This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Summary: Datasilos are isolated data repositories within organisations that hinder access and collaboration. Eliminating datasilos enhances decision-making, improves operational efficiency, and fosters a collaborative environment, ultimately leading to better customer experiences and business outcomes.
By Stuart Grant, Global GTM for Capital Markets, SAP According to a recent McKinsey study, datasilos cost businesses an average of $3.1 Failing to leverage data properly is an eye wateringly expensive trillion annually in lost revenue and productivity. Thats a huge number. How much of it is yours?
For years, enterprise companies have been plagued by datasilos separating transactional systems from analytical tools—a divide that has hampered AI applications, slowed real-time decision-making, and driven up costs with complex integrations. Today at its Ignite conference, Microsoft announced a …
For people striving to rule the data integration and data management world, it should not be a surprise that companies are facing difficulty in accessing and integrating data across system or application datasilos. The role of Artificial Intelligence and MachineLearning comes into play here.
True data quality simplification requires transformation of both code and data, because the two are inextricably linked. Code sprawl and datasiloing both imply bad habits that should be the exception, rather than the norm.
Unified data storage : Fabric’s centralized data lake, Microsoft OneLake, eliminates datasilos and provides a unified storage system, simplifying data access and retrieval. This open format allows for seamless storage and retrieval of data across different databases.
Summary: Data quality is a fundamental aspect of MachineLearning. Poor-quality data leads to biased and unreliable models, while high-quality data enables accurate predictions and insights. What is Data Quality in MachineLearning? What is Data Quality in MachineLearning?
AIOps, or artificial intelligence for IT operations, combines AI technologies like machinelearning, natural language processing, and predictive analytics, with traditional IT operations. Tool overload can lead to inefficiencies and datasilos. Understanding AI Operations (AIOps) in IT Environments What is AIOps?
This post is part of an ongoing series about governing the machinelearning (ML) lifecycle at scale. This post dives deep into how to set up data governance at scale using Amazon DataZone for the data mesh. To view this series from the beginning, start with Part 1.
It also allows for decision-making by connecting existing datasilos within organizations. The technologies that support systems to meet the above requirements are the Industrial Internet of Things , MachineLearning, and the public cloud.
It also allows for decision-making by connecting existing datasilos within organizations. The technologies that support systems to meet the above requirements are the Industrial Internet of Things, MachineLearning, and the public cloud.
With machinelearning (ML) and artificial intelligence (AI) applications becoming more business-critical, organizations are in the race to advance their AI/ML capabilities. To realize the full potential of AI/ML, having the right underlying machinelearning platform is a prerequisite.
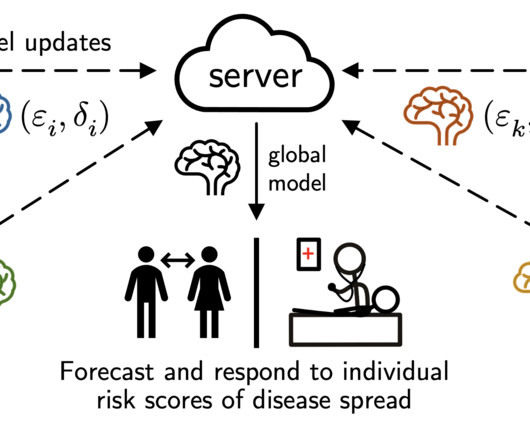
Introduction MachineLearning has evolved significantly, from basic algorithms to advanced models that drive today’s AI innovations. A key advancement is Federated Learning, which enhances privacy and efficiency by training models across decentralised devices. What is Federated Learning?
Be sure to check out her talk, “ Power trusted AI/ML Outcomes with Data Integrity ,” there! Due to the tsunami of data available to organizations today, artificial intelligence (AI) and machinelearning (ML) are increasingly important to businesses seeking competitive advantage through digital transformation.
Privacy-enhancing technologies (PETs) have the potential to unlock more trustworthy innovation in data analysis and machinelearning. Federated learning is one such technology that enables organizations to analyze sensitive data while providing improved privacy protections. What motivated you to participate?
You can quickly launch the familiar RStudio IDE and dial up and down the underlying compute resources without interrupting your work, making it easy to build machinelearning (ML) and analytics solutions in R at scale. Now let’s prepare a dataset that could be used for machinelearning. arrange(card_brand).
Many organizations are implementing machinelearning (ML) to enhance their business decision-making through automation and the use of large distributed datasets. With increased access to data, ML has the potential to provide unparalleled business insights and opportunities. In such scenarios, you can use FedML Octopus.
Almost half of AI projects are doomed by poor data quality, inaccurate or incomplete data categorization, unstructured data, and datasilos. Avoid these 5 mistakes
Analyzing real-world healthcare and life sciences (HCLS) data poses several practical challenges, such as distributed datasilos, lack of sufficient data at any single site for rare events, regulatory guidelines that prohibit data sharing, infrastructure requirement, and cost incurred in creating a centralized data repository.
When integrated with AI, mainframe data has the potential to serve as a key asset in addressing one of the most persistent challenges in AIbias. Understanding Bias in AI Bias in AI arises when the data used to train machinelearning models reflects historical inequalities, stereotypes, or inaccuracies.
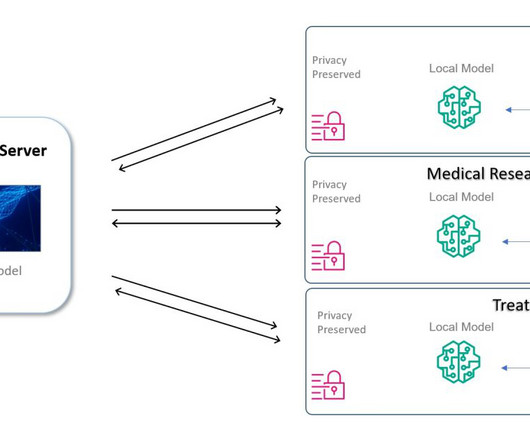
Medical data restrictions You can use machinelearning (ML) to assist doctors and researchers in diagnosis tasks, thereby speeding up the process. However, the datasets needed to build the ML models and give reliable results are sitting in silos across different healthcare systems and organizations.
Multicloud architecture not only empowers businesses to choose a mix of the best cloud products and services to match their business needs, but it also accelerates innovation by supporting game-changing technologies like generative AI and machinelearning (ML).
Organizations gain the ability to effortlessly modify and scale their data in response to shifting business demands, leading to greater agility and adaptability. A data virtualization platform breaks down datasilos by using data virtualization.
The promise of significant and measurable business value can only be achieved if organizations implement an information foundation that supports the rapid growth, speed and variety of data. This integration is even more important, but much more complex with Big Data. Big Data is Transforming the Financial Industry.
Strong integration capabilities ensure smooth data flow between departments, eliminating datasilos. Choose a solution that includes AI-driven insights as a core feature, enabling your business to leverage machinelearning for more accurate forecasts and strategic planning. Flexibility is key.
Technology helped to bridge the gap, as AI, machinelearning, and data analytics drove smarter decisions, and automation paved the way for greater efficiency. AI and machinelearning initiatives play an increasingly important role.
Unfortunately, while this data contains a wealth of useful information for disease forecasting, the data itself may be highly sensitive and stored in disparate locations (e.g., In this post we discuss our research on federated learning , which aims to tackle this challenge by performing decentralized learning across private datasilos.
Analyzing real-world healthcare and life sciences (HCLS) data poses several practical challenges, such as distributed datasilos, lack of sufficient data at a single site for rare events, regulatory guidelines that prohibit data sharing, infrastructure requirement, and cost incurred in creating a centralized data repository.
Integrating different systems, data sources, and technologies within an ecosystem can be difficult and time-consuming, leading to inefficiencies, datasilos, broken machinelearning models, and locked ROI.
Datasilos Limited integration capabilities Fragmented communications Workflow problems Limited scalability The fact is, your legacy systems can create great risks for your business. A unified CXP can also provide real-time data insights, helping you understand customer preferences and behavior.
This is due to a fragmented ecosystem of datasilos, a lack of real-time fraud detection capabilities, and manual or delayed customer analytics, which results in many false positives. Snowflake Marketplace offers data from leading industry providers such as Axiom, S&P Global, and FactSet.
This article was published as a part of the Data Science Blogathon. Introduction A data lake is a central data repository that allows us to store all of our structured and unstructured data on a large scale.
The platform provides an intelligent, self-service data ecosystem that enhances data governance, quality and usability. By migrating to watsonx.data on AWS, companies can break down datasilos and enable real-time analytics, which is crucial for timely decision-making.
Since the advent of deep learning in the 2000s, AI applications in healthcare have expanded. MachineLearningMachinelearning (ML) focuses on training computer algorithms to learn from data and improve their performance, without being explicitly programmed.
Supporting the data management life cycle According to IDC’s Global StorageSphere, enterprise data stored in data centers will grow at a compound annual growth rate of 30% between 2021-2026. [2] ” Notably, watsonx.data runs both on-premises and across multicloud environments.
Predict NFT floor prices using machinelearning to win prizes! We’re announcing our NFT Price Analysis data challenge due this April 30th, 2023 at 11:59 PM UTC! Contestants are asked to submit data analytics reports and machinelearning models to analyze the floor prices of NFTs.
Innovators in the industry understand that leading-edge technologies such as AI and machinelearning will be a deciding factor in the quest for competitive advantage when moving to the cloud. To learn more, read our ebook. To learn more, read our ebook 5 Tips to Modernize Data Integration for the Cloud.
Here are some of the key trends and challenges facing telecommunications companies today: The growth of AI and machinelearning: Telecom companies use artificial intelligence and machinelearning (AI/ML) for predictive analytics and network troubleshooting.
However, achieving success in AI projects isn’t just about deploying advanced algorithms or machinelearning models. The real challenge lies in ensuring that the data powering your projects is AI-ready. Above all, you must remember that trusted AI starts with trusted data. The stakes are very high.
Without a doubt, no company can achieve lasting profitability and sustainable growth with a poorly constructed data governance methodology. Today, all companies must pursue data analytics, MachineLearning & Artificial Intelligence (ML & AI) as an integral part of any standard business plan.
But that’s exactly why Ocean Protocol hosts regular Predict-ETH competitions — to help you sharpen your machinelearning skills, learn from others, and potentially make some cash along the way. About Ocean Protocol Ocean Protocol is an ecosystem of open source data sharing tools for the blockchain.
She started as a Web Analyst and Online Marketing Manager, and discovered her passion for data, Big Data, data science and machinelearning. Source: One Data Laura says: “Treating data as a product creates value for businesses by shifting the focus from data being a cost center to data being a revenue generator.
They shore up privacy and security, embrace distributed workforce management, and innovate around artificial intelligence and machinelearning-based automation. The key to success within all of these initiatives is high-integrity data. Do the takeaways we’ve covered resonate with your own data integrity needs and challenges?
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content