This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
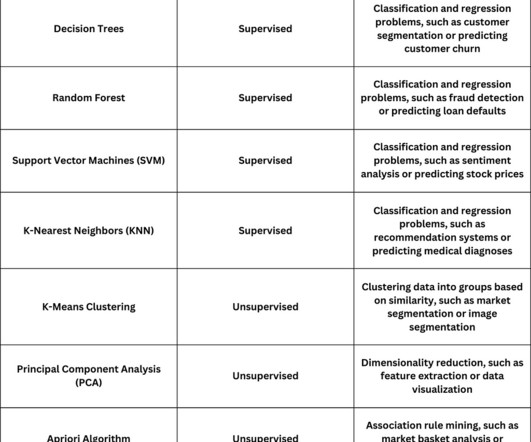
SupportVectorMachines (SVM) are a cornerstone of machine learning, providing powerful techniques for classifying and predicting outcomes in complex datasets. By focusing on finding the optimal decision boundary between different classes of data, SVMs have stood out in both academic research and practical applications.
Sensor data : Sensor data can be used to train models for tasks such as object detection and anomaly detection. This data can be collected from a variety of sources, such as smartphones, wearable devices, and traffic cameras. Machine learning practices for datascientists 3.
Statistics: Unveiling the patterns within data Statistics serves as the bedrock of data science, providing the tools and techniques to collect, analyze, and interpret data. It equips datascientists with the means to uncover patterns, trends, and relationships hidden within complex datasets.
It identifies hidden patterns in data, making it useful for decision-making across industries. Compared to decisiontrees and SVM, it provides interpretable rules but can be computationally intensive. Lets explore some of the popular software solutions that support associative classification.
This data set establishes a pattern that can make predictions, In other words, based on the examples of the training set in which each example is labeled with the corresponding answer, the datascientist parameterizes an algorithm that finds the patterns that determine the result based on the entries. Naïve Bayes classification.
Photo by Robo Wunderkind on Unsplash In general , a datascientist should have a basic understanding of the following concepts related to kernels in machine learning: 1. SupportVectorMachineSupportVectorMachine ( SVM ) is a supervised learning algorithm used for classification and regression analysis.
Tree-Based Algorithms: Algorithms like decisiontrees and random forests can handle label-encoded data well because they can naturally work with the integer representation of categories. For example, education levels, satisfaction ratings, or any other feature with an inherent order.
Mastering Tree-Based Models in Machine Learning: A Practical Guide to DecisionTrees, Random Forests, and GBMs Image created by the author on Canva Ever wondered how machines make complex decisions? Just like a tree branches out, tree-based models in machine learning do something similar.
Heres what we noticed from analyzing this data, highlighting whats remained the same over the years, and what additions help make the modern datascientist in2025. Data Science Of course, a datascientist should know data science! Joking aside, this does infer particular skills.
Supervised machine learning Supervised machine learning is a type of machine learning where the model is trained on a labeled dataset (i.e., Classification algorithms include logistic regression, k-nearest neighbors and supportvectormachines (SVMs), among others. the target or outcome variable is known).
Summary: This blog highlights ten crucial Machine Learning algorithms to know in 2024, including linear regression, decisiontrees, and reinforcement learning. Introduction Machine Learning (ML) has rapidly evolved over the past few years, becoming an integral part of various industries, from healthcare to finance.
Photo by Andy Kelly on Unsplash Choosing a machine learning (ML) or deep learning (DL) algorithm for application is one of the major issues for artificial intelligence (AI) engineers and also datascientists. Experiment and evaluate: Implement the algorithms you have selected and evaluate their performance on your data.
K-Nearest Neighbours (kNN) In order to calculate the distance between one data point and every other accomplished parameter through using the metrics of distance like Euclidean distance, Manhattan distance and others. DecisionTreesDecisionTrees are non-linear model unlike the logistic regression which is a linear model.
Summary: Inductive bias in Machine Learning refers to the assumptions guiding models in generalising from limited data. By managing inductive bias effectively, datascientists can improve predictions, ensuring models are robust and well-suited for real-world applications.
Key Components In Data Science, key components include data cleaning, Exploratory Data Analysis, and model building using statistical techniques. ML focuses on algorithms like decisiontrees, neural networks, and supportvectormachines for pattern recognition. over the specified period.
Explore Machine Learning with Python: Become familiar with prominent Python artificial intelligence libraries such as sci-kit-learn and TensorFlow. Begin by employing algorithms for supervised learning such as linear regression , logistic regression, decisiontrees, and supportvectormachines.
These powerful tools can find patterns from input data and make assumptions about what data is perceived as normal. These techniques can go a long way in discovering unknown anomalies and reducing the work of manually sifting through large data sets.
It processes enormous amounts of data a human wouldn’t be able to work through in a lifetime and evolves as more data is processed. Challenges of data science Across most companies, finding, cleaning and preparing the proper data for analysis can take up to 80% of a datascientist’s day.
Hands-on Project Why customer churn matters and how to predict it with machine learning, explained step-by-step Photo by Gabrielle Ribeiro on Unsplash Introduction In today’s competitive business environment, retaining customers is essential to a company’s success. Captures complex relationships in data.
DecisionTreesDecisiontrees recursively partition data into subsets based on the most significant attribute values. Python’s Scikit-learn provides easy-to-use interfaces for constructing decisiontree classifiers and regressors, enabling intuitive model visualisation and interpretation.
Data Science interviews are pivotal moments in the career trajectory of any aspiring datascientist. Having the knowledge about the data science interview questions will help you crack the interview. Supervised learning algorithms learn from labelled data, where each input is associated with a corresponding output label.
Scikit-learn A machine learning powerhouse, Scikit-learn provides a vast collection of algorithms and tools, making it a go-to library for many datascientists. It is easy to use, with a well-documented API and a wide range of tutorials and examples available.
NRE is a complex task that involves multiple steps and requires sophisticated machine learning algorithms like Hidden Markov Models (HMMs) , Conditional Random Fields (CRFs), and SupportVectorMachines (SVMs) be present. We’re committed to supporting and inspiring developers and engineers from all walks of life.
Data Science is the art and science of extracting valuable information from data. It encompasses data collection, cleaning, analysis, and interpretation to uncover patterns, trends, and insights that can drive decision-making and innovation.
Hey guys, in this blog we will see some of the most asked Data Science Interview Questions by interviewers in [year]. Data science has become an integral part of many industries, and as a result, the demand for skilled datascientists is soaring. Overfitting: The model performs well only for the sample training data.
Selecting an Algorithm Choosing the correct Machine Learning algorithm is vital to the success of your model. For example, linear regression is typically used to predict continuous variables, while decisiontrees are great for classification and regression tasks. Decisiontrees are easy to interpret but prone to overfitting.
Machine Learning and Neural Networks (1990s-2000s): Machine Learning (ML) became a focal point, enabling systems to learn from data and improve performance without explicit programming. Techniques such as decisiontrees, supportvectormachines, and neural networks gained popularity.
The concepts of bias and variance in Machine Learning are two crucial aspects in the realm of statistical modelling and machine learning. Understanding these concepts is paramount for any datascientist, machine learning engineer, or researcher striving to build robust and accurate models.
Background Information Decisiontrees, random forests, and linear regression are just a few examples of classic machine-learning models that have been used extensively in business for years. The n_estimators argument is set to 100, meaning that 100 decisiontrees will be used in the forest.
Students should learn how to leverage Machine Learning algorithms to extract insights from large datasets. Key topics include: Supervised Learning Understanding algorithms such as linear regression, decisiontrees, and supportvectormachines, and their applications in Big Data.
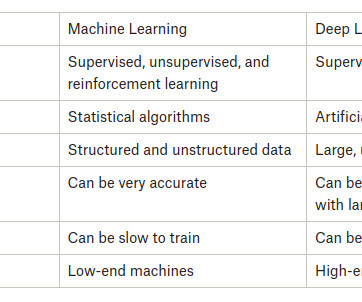
Model Complexity Machine Learning : Traditional machine learning models have fewer parameters and a simpler structure than deep learning models. They typically rely on simpler algorithms like decisiontrees, supportvectormachines, or linear regression.
Although MLOps is an abbreviation for ML and operations, don’t let it confuse you as it can allow collaborations among datascientists, DevOps engineers, and IT teams. Model Training Frameworks This stage involves the process of creating and optimizing the predictive models with labeled and unlabeled data.
RFE works effectively with algorithms like SupportVectorMachines (SVMs) and linear regression. Tree-Based Methods Decisiontrees and ensemble methods like Random Forest and Gradient Boosting inherently perform feature selection. For tree-based models, importance scores are derived from decision splits.
They process data, identify patterns, and adjust the model accordingly. Common algorithms include decisiontrees, neural networks, and supportvectormachines. Data : Data serves as the foundation for ML.
DecisionTrees These trees split data into branches based on feature values, providing clear decision rules. SupportVectorMachines (SVM) SVMs are powerful classifiers that separate data into distinct categories by finding an optimal hyperplane.
Hypothesis testing and regression analysis are crucial for making predictions and understanding data relationships. Machine Learning Supervised Learning includes algorithms like linear regression, decisiontrees, and supportvectormachines.
Hybrid machine learning techniques excel in model selection by amalgamating the strengths of multiple models. By combining, for example, a decisiontree with a supportvectormachine (SVM), these hybrid models leverage the interpretability of decisiontrees and the robustness of SVMs to yield superior predictions in medicine.
Decisiontrees: They segment data into branches based on sequential questioning. Unsupervised algorithms In contrast, unsupervised algorithms analyze data without pre-existing labels, identifying inherent structures and patterns. Random forest: Combines multiple decisiontrees to strengthen predictive capabilities.
Some common supervised learning algorithms include decisiontrees, random forests, supportvectormachines, and linear regression. These algorithms help businesses make decisions when there is clear historical data available. Preparing labeled data takes time and effort.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












































Let's personalize your content