This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Introduction DataScientists have an important role in the modern machine-learning world. Leveraging ML pipelines can save them time, money, and effort and ensure that their models make accurate predictions and insights. Datascientists […] The post Why DataScientists Should Adopt MachineLearning Pipelines?
Overview A machinelearning system consists of multiple building blocks that need to be managed Learn about the three key building blocks of machine. The post 3 Building Blocks of MachineLearning you Should Know as a DataScientist appeared first on Analytics Vidhya.
Introduction The area of machinelearning (ML) is rapidly expanding and has applications across many different sectors. Keeping track of machinelearning experiments using MLflow and managing the trials required to construct them gets harder as they get more complicated.
This article was published as a part of the Data Science Blogathon. Introduction Machinelearning (ML) has become an increasingly important tool for organizations of all sizes, providing the ability to learn and improve from data automatically.
Introduction Meet Tajinder, a seasoned Senior DataScientist and ML Engineer who has excelled in the rapidly evolving field of data science. Tajinder’s passion for unraveling hidden patterns in complex datasets has driven impactful outcomes, transforming raw data into actionable intelligence.
This article was published as a part of the Data Science Blogathon. Introduction MachineLearning pipelines are always about learning and best accuracy achievement. And every DataScientist wants to progress as fast as possible, so time-saving tips & tricks are a big deal as well.
This article was published as a part of the Data Science Blogathon About Streamlit Streamlit is an open-source Python library that assists developers in creating interactive graphical user interfaces for their systems. It was designed especially for MachineLearning and DataScientist team. Frontend […].
As a datascientist, you probably know how to build machinelearning models. But it’s only when you deploy the model that you get a useful machinelearning solution. And if you’re looking to learn more about deploying machinelearning models, this guide is for you.
This article was published as a part of the Data Science Blogathon. Introduction A MachineLearning solution to an unambiguously defined business problem is developed by a DataScientist ot ML Engineer. The post Deploying ML Models Using Kubernetes appeared first on Analytics Vidhya.
Introduction Jupyter Notebook is a web-based interactive computing platform that many datascientists use for data wrangling, data visualization, and prototyping of their MachineLearning models. The post How to Convert Jupyter Notebook into ML Web App? appeared first on Analytics Vidhya.
This article was published as a part of the Data Science Blogathon What is Model Monitoring and why is it required? Machinelearning creates static models from historical data. But, once deployed in production, ML models become unreliable and obsolete and degrade with time.
This article provides insights into how leading datascientists are embracing machinelearning in their organizations and covers some of the major ML challenges and trends in the enterprise.
SQL (Structured Query Language) is an important tool for datascientists. It is a programming language used to manipulate data stored in relational databases. Mastering SQL concepts allows a datascientist to quickly analyze large amounts of data and make decisions based on their findings.
Machinelearning (ML) models can be computationally intensive, and training the models can take longer. Datascientists can iterate faster, experiment […] The post RAPIDS: Use GPU to Accelerate ML Models Easily appeared first on Analytics Vidhya.
Introduction One of the key challenges in MachineLearning Model is the explainability of the ML Model that we are building. In general, ML Model is a Black Box. As Datascientists, we may understand the algorithm & statistical methods used behind the scene. […].
The ML stack is an essential framework for any datascientist or machinelearning engineer. With the ability to streamline processes ranging from data preparation to model deployment and monitoring, it enables teams to efficiently convert raw data into actionable insights. What is an ML stack?
In this use case, available to the public on GitHub, we’ll see how a datascientist, project manager, and business lead at a retail grocer can leverage automated machinelearning and Azure MachineLearning service to reduce product overstock.
For datascientists, this shift has opened up a global market of remote data science jobs, with top employers now prioritizing skills that allow remote professionals to thrive. Here’s everything you need to know to land a remote data science job, from advanced role insights to tips on making yourself an unbeatable candidate.
Machinelearning models are algorithms designed to identify patterns and make predictions or decisions based on data. These models are trained using historical data to recognize underlying patterns and relationships. Once trained, they can be used to make predictions on new, unseen data.
Overview Interpretable machinelearning is a critical concept every datascientist should be aware of How can you build interpretable machinelearning models? The post Decoding the Black Box: An Important Introduction to Interpretable MachineLearning Models in Python appeared first on Analytics Vidhya.
Ready to revolutionize the way you deploy machinelearning? Look no further than ML Ops – the future of ML deployment. MachineLearning (ML) has become an increasingly valuable tool for businesses and organizations to gain insights and make data-driven decisions. What is ML Ops?
Machinelearning (ML) helps organizations to increase revenue, drive business growth, and reduce costs by optimizing core business functions such as supply and demand forecasting, customer churn prediction, credit risk scoring, pricing, predicting late shipments, and many others. Choose Predict.
Feature Platforms — A New Paradigm in MachineLearning Operations (MLOps) Operationalizing MachineLearning is Still Hard OpenAI introduced ChatGPT. The growth of the AI and MachineLearning (ML) industry has continued to grow at a rapid rate over recent years.
With rapid advancements in machinelearning, generative AI, and big data, 2025 is set to be a landmark year for AI discussions, breakthroughs, and collaborations. This conference brings together industry leaders, datascientists, AI engineers, and business professionals to discuss how AI and big data are transforming industries.
Here’s a new title that is a “must have” for any datascientist who uses the R language. It’s a wonderful learning resource for tree-based techniques in statistical learning, one that’s become my go-to text when I find the need to do a deep dive into various ML topic areas for my work.
While traditional opinion polls provide a pretty good snapshot, machinelearning certainly goes deeper with its data-driven perspective on things. One fact is that machinelearning has begun changing data-driven political analysis. With the end goal of predicting the U.S.
Machinelearning engineer vs datascientist: two distinct roles with overlapping expertise, each essential in unlocking the power of data-driven insights. As businesses strive to stay competitive and make data-driven decisions, the roles of machinelearning engineers and datascientists have gained prominence.
With access to a wide range of generative AI foundation models (FM) and the ability to build and train their own machinelearning (ML) models in Amazon SageMaker , users want a seamless and secure way to experiment with and select the models that deliver the most value for their business.
A recent survey of datascientists and engineers revealed that over half (53.3%) of today’s machinelearning (ML) teams are planning on deploying a large language model (LLM) application of their own into production “within the next 12 months” or “as soon as possible”.
This post is part of an ongoing series about governing the machinelearning (ML) lifecycle at scale. This post dives deep into how to set up data governance at scale using Amazon DataZone for the data mesh. To view this series from the beginning, start with Part 1.
This article was published as a part of the Data Science Blogathon. Image 1- [link] Whether you are an experienced or an aspiring datascientist, you must have worked on machinelearning model development comprising of data cleaning, wrangling, comparing different ML models, training the models on Python Notebooks like Jupyter.
Ready to revolutionize the way you deploy machinelearning? Look no further than MLOps – the future of ML deployment. MachineLearning (ML) has become an increasingly valuable tool for businesses and organizations to gain insights and make data-driven decisions. What is MLOps?
When it comes to machinelearning regression models, interviewers typically focus on five key performance metrics, which are the ones mostly used by DataScientists in real time. Introduction Model performance metrics are a crucial component of the MachineLearning lifecycle that comes after model training.
ArticleVideo Book Introduction to Artificial Intelligence and MachineLearning Artificial Intelligence (AI) and its sub-field MachineLearning (ML) have taken the world by storm. The post A Comprehensive Step-by-Step Guide to Become an Industry Ready Data Science Professional appeared first on Analytics Vidhya.
TheSequence recently released the first ever ML Chain Landscape shaped by datascientists, a new landscape that would be able to address the entire ML value chain.
Their ability to uncover feature importance makes them valuable tools for various ML tasks, including classification, regression, and ranking problems. As a result, boosting algorithms have become a staple in the machinelearning toolkit. Boosting algorithms work with these components to enhance ML functionality and accuracy.
Drag and drop tools have revolutionized the way we approach machinelearning (ML) workflows. Gone are the days of manually coding every step of the process – now, with drag-and-drop interfaces, streamlining your ML pipeline has become more accessible and efficient than ever before. How do drag and drop tools work?
This blog post uses the Concrete-ML library, allowing datascientists to use machinelearning models in fully homomorphic encryption (FHE) settings without any prior knowledge of cryptography. We provide a practical tutorial on how to use the library to build a sentiment analysis model on encrypted data.
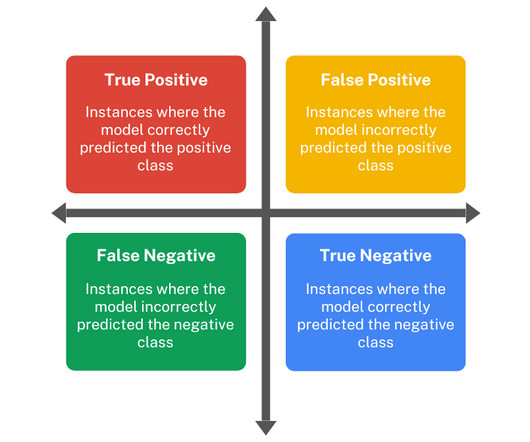
In the world of machinelearning, evaluating the performance of a model is just as important as building the model itself. Understand the basics of Binomial Distribution and its importance in ML Interpreting the Key Metrics High Recall : The model is good at identifying actual Spam emails (high Recall of 87.5%).
Amazon SageMaker supports geospatial machinelearning (ML) capabilities, allowing datascientists and ML engineers to build, train, and deploy ML models using geospatial data. These geospatial capabilities open up a new world of possibilities for environmental monitoring.
If you’ve found yourself asking, “How to become a datascientist?” In this detailed guide, we’re going to navigate the exciting realm of data science, a field that blends statistics, technology, and strategic thinking into a powerhouse of innovation and insights. What is a datascientist?
The new SDK is designed with a tiered user experience in mind, where the new lower-level SDK ( SageMaker Core ) provides access to full breadth of SageMaker features and configurations, allowing for greater flexibility and control for ML engineers. In the following example, we show how to fine-tune the latest Meta Llama 3.1
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content