This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Telling a Great Data Story: A Visualization DecisionTree; What Is the Difference Between SQL and Object-Relational Mapping (ORM)?; Top 7 YouTube Courses on Data Analytics ; How Much Do DataScientists Make in 2022?; Design Patterns in Machine Learning for MLOps.
Also: DecisionTree Algorithm, Explained; Naïve Bayes Algorithm: Everything You Need to Know; Why Are So Many DataScientists Quitting Their Jobs?; Top Programming Languages and Their Uses.
Also: DecisionTree Algorithm, Explained; Data Science Projects That Will Land You The Job in 2022; The 6 Python Machine Learning Tools Every DataScientist Should Know About; Naïve Bayes Algorithm: Everything You Need to Know.
Also: DecisionTree Algorithm, Explained; 15 Python Coding Interview Questions You Must Know For Data Science; Naïve Bayes Algorithm: Everything You Need to Know; Primary Supervised Learning Algorithms Used in Machine Learning.
Sensor data : Sensor data can be used to train models for tasks such as object detection and anomaly detection. This data can be collected from a variety of sources, such as smartphones, wearable devices, and traffic cameras. Machine learning practices for datascientists 3.
Want to know how to become a Datascientist? Use data to uncover patterns, trends, and insights that can help businesses make better decisions. A datascientist could analyze sales data, customer surveys, and social media trends to determine the reason. It’s like deciphering a secret code.
10 Cheat Sheets You Need To Ace Data Science Interview • 3 Valuable Skills That Have Doubled My Income as a DataScientist • How to Select Rows and Columns in Pandas Using [ ],loc, iloc,at and.iat • The Complete Free PyTorch Course for Deep Learning • DecisionTree Algorithm, Explained.
Also: DecisionTree Algorithm, Explained; 8 Free MIT Courses to Learn Data Science Online; Why Are So Many DataScientists Quitting Their Jobs?; Top Programming Languages and Their Uses.
Datascientists use data to uncover patterns, trends, and insights that can help businesses make better decisions. A datascientist could analyze sales data, customer surveys, and social media trends to determine the reason. Handling Uncertainty: Data is often messy and incomplete.
If you’ve found yourself asking, “How to become a datascientist?” In this detailed guide, we’re going to navigate the exciting realm of data science, a field that blends statistics, technology, and strategic thinking into a powerhouse of innovation and insights. What is a datascientist?
A Comprehensive AI Guide All Machine Learning Engineers and DataScientists Should Read! This is the essence of a decisiontree—one of today’s most intuitive and powerful machine learning algorithms. This is the essence of a decisiontree—one of today’s most intuitive and powerful machine learning algorithms.
In this video presentation, our good friend Jon Krohn, Co-Founder and Chief DataScientist at the machine learning company Nebula, is joined by Kirill Eremenko to walk listeners through why decisiontrees and random forests are fruitful for businesses, and he offers hands-on walkthroughs for the three leading gradient-boosting algorithms today: XGBoost, (..)
Understanding DecisionTrees for Classification in Python; How to Become More Marketable as a DataScientist; Is Kaggle Learn a Faster Data Science Education? Also: Deep Learning for NLP: Creating a Chatbot with Keras!;
This post is about fast-tracking the study and explanation of tree concepts for the datascientists so that you breeze through the next time you get asked these in an interview.
Learn about 33 tools to visualize data with this blog In this blog post, we will delve into some of the most important plots and concepts that are indispensable for any datascientist. 9 Data Science Plots – Data Science Dojo 1. Suppose you are a datascientist working for an e-commerce company.
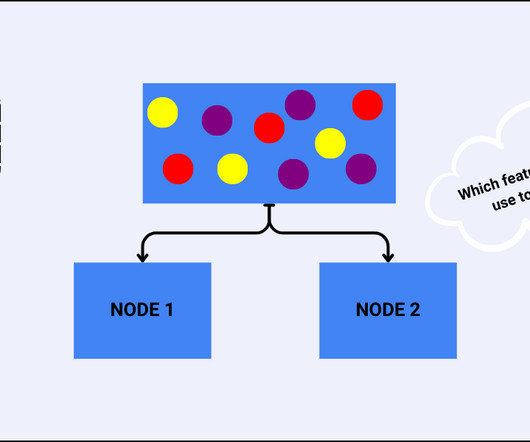
In data science and machine learning, decisiontrees are powerful models for both classification and regression tasks. It is a measure of impurity (non-homogeneity) widely used in decisiontrees. They follow a top-down greedy approach to select the best feature for each split. What is the Gini Index?
The American Owners in the eternal meeting [Image by the author + AI] Finally, a rumor began to circulate that the owners were locked away in a room with the top DataScientists worldwide, analyzing every detail,… Read the full blog for free on Medium. Join thousands of data leaders on the AI newsletter.
Statistics: Unveiling the patterns within data Statistics serves as the bedrock of data science, providing the tools and techniques to collect, analyze, and interpret data. It equips datascientists with the means to uncover patterns, trends, and relationships hidden within complex datasets.
XGBoost has gained a formidable reputation in the realm of machine learning, becoming a go-to choice for practitioners and datascientists alike. DecisiontreesDecisiontrees form the backbone of XGBoost. Advantages of XGBoost Many attributes contribute to XGBoost’s preference among datascientists.
The job market for datascientists is booming. In fact, the demand for data experts is expected to grow by 36% between 2021 and 2031, significantly higher than the average for all occupations. This is great news for anyone who is interested in a career in data science. According to the U.S.
Gradient boosting involves training a series of weak learners (often decisiontrees) where each subsequent tree corrects the errors of the previous ones, creating a strong predictive model. This structure speeds up calculations and makes the model more interpretable.
Unsupervised models Unsupervised models typically use traditional statistical methods such as logistic regression, time series analysis, and decisiontrees. These methods analyze data without pre-labeled outcomes, focusing on discovering patterns and relationships.
Its visually appealing interface and the ability to add custom scripts in various programming languages make it a preferred choice among novice and seasoned datascientists. This post will delve into one of the many facets of KNIME’s capabilities –building predictive models using decisiontrees and random forests.
This discipline takes raw data, deciphers it, and turns it into a digestible format using various tools and algorithms. Tools such as Python, R, and SQL help to manipulate and analyze data. Statistics helps datascientists to estimate, predict and test hypotheses.
They provide a foundational understanding and a reference point from which datascientists can gauge the performance of advanced algorithms. Decisiontrees: Provide interpretable predictions based on logical rules. By understanding their performance, datascientists can design and refine complex algorithms effectively.
By providing a clear numerical representation of similarity, Hellinger Distance aids researchers and datascientists in understanding and analyzing complex problems with ease. In machine learning: – Improves decisiontree algorithms, particularly in the node-splitting phase, adding precision to predictions.
To help you make an informed decision, here are detailed tips on how to select the ideal data science bootcamp for your unique needs: The challenge: Choosing the right data science bootcamp Outline your career goals: What do you want to do with a data science degree?
Statistical analysis and hypothesis testing Statistical methods provide powerful tools for understanding data. An Applied DataScientist must have a solid understanding of statistics to interpret data correctly. Machine learning algorithms Machine learning forms the core of Applied Data Science.
During the data preprocessing phase, handling categorical data can consume considerable time for datascientists, making it a crucial aspect of model preparation. This includes converting categorical data into numerical values, which is often necessary for algorithms to work effectively.
It identifies hidden patterns in data, making it useful for decision-making across industries. Compared to decisiontrees and SVM, it provides interpretable rules but can be computationally intensive. Key applications include fraud detection, customer segmentation, and medical diagnosis.
By focusing on finding the optimal decision boundary between different classes of data, SVMs have stood out in both academic research and practical applications. Their ability to handle high-dimensional spaces and to create precise models in varied environments captures the interest of many datascientists and analysts.
A DataScientist’s average salary in India is up to₹ 8.0 Well, one of the key factors drawing attention towards the DataScientist job profile is the higher pay package. In fact, the highest salary of a DataScientist in India can be up to ₹ 26.0 DataScientist Salary in Hyderabad : ₹ 8.0
A cheat sheet for DataScientists is a concise reference guide, summarizing key concepts, formulas, and best practices in Data Analysis, statistics, and Machine Learning. It serves as a handy quick-reference tool to assist data professionals in their work, aiding in data interpretation, modeling , and decision-making processes.
Decisiontrees: They segment data into branches based on sequential questioning. Unsupervised algorithms In contrast, unsupervised algorithms analyze data without pre-existing labels, identifying inherent structures and patterns. Random forest: Combines multiple decisiontrees to strengthen predictive capabilities.
Imbalanced data is a common issue faced by datascientists and machine learning practitioners. As the prevalence of data-driven decision-making increases, understanding the implications of imbalanced data is crucial for developing effective algorithms that can accurately classify observations despite uneven class distributions.
Read more about classification using decisiontrees Threshold Selection In practice, ROC curves greatly help in the selection of the optimal threshold for classification problems.
This process helps mitigate the high bias often seen in shallow decisiontrees and logistic regression models. By understanding and leveraging boosting algorithms applications, datascientists and machine learning practitioners can unlock new levels of performance in their predictive modelling endeavours.
But how can machine learning practitioners improve the reliability of their models, particularly when dealing with tabular data? Lucena attributes its dominance to the way gradient boosted decisiontrees (GBDTs) handle structured information.
Data Sourcing. Fundamental to any aspect of data science, it’s difficult to develop accurate predictions or craft a decisiontree if you’re garnering insights from inadequate data sources.
Currently pursuing graduate studies at NYU's center for data science. Alejandro Sáez: DataScientist with consulting experience in the banking and energy industries currently pursuing graduate studies at NYU's center for data science. We trained one LightGBM model per airport.
Heres what we noticed from analyzing this data, highlighting whats remained the same over the years, and what additions help make the modern datascientist in2025. Data Science Of course, a datascientist should know data science! Joking aside, this does infer particular skills.
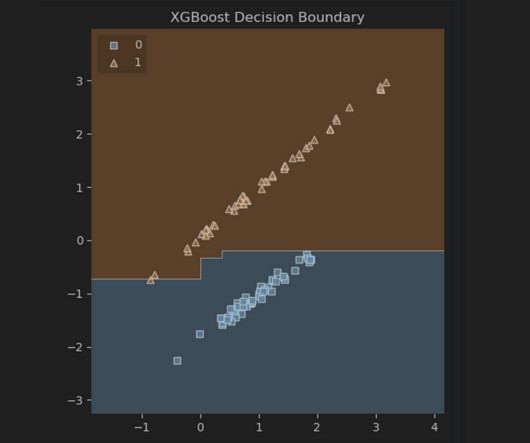
Mastering Tree-Based Models in Machine Learning: A Practical Guide to DecisionTrees, Random Forests, and GBMs Image created by the author on Canva Ever wondered how machines make complex decisions? Just like a tree branches out, tree-based models in machine learning do something similar. So buckle up!
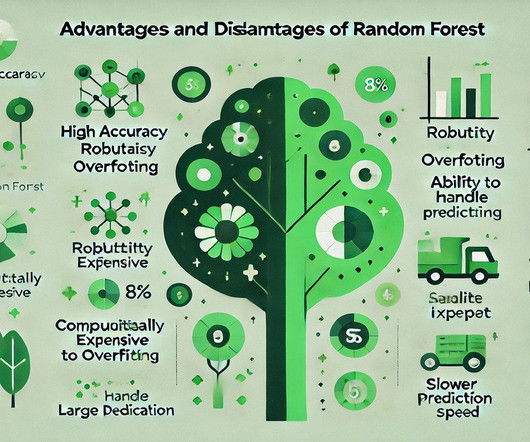
It builds multiple decisiontrees and merges them to produce accurate and stable predictions, making it a popular choice for complex data problems. Understanding these pros and cons will help you decide when to effectively utilise Random Forest in your Data Analysis projects. What is Random Forest?
Most commercially available AI tools are black-box, meaning they do not cite what they generate or make it easy for datascientists to discover where the AI-derived information. It uses data mining techniques like decisiontrees and rule-based systems to generate correct responses.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content