This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The Challenge Legal texts are uniquely challenging for naturallanguageprocessing (NLP) due to their specialized vocabulary, intricate syntax, and the critical importance of context. Terms that appear similar in general language can have vastly different meanings in legal contexts.
It could explain how these distributions are used in different machine learning algorithms and why understanding them is crucial for datascientists. 32 datasets to uplift your skills in data science Data Science Dojo has created an archive of 32 data sets for you to use to practice and improve your skills as a datascientist.
t-SNE (t-distributed stochastic neighbor embedding) has become an essential tool in the realm of data analytics, standing out for its ability to unravel the complexities inherent in high-dimensional data.
It could explain how these distributions are used in different machine learning algorithms and why understanding them is crucial for datascientists. The data sets are categorized according to varying difficulty levels to be suitable for everyone. This blog will discuss the different naturallanguageprocessing applications.
Some of the applications of data science are driverless cars, gaming AI, movie recommendations, and shopping recommendations. Since the field covers such a vast array of services, datascientists can find a ton of great opportunities in their field. Datascientists use algorithms for creating data models.
Similar to traditional Machine Learning Ops (MLOps), LLMOps necessitates a collaborative effort involving datascientists, DevOps engineers, and IT professionals. Some projects may necessitate a comprehensive LLMOps approach, spanning tasks from data preparation to pipeline production.
Learn NLP dataprocessing operations with NLTK, visualize data with Kangas , build a spam classifier, and track it with Comet Machine Learning Platform Photo by Stephen Phillips — Hostreviews.co.uk Many data we analyze as datascientists consist of a corpus of human-readable text.
Learn how DataScientists use ChatGPT, a potent OpenAI language model, to improve their operations. ChatGPT is essential in the domains of naturallanguageprocessing, modeling, dataanalysis, data cleaning, and data visualization. It also improves dataanalysis.
Summary: This blog provides a comprehensive roadmap for aspiring Azure DataScientists, outlining the essential skills, certifications, and steps to build a successful career in Data Science using Microsoft Azure. This roadmap aims to guide aspiring Azure DataScientists through the essential steps to build a successful career.
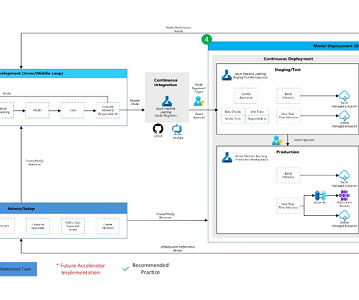
By implementing a modern naturallanguageprocessing (NLP) model, the response process has been shaped much more efficiently, and waiting time for clients has been reduced tremendously. This merge event now triggers a SageMaker Pipelines job using production data for training purposes.
Answering one of the most common questions I get asked as a Senior DataScientist — What skills and educational background are necessary to become a datascientist? Photo by Eunice Lituañas on Unsplash To become a datascientist, a combination of technical skills and educational background is typically required.
And retailers frequently leverage data from chatbots and virtual assistants, in concert with ML and naturallanguageprocessing (NLP) technology, to automate users’ shopping experiences. the target or outcome variable is known).
Data preprocessing is a fundamental and essential step in the field of sentiment analysis, a prominent branch of naturallanguageprocessing (NLP). Missing data can lead to inaccurate results and biased analyses. It ensures that the data used in analysis or modeling is comprehensive and comprehensive.
ML focuses on enabling computers to learn from data and improve performance over time without explicit programming. Key Components In Data Science, key components include data cleaning, ExploratoryDataAnalysis, and model building using statistical techniques. This forecast suggests a remarkable CAGR of 36.2%
Dealing with large datasets: With the exponential growth of data in various industries, the ability to handle and extract insights from large datasets has become crucial. Data science equips you with the tools and techniques to manage big data, perform exploratorydataanalysis, and extract meaningful information from complex datasets.
R’s visualization capabilities help in understanding data patterns, identifying outliers, and communicating insights effectively. · Machine Learning: R provides numerous packages for machine learning tasks, making it a popular choice for datascientists. It is a DataScientist’s best friend.
Neural networks are inspired by the structure of the human brain, and they are able to learn complex patterns in data. Deep Learning has been used to achieve state-of-the-art results in a variety of tasks, including image recognition, NaturalLanguageProcessing, and speech recognition.
AWS data engineering pipeline The adaptable approach detailed in this post starts with an automated data engineering pipeline to make data stored in Splunk available to a wide range of personas, including business intelligence (BI) analysts, datascientists, and ML practitioners, through a SQL interface.
NaturalLanguageProcessing (NLP) allows machines to understand and generate human language, enhancing interactions between humans and machines. Focus on exploratoryDataAnalysis and feature engineering. Ideal starting point for aspiring DataScientists.
Machine Learning Operations (MLOps) can significantly accelerate how datascientists and ML engineers meet organizational needs. A well-implemented MLOps process not only expedites the transition from testing to production but also offers ownership, lineage, and historical data about ML artifacts used within the team.
LLMs are one of the most exciting advancements in naturallanguageprocessing (NLP). We will explore how to better understand the data that these models are trained on, and how to evaluate and optimize them for real-world use.
Source:datascientist.com Sentiment analysis, commonly referred to as “opinion mining,” is the method of drawing out irrational information from written or spoken words. The study of how people communicate their thoughts, beliefs, and feelings through language is a fast-expanding area of naturallanguageprocessing (NLP).
Long Short-Term Memory (LSTM) A type of recurrent neural network (RNN) designed to learn long-term dependencies in sequential data. Facebook Prophet A user-friendly tool that automatically detects seasonality and trends in time series data. Making Data Stationary: Many forecasting models assume stationarity.
I came up with an idea of a NaturalLanguageProcessing (NLP) AI program that can generate exam questions and choices about Named Entity Recognition (who, what, where, when, why). I also got a lot more comfortable with working with huge data and therefore master the skills of a datascientist along the way.
Data Science is the art and science of extracting valuable information from data. It encompasses data collection, cleaning, analysis, and interpretation to uncover patterns, trends, and insights that can drive decision-making and innovation. NLP enables machines to understand and interpret text and speech.
His main research interests revolve around applications of Network Analysis and NaturalLanguageProcessing methods. Artem has versatile experience in working with real-life data from different domains and was involved in several data science projects at the World Bank and the University of Oxford.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.































Let's personalize your content