This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Machinelearning practices are the guiding principles that transform raw data into powerful insights. By following best practices in algorithm selection, data preprocessing, model evaluation, and deployment, we unlock the true potential of machinelearning and pave the way for innovation and success.
SupportVectorMachines (SVM) are a cornerstone of machinelearning, providing powerful techniques for classifying and predicting outcomes in complex datasets. What are SupportVectorMachines (SVM)? They work by identifying a hyperplane that best separates distinct classes within the data.
One of the main reasons for its popularity is the vast array of libraries and packages available for data manipulation, analysis, and visualization. It supports large, multi-dimensional arrays and matrices of numerical data, as well as a large library of mathematical functions to operate on these arrays.
By employing various methodologies, analysts uncover hidden patterns, predict outcomes, and supportdata-driven decision-making. Understanding these techniques can enhance a datascientist’s toolkit, making it easier to navigate the complexities of big data. What are data science techniques?
One of the main reasons for its popularity is the vast array of libraries and packages available for data manipulation, analysis, and visualization. It supports large, multi-dimensional arrays and matrices of numerical data, as well as a large library of mathematical functions to operate on these arrays.
Statistics: Unveiling the patterns within data Statistics serves as the bedrock of data science, providing the tools and techniques to collect, analyze, and interpret data. It equips datascientists with the means to uncover patterns, trends, and relationships hidden within complex datasets.
The concept of a kernel in machinelearning might initially sound perplexing, but it’s a fundamental idea that underlies many powerful algorithms. There are mathematical theorems that support the working principle of all automation systems that make up a large part of our daily lives. Which type should you prefer?
Machinelearning is playing a very important role in improving the functionality of task management applications. In January, Towards Data Science published an article on this very topic. Project managers should be aware of the changes that machinelearning has brought to task management applications.
Machinelearning (ML) technologies can drive decision-making in virtually all industries, from healthcare to human resources to finance and in myriad use cases, like computer vision , large language models (LLMs), speech recognition, self-driving cars and more. What is machinelearning?
Learn how to apply state-of-the-art clustering algorithms efficiently and boost your machine-learning skills.Image source: unsplash.com. In this introduction guide, I will formally introduce you to clustering in MachineLearning. Author(s): Riccardo Andreoni Originally published on Towards AI.
Photo by Robo Wunderkind on Unsplash In general , a datascientist should have a basic understanding of the following concepts related to kernels in machinelearning: 1. SupportVectorMachineSupportVectorMachine ( SVM ) is a supervised learning algorithm used for classification and regression analysis.
While data science and machinelearning are related, they are very different fields. In a nutshell, data science brings structure to big data while machinelearning focuses on learning from the data itself. What is data science? What is machinelearning?
Data is a crucial element of modern-day businesses. With the growing use of machinelearning (ML) models to handle, store, and manage data, the efficiency and impact of enterprises have also increased. Categorical data is one such form of information that is handled by ML models using different methods.
In the rapidly evolving world of technology, machinelearning has become an essential skill for aspiring datascientists, software engineers, and tech professionals. Coursera MachineLearning Courses are an exceptional array of courses that can transform your career and technical expertise.
Anomalies are not inherently bad, but being aware of them, and having data to put them in context, is integral to understanding and protecting your business. The challenge for IT departments working in data science is making sense of expanding and ever-changing data points.
The thought of machinelearning and AI will definitely pop into your mind when the conversation is about emerging technologies. Today, we see tools and systems with machine-learning capabilities in almost every industry. Finance institutions are using machinelearning to overcome healthcare fraud challenges.
Summary: Linear Algebra is foundational to MachineLearning, providing essential operations such as vector and matrix manipulations. Introduction Linear Algebra is a fundamental mathematical discipline that underpins many algorithms and techniques in MachineLearning.
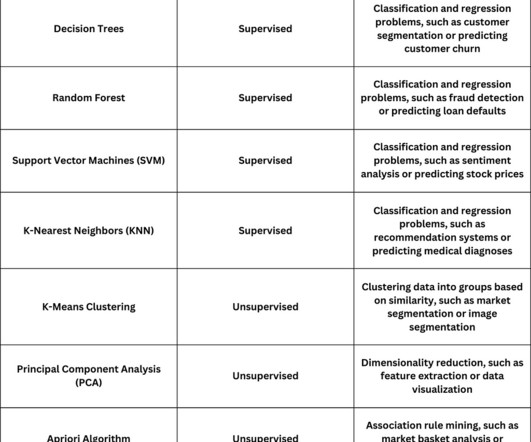
Summary: This blog highlights ten crucial MachineLearning algorithms to know in 2024, including linear regression, decision trees, and reinforcement learning. Introduction MachineLearning (ML) has rapidly evolved over the past few years, becoming an integral part of various industries, from healthcare to finance.
Photo by Andy Kelly on Unsplash Choosing a machinelearning (ML) or deep learning (DL) algorithm for application is one of the major issues for artificial intelligence (AI) engineers and also datascientists. Submission Suggestions How do I choose a machinelearning algorithm for my application?
Summary: The blog provides a comprehensive overview of MachineLearning Models, emphasising their significance in modern technology. It covers types of MachineLearning, key concepts, and essential steps for building effective models. The global MachineLearning market was valued at USD 35.80
Summary: The blog discusses essential skills for MachineLearning Engineer, emphasising the importance of programming, mathematics, and algorithm knowledge. Understanding MachineLearning algorithms and effective data handling are also critical for success in the field. billion by 2031, growing at a CAGR of 34.20%.
Summary: Inductive bias in MachineLearning refers to the assumptions guiding models in generalising from limited data. By managing inductive bias effectively, datascientists can improve predictions, ensuring models are robust and well-suited for real-world applications.
Summary : Feature selection in MachineLearning identifies and prioritises relevant features to improve model accuracy, reduce overfitting, and enhance computational efficiency. Introduction Feature selection in MachineLearning is identifying and selecting the most relevant features from a dataset to build efficient predictive models.
Summary: MachineLearning significantly impacts businesses by enhancing decision-making, automating processes, and improving customer experiences. This technology transforms industries, driving innovation and efficiency while presenting challenges like data privacy and integration. What is MachineLearning?
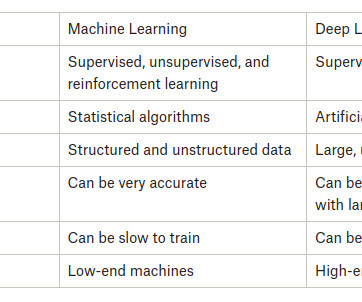
A key component of artificial intelligence is training algorithms to make predictions or judgments based on data. This process is known as machinelearning or deep learning. Two of the most well-known subfields of AI are machinelearning and deep learning. What is MachineLearning?
The concepts of bias and variance in MachineLearning are two crucial aspects in the realm of statistical modelling and machinelearning. Understanding these concepts is paramount for any datascientist, machinelearning engineer, or researcher striving to build robust and accurate models.
Comparison with Other Classification Techniques Associative classification differs from traditional classification methods like decision trees and supportvectormachines (SVM). Understanding these differences can help determine when to use each technique based on the nature of the data and the problem at hand.
Heres what we noticed from analyzing this data, highlighting whats remained the same over the years, and what additions help make the modern datascientist in2025. Data Science Of course, a datascientist should know data science! Joking aside, this does infer particular skills.
Mastering Tree-Based Models in MachineLearning: A Practical Guide to Decision Trees, Random Forests, and GBMs Image created by the author on Canva Ever wondered how machines make complex decisions? Just like a tree branches out, tree-based models in machinelearning do something similar. Let’s get started!
Deep learning for feature extraction, ensemble models, and more Photo by DeepMind on Unsplash The advent of deep learning has been a game-changer in machinelearning, paving the way for the creation of complex models capable of feats previously thought impossible.
Text Categorization Text categorization is a machine-learning approach that divides the text into specific categories based on its content. R has a rich set of libraries and tools for machinelearning and natural language processing, making it well-suited for spam detection tasks.
Natural Language Processing Getting desirable data out of published reports and clinical trials and into systematic literature reviews (SLRs) — a process known as data extraction — is just one of a series of incredibly time-consuming, repetitive, and potentially error-prone steps involved in creating SLRs and meta-analyses.
Summary: In the tech landscape of 2024, the distinctions between Data Science and MachineLearning are pivotal. Data Science extracts insights, while MachineLearning focuses on self-learning algorithms. AI refers to developing machines capable of performing tasks that require human intelligence.
Revolutionizing Healthcare through Data Science and MachineLearning Image by Cai Fang on Unsplash Introduction In the digital transformation era, healthcare is experiencing a paradigm shift driven by integrating data science, machinelearning, and information technology.
In this first post, we introduce mobility data, its sources, and a typical schema of this data. We then discuss the various use cases and explore how you can use AWS services to clean the data, how machinelearning (ML) can aid in this effort, and how you can make ethical use of the data in generating visuals and insights.
Hands-on Project Why customer churn matters and how to predict it with machinelearning, explained step-by-step Photo by Gabrielle Ribeiro on Unsplash Introduction In today’s competitive business environment, retaining customers is essential to a company’s success. Follow “Nhi Yen” for future updates! Our project uses Comet ML to: 1.
Empowering DataScientists and MachineLearning Engineers in Advancing Biological Research Image from European Bioinformatics Institute Introduction: In biological research, the fusion of biology, computer science, and statistics has given birth to an exciting field called bioinformatics.
Accordingly, there are many Python libraries which are open-source including Data Manipulation, Data Visualisation, MachineLearning, Natural Language Processing , Statistics and Mathematics. Learn probability, testing for hypotheses, regression, classification, and grouping, among other topics.
MachineLearning is a subset of Artificial Intelligence and Computer Science that makes use of data and algorithms to imitate human learning and improving accuracy. Being an important component of Data Science, the use of statistical methods are crucial in training algorithms in order to make classification.
Source: [link] Similarly, while building any machinelearning-based product or service, training and evaluating the model on a few real-world samples does not necessarily mean the end of your responsibilities. MLOps tools play a pivotal role in every stage of the machinelearning lifecycle. What is MLOps?
Data Science interviews are pivotal moments in the career trajectory of any aspiring datascientist. Having the knowledge about the data science interview questions will help you crack the interview. Data Science skills that will help you excel professionally. Explain the bias-variance tradeoff in MachineLearning.
It’s an essential task in natural language processing (NLP) and machinelearning, with applications ranging from sentiment analysis to spam detection. Machinelearning models like ANNs need to be trained on labeled data to perform text classification. This is where Comet comes in. What is Comet?
Text Vectorization Techniques Text vectorization is a crucial step in text mining, where text data is transformed into numerical representations that can be processed by MachineLearning algorithms. Sentiment analysis techniques range from rule-based approaches to more advanced machinelearning algorithms.
However, symbolic AI faced limitations in handling uncertainty and dealing with large-scale data. MachineLearning and Neural Networks (1990s-2000s): MachineLearning (ML) became a focal point, enabling systems to learn from data and improve performance without explicit programming.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content