This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Also: DecisionTree Algorithm, Explained; 15 Python Coding Interview Questions You Must Know For Data Science; Naïve Bayes Algorithm: Everything You Need to Know; Primary SupervisedLearning Algorithms Used in Machine Learning.
Their ability to handle high-dimensional spaces and to create precise models in varied environments captures the interest of many datascientists and analysts. Support Vector Machines (SVM) are a type of supervisedlearning algorithm designed for classification and regression tasks. What are Support Vector Machines (SVM)?
Its visually appealing interface and the ability to add custom scripts in various programming languages make it a preferred choice among novice and seasoned datascientists. This post will delve into one of the many facets of KNIME’s capabilities –building predictive models using decisiontrees and random forests.
It identifies hidden patterns in data, making it useful for decision-making across industries. Compared to decisiontrees and SVM, it provides interpretable rules but can be computationally intensive. Key applications include fraud detection, customer segmentation, and medical diagnosis.
To harness this data effectively, researchers and programmers frequently employ machine learning to enhance user experiences. Emerging daily are sophisticated methodologies for datascientists encompassing supervised, unsupervised, and reinforcement learning techniques. What is supervisedlearning?
Although there are many types of learning, Michalski defined the two most common types of learning: SupervisedLearning. Unsupervised Learning. Both of these types of learning are used by machine learning algorithms in modern task management applications. SupervisedLearning.
Machine learning types Machine learning algorithms fall into five broad categories: supervisedlearning, unsupervised learning, semi-supervisedlearning, self-supervised and reinforcement learning. the target or outcome variable is known). temperature, salary).
In this blog we’ll go over how machine learning techniques, powered by artificial intelligence, are leveraged to detect anomalous behavior through three different anomaly detection methods: supervised anomaly detection, unsupervised anomaly detection and semi-supervised anomaly detection.
Summary: This blog highlights ten crucial Machine Learning algorithms to know in 2024, including linear regression, decisiontrees, and reinforcement learning. Introduction Machine Learning (ML) has rapidly evolved over the past few years, becoming an integral part of various industries, from healthcare to finance.
The remaining features are horizontally appended to the pathology features, and a gradient boosted decisiontree classifier (LightGBM) is applied to achieve predictive analysis. To further improve performance, a self-supervisedlearning-based approach, namely Hierarchical Image Pyramid Transformer (HIPT) ( Chen et al.,
Photo by Robo Wunderkind on Unsplash In general , a datascientist should have a basic understanding of the following concepts related to kernels in machine learning: 1. Support Vector Machine Support Vector Machine ( SVM ) is a supervisedlearning algorithm used for classification and regression analysis.
Summary: Inductive bias in Machine Learning refers to the assumptions guiding models in generalising from limited data. By managing inductive bias effectively, datascientists can improve predictions, ensuring models are robust and well-suited for real-world applications.
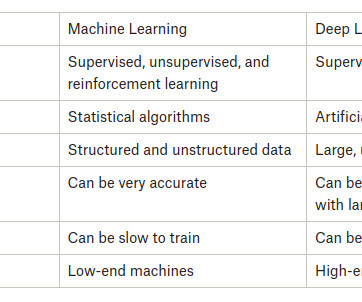
The main types are supervised, unsupervised, and reinforcement learning, each with its techniques and applications. SupervisedLearning In SupervisedLearning , the algorithm learns from labelled data, where the input data is paired with the correct output. predicting house prices).
Machine Learning algorithms are trained on large amounts of data, and they can then use that data to make predictions or decisions about new data. There are three main types of Machine Learning: supervisedlearning, unsupervised learning, and reinforcement learning.
Explore Machine Learning with Python: Become familiar with prominent Python artificial intelligence libraries such as sci-kit-learn and TensorFlow. Begin by employing algorithms for supervisedlearning such as linear regression , logistic regression, decisiontrees, and support vector machines.
Solution overview In this post, we demonstrate how to fine-tune a sentence transformer with Amazon product data and how to use the resulting sentence transformer to improve classification accuracy of product categories using an XGBoost decisiontree. Kara is passionate about innovation and continuous learning.
It processes enormous amounts of data a human wouldn’t be able to work through in a lifetime and evolves as more data is processed. Challenges of data science Across most companies, finding, cleaning and preparing the proper data for analysis can take up to 80% of a datascientist’s day.
Data Science is the art and science of extracting valuable information from data. It encompasses data collection, cleaning, analysis, and interpretation to uncover patterns, trends, and insights that can drive decision-making and innovation.
Data Science interviews are pivotal moments in the career trajectory of any aspiring datascientist. Having the knowledge about the data science interview questions will help you crack the interview. Differentiate between supervised and unsupervised learning algorithms.
These techniques span different types of learning and provide powerful tools to solve complex real-world problems. SupervisedLearningSupervisedlearning is one of the most common types of Machine Learning, where the algorithm is trained using labelled data.
Instead of memorizing the training data, the objective is to create models that precisely predict unobserved instances. Supervised, unsupervised, and reinforcement learning : Machine learning can be categorized into different types based on the learning approach. We pay our contributors, and we don't sell ads.
Big Data and Machine Learning The intersection of Big Data and Machine Learning is a critical area of focus in a Big Data syllabus. Students should learn how to leverage Machine Learning algorithms to extract insights from large datasets.
Machine learning is a subset of artificial intelligence that enables computers to learn from data and improve over time without being explicitly programmed. Explain the difference between supervised and unsupervised learning. What are the advantages and disadvantages of decisiontrees ?
Statistics Descriptive statistics includes techniques like mean, median, and standard deviation to help summarise data. Hypothesis testing and regression analysis are crucial for making predictions and understanding data relationships. Job Roles Several key roles in AI and Data Science offer diverse and rewarding career paths.
At the core of machine learning, two primary learning techniques drive these innovations. These are known as supervisedlearning and unsupervised learning. Supervisedlearning and unsupervised learning differ in how they process data and extract insights.
Amazon SageMaker Canvas is a no-code workspace that enables analysts and citizen datascientists to generate accurate machine learning (ML) predictions for their business needs. Random forest: A tree-based algorithm that uses several decisiontrees on random sub-samples of the data with replacement.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
































Let's personalize your content