from TR’s various integrated data source. TR customer data is changing at a faster rate than the business rules can evolve to reflect changing customer needs.
Jupyter notebooks have been one of the most controversial tools in the data science community. Nevertheless, many datascientists will agree that they can be really valuable – if used well. Data on its own is not sufficient for a cohesive story. in a pandas DataFrame) but in the company’s datawarehouse (e.g.,
Role of Data Engineers in the Data Ecosystem Data Engineers play a crucial role in the data ecosystem by bridging the gap between raw data and actionable insights. They are responsible for building and maintaining data architectures, which include databases, datawarehouses, and data lakes.
Within watsonx.ai, users can take advantage of open-source frameworks like PyTorch, TensorFlow and scikit-learn alongside IBM’s entire machine learning and data science toolkit and its ecosystem tools for code-based and visual data science capabilities.
Datawarehouses are a critical component of any organization’s technology ecosystem. The next generation of IBM Db2 Warehouse brings a host of new capabilities that add cloud object storage support with advanced caching to deliver 4x faster query performance than previously, while cutting storage costs by 34x 1.
Hive is a data warehousing infrastructure built on top of Hadoop. It has the following features: It facilitates querying, summarizing, and analyzing large datasets Hadoop also provides a SQL-like language called HiveQL Hive allows users to write queries to extract valuable insights from structured and semi-structured data stored in Hadoop.
The primary goal of Data Engineering is to transform raw data into a structured and usable format that can be easily accessed, analyzed, and interpreted by DataScientists, analysts, and other stakeholders. Future of Data Engineering The Data Engineering market will expand from $18.2
As businesses continue to adopt Machine Learning at a rapid pace, their datascientists need tools that are all about time-to-value. With Hex , it has never been easier to unlock insights from your data. Flexible Execution Hex logic can be built with SQL, Python, R, and no-code cells.
Data Engineering is one of the most productive job roles today because it imbibes both the skills required for software engineering and programming and advanced analytics needed by DataScientists. How to Become an Azure Data Engineer? Having experience using at least one end-to-end Azure data lake project.
Challenges of data science Across most companies, finding, cleaning and preparing the proper data for analysis can take up to 80% of a datascientist’s day. Data from various sources, collected in different forms, require data entry and compilation.
Data engineering is a rapidly growing field, and there is a high demand for skilled data engineers. If you are a datascientist, you may be wondering if you can transition into data engineering. The good news is that there are many skills that datascientists already have that are transferable to data engineering.
Prime examples of this in the data catalog include: Trust Flags — Allow the data community to endorse, warn, and deprecate data to signal whether data can or can’t be used. Data Profiling — Statistics such as min, max, mean, and null can be applied to certain columns to understand its shape.
This comprehensive blog outlines vital aspects of Data Analyst interviews, offering insights into technical, behavioural, and industry-specific questions. It covers essential topics such as SQL queries, data visualization, statistical analysis, machine learning concepts, and data manipulation techniques.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content