This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In today’s world, datawarehouses are a critical component of any organization’s technology ecosystem. They provide the backbone for a range of use cases such as business intelligence (BI) reporting, dashboarding, and machine-learning (ML)-based predictive analytics, that enable faster decision making and insights.
By analyzing their data, organizations can identify patterns in sales cycles, optimize inventory management, or help tailor products or services to meet customer needs more effectively. When needed, the system can access an ODAP datawarehouse to retrieve additional information.
From data processing to quick insights, robust pipelines are a must for any ML system. Often the Data Team, comprising Data and ML Engineers , needs to build this infrastructure, and this experience can be painful. However, efficient use of ETL pipelines in ML can help make their life much easier.
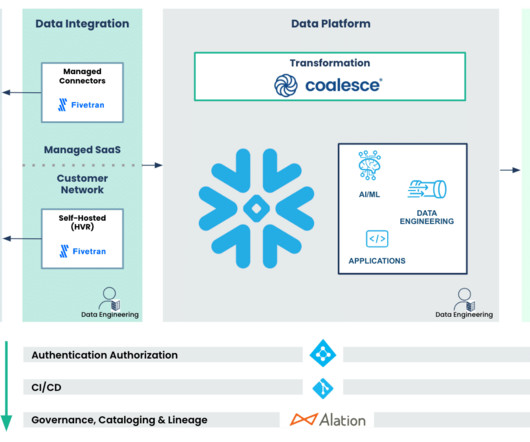
Integrating different systems, data sources, and technologies within an ecosystem can be difficult and time-consuming, leading to inefficiencies, datasilos, broken machine learning models, and locked ROI. Exploratory Data Analysis After we connect to Snowflake, we can start our ML experiment.
You can quickly launch the familiar RStudio IDE and dial up and down the underlying compute resources without interrupting your work, making it easy to build machine learning (ML) and analytics solutions in R at scale. Data analysis and modeling can be challenging when working with large datasets in the cloud. Conclusion.
This is due to a fragmented ecosystem of datasilos, a lack of real-time fraud detection capabilities, and manual or delayed customer analytics, which results in many false positives. Snowflake Marketplace offers data from leading industry providers such as Axiom, S&P Global, and FactSet.
They defined it as : “ A data lakehouse is a new, open data management architecture that combines the flexibility, cost-efficiency, and scale of data lakes with the data management and ACID transactions of datawarehouses, enabling business intelligence (BI) and machine learning (ML) on all data. ”.
Key Takeaways Data Fabric is a modern data architecture that facilitates seamless data access, sharing, and management across an organization. Data management recommendations and data products emerge dynamically from the fabric through automation, activation, and AI/ML analysis of metadata.
With the advent of cloud datawarehouses and the ability to (seemingly) infinitely scale analytics on an organization’s data, centralizing and using that data to discover what drives customer engagement has become a top priority for executives across all industries and verticals.
Businesses face significant hurdles when preparing data for artificial intelligence (AI) applications. The existence of datasilos and duplication, alongside apprehensions regarding data quality, presents a multifaceted environment for organizations to manage.
Data has to be stored somewhere. Datawarehouses are repositories for your cleaned, processed data, but what about all that unstructured data your organization is starting to notice? What is a data lake? Snowflake Snowflake is a cross-cloud platform that looks to break down datasilos.
Like most Gen AI use cases, the first step to achieving customer service automation is to clean and centralize all information in a datawarehouse for your AI to work from. However, this can be particularly challenging in manufacturing, where data comes in from sensors on production lines, suppliers, customers, and partners.
Open is creating a foundation for storing, managing, integrating and accessing data built on open and interoperable capabilities that span hybrid cloud deployments, data storage, data formats, query engines, governance and metadata.
Difficulty in moving non-SAP data into SAP for analytics which encourages datasilos and shadow IT practices as business users search for ways to extract the data (which has data governance implications).
Data modernization is the process of transferring data to modern cloud-based databases from outdated or siloed legacy databases, including structured and unstructured data. In that sense, data modernization is synonymous with cloud migration. So what’s the appeal of this new infrastructure?
Data engineering in healthcare is taking a giant leap forward with rapid industrial development. Artificial Intelligence (AI) and Machine Learning (ML) are buzzwords these days with developments of Chat-GPT, Bard, and Bing AI, among others. However, data collection and analysis have been commonplace in the healthcare sector for ages.
The proliferation of data sources means there is an increase in data volume that must be analyzed. Large volumes of data have led to the development of data lakes , datawarehouses, and data management systems. Despite its immense value, a variety of data can create more work.
Here’s how a composable CDP might incorporate the modeling approaches we’ve discussed: Data Storage and Processing : This is your foundation. You might choose a cloud datawarehouse like the Snowflake AI Data Cloud or BigQuery. It’s like turning your datawarehouse into a data distribution center.
Instead, a core component of decentralized clinical trials is a secure, scalable data infrastructure with strong data analytics capabilities. Amazon Redshift is a fully managed cloud datawarehouse that trial scientists can use to perform analytics. With SageMaker, you can optimize your ML environment for sustainability.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
























Let's personalize your content