This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Also: Decision Tree Algorithm, Explained; 15 Python Coding Interview Questions You Must Know For Data Science; Naïve Bayes Algorithm: Everything You Need to Know; Primary SupervisedLearning Algorithms Used in Machine Learning.
14 Essential Git Commands for DataScientists • Statistics and Probability for Data Science • 20 Basic Linux Commands for Data Science Beginners • 3 Ways Understanding Bayes Theorem Will Improve Your Data Science • Learn MLOps with This Free Course • Primary SupervisedLearning Algorithms Used in Machine Learning • Data Preparation with SQL Cheatsheet. (..)
Inspired by its reinforcement learning (RL)-based optimization, I wondered: can we apply a similar RL-driven strategy to supervisedlearning? Instead of manually selecting a model, why not let reinforcement learninglearn the best strategy for us?
We have seen how Machine learning has revolutionized industries across the globe during the past decade, and Python has emerged as the language of choice for aspiring datascientists and seasoned professionals alike. Scikit-learn is an open-source machine learning library built on Python.
Increasingly, FMs are completing tasks that were previously solved by supervisedlearning, which is a subset of machine learning (ML) that involves training algorithms using a labeled dataset. Francisco Calderon is a DataScientist at the Generative AI Innovation Center (GAIIC).
At the core of machine learning, two primary learning techniques drive these innovations. These are known as supervisedlearning and unsupervised learning. Supervisedlearning and unsupervised learning differ in how they process data and extract insights.
XGBoost has gained a formidable reputation in the realm of machine learning, becoming a go-to choice for practitioners and datascientists alike. Foundational concepts of XGBoost Understanding the principles behind XGBoost involves delving into several fundamental aspects of machine learning.
Some of the applications of data science are driverless cars, gaming AI, movie recommendations, and shopping recommendations. Since the field covers such a vast array of services, datascientists can find a ton of great opportunities in their field. Datascientists use algorithms for creating data models.
Their ability to handle high-dimensional spaces and to create precise models in varied environments captures the interest of many datascientists and analysts. Support Vector Machines (SVM) are a type of supervisedlearning algorithm designed for classification and regression tasks. What are Support Vector Machines (SVM)?
To harness this data effectively, researchers and programmers frequently employ machine learning to enhance user experiences. Emerging daily are sophisticated methodologies for datascientists encompassing supervised, unsupervised, and reinforcement learning techniques. What is supervisedlearning?
Although there are many types of learning, Michalski defined the two most common types of learning: SupervisedLearning. Unsupervised Learning. Both of these types of learning are used by machine learning algorithms in modern task management applications. SupervisedLearning.
According to Gartner, a renowned research firm, by 2022, an astounding 70% of customer interactions are expected to flow through technologies like machine learning applications, chatbots, and mobile messaging. This process involves rectifying or discarding abnormal or non-standard data points and ensuring the accuracy of measurements.
Machine learning types Machine learning algorithms fall into five broad categories: supervisedlearning, unsupervised learning, semi-supervisedlearning, self-supervised and reinforcement learning. the target or outcome variable is known). temperature, salary).
Business implications The implications for businesses are significant: machine teaching not only democratizes access to AI but also enables companies to harness the power of machine learning without solely relying on datascientists.
Improvements using foundation models Despite yielding promising results, PORPOISE and HEEC algorithms use backbone architectures trained using supervisedlearning (for example, ImageNet pre-trained ResNet50). About the Authors Cemre Zor, PhD, is a senior healthcare datascientist at Amazon Web Services.
In this blog we’ll go over how machine learning techniques, powered by artificial intelligence, are leveraged to detect anomalous behavior through three different anomaly detection methods: supervised anomaly detection, unsupervised anomaly detection and semi-supervised anomaly detection.
The three main phases are: self-supervisedlearningsupervisedlearning reinforcement learning. I recently gave a talk at Snorkel AI’s second Enterprise LLM Summit about the problems that can surface when the data for these three labels is not properly aligned. I’ve summarized the main points below.
Lastly, the sigmoid kernel transforms data to enable linear separation when it wasn’t feasible before. By understanding these kernels, datascientists can choose the right tool to unlock patterns hidden within data, enhancing the accuracy and performance of their models.
As a senior datascientist, I often encounter aspiring datascientists eager to learn about machine learning (ML). In this comprehensive guide, I will demystify machine learning, breaking it down into digestible concepts for beginners. Common supervisedlearning tasks include classification (e.g.,
Photo by Robo Wunderkind on Unsplash In general , a datascientist should have a basic understanding of the following concepts related to kernels in machine learning: 1. Support Vector Machine Support Vector Machine ( SVM ) is a supervisedlearning algorithm used for classification and regression analysis.
However, a new paradigm has entered the chat, as LLMs don’t follow the same rules and expectations of traditional machine learning models. As such, datascientists need to find a different approach for using MLOps to find structure and create a sense of order as LLMs are developed.
Be sure to check out his session, “ Improving ML Datasets with Cleanlab, a Standard Framework for Data-Centric AI ,” there! Anybody who has worked on a real-world ML project knows how messy data can be. Our goal is to enable all developers to find and fix data issues as effectively as today’s best datascientists.
The three main phases are: self-supervisedlearningsupervisedlearning reinforcement learning. I recently gave a talk at Snorkel AI’s second Enterprise LLM Summit about the problems that can surface when the data for these three labels is not properly aligned. I’ve summarized the main points below.
Its robust ecosystem of libraries and frameworks tailored for Data Science, such as NumPy, Pandas, and Scikit-learn, contributes significantly to its popularity. Moreover, Python’s straightforward syntax allows DataScientists to focus on problem-solving rather than grappling with complex code.
This is where Azure Machine Learning shines by democratizing access to advanced AI capabilities. Azure Machine Learning is Microsoft’s enterprise-grade service that provides a comprehensive environment for datascientists and ML engineers to build, train, deploy, and manage machine learning models at scale.
Focus LLMOps is specifically focused on the operational management of LLMs, while MLOps is focused on all machine learning models. This means that datascientists need to be specifically aware of the nuances of language models and text-based datasets, such as factoring in linguistics, context, domains, and the potential computational cost.
This technology allows computers to learn from historical data, identify patterns, and make data-driven decisions without explicit programming. Unsupervised learning algorithms Unsupervised learning algorithms are a vital part of Machine Learning, used to uncover patterns and insights from unlabeled data.
We’ve often seen solutions developed by datascientists but without the infrastructure or organizational support to take their solution to production. Are your datascientists working in siloed environments (worst case: their laptops) and not versioning their code and results in a central location?
The Snorkel papers cover a broad range of topics including fairness, semi-supervisedlearning, large language models (LLMs), and domain-specific models. Snorkel AI is proud of its roots in the research community and endeavors to remain at the forefront of new scholarship in data-centric AI, programmatic labeling, and foundation models.
Understanding what each dataset offersand how it can be usedcan help datascientists choose the right resources for their projects. Hereshow: Data Preprocessing & Cleaning: Handle missing values, normalize financial data, and ensure consistency. However, not all datasets are created equal.
Summary: Data Science appears challenging due to its complexity, encompassing statistics, programming, and domain knowledge. However, aspiring datascientists can overcome obstacles through continuous learning, hands-on practice, and mentorship. However, many aspiring professionals wonder: Is Data Science hard?
Machine Learning Best Practices for Downloaded Videos Once you’ve downloaded your videos using Y2Mate, here are some ML-specific tips: Data Preprocessing : Convert videos to frame sequences for computer vision tasks Augmentation : Generate additional training samples through rotation, cropping, etc.
Given the availability of diverse data sources at this juncture, employing the CNN-QR algorithm facilitated the integration of various features, operating within a supervisedlearning framework. Utilizing Forecast proved effective due to the simplicity of providing the requisite data and specifying the forecast duration.
Ramcharan12345 is looking to collaborate with AI devs who can leverage spaCy for NLP, utilize scikit-learn for supervisedlearning on historical data for symptom mapping, and implement TensorFlow/Keras for neural network-based risk prediction. Keep an eye on this section, too — we share cool opportunities every week!
From gathering and processing data to building models through experiments, deploying the best ones, and managing them at scale for continuous value in production—it’s a lot. As the number of ML-powered apps and services grows, it gets overwhelming for datascientists and ML engineers to build and deploy models at scale.
You’ll likely work in cross-functional teams alongside datascientists, engineers, computational programmers, writers, and other domain experts. Collaboration and Communication Finally, having effective communication and collaboration skills are key to succeeding as a prompt engineer.
However, there are certain algorithms that have stood the test of time and remain crucial for any datascientist or Machine Learning practitioner to understand. This section will explore the top 10 Machine Learning algorithms that you should know in 2024.
The Snorkel papers cover a broad range of topics including fairness, semi-supervisedlearning, large language models (LLMs), and domain-specific models. Snorkel AI is proud of its roots in the research community and endeavors to remain at the forefront of new scholarship in data-centric AI, programmatic labeling, and foundation models.
LLM distillation is when datascientists use LLMs to train smaller models. Datascientists can use distillation to jumpstart classification models or to align small-format generative AI (GenAI) models to produce better responses. Datascientists can also use distillation to fine-tune smaller generative models.
LLM distillation is when datascientists use LLMs to train smaller models. Datascientists can use distillation to jumpstart classification models or to align small-format generative AI (GenAI) models to produce better responses. Datascientists can also use distillation to fine-tune smaller generative models.
Enhancing CLIP with CLIP In the standard approach, datascientists improve foundation models by fine-tuning them, but this is expensive and often requires large amounts of labeled data. The learning stage uses techniques like semi-supervisedlearning that use few or no labels. Let’s dive in.
They work closely with a multidisciplinary team that includes other engineers, datascientists, and product managers. Collaboration is the lifeblood of progress in the field of LLMs, and prompt engineers are at the heart of this collaborative ecosystem.
Foundation models can be trained to perform tasks such as data classification, the identification of objects within images (computer vision) and natural language processing (NLP) (understanding and generating text) with a high degree of accuracy.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.





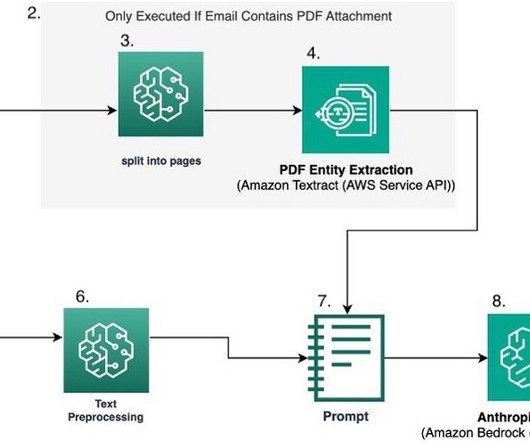























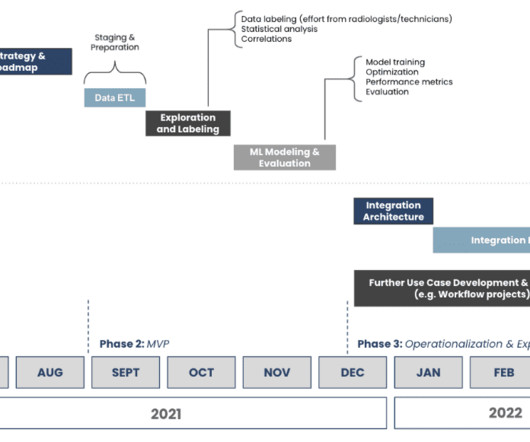




















Let's personalize your content