This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Data Analyst Data analysts are responsible for collecting, analyzing, and interpreting large sets of data to identify patterns and trends. They require strong analytical skills, knowledge of statistical analysis, and expertise in datavisualization.
The goal of data cleaning, the data cleaning process, selecting the best programming language and libraries, and the overall methodology and findings will all be covered in this post. Datawrangling requires that you first clean the data. In this example, we'll load a CSV file using the read_csv() method.
It’s a foundational skill for working with relational databases Just about every data scientist or analyst will have to work with relational databases in their careers. So by learning to use SQL, you’ll write efficient and effective queries, as well as understand how the data is structured and stored.
And you should have experience working with big data platforms such as Hadoop or Apache Spark. Additionally, data science requires experience in SQL database coding and an ability to work with unstructured data of various types, such as video, audio, pictures and text.
As you’ll see below, however, a growing number of data analytics platforms, skills, and frameworks have altered the traditional view of what a data analyst is. Data Presentation: Communication Skills, DataVisualization Any good data analyst can go beyond just number crunching.
Introduction to Pandas – The fundamentals Pandas is a popular and powerful open-source data analysis and manipulation library for the Python programming language. It is used by us, almighty data scientists and analysts to work with large datasets, perform complex operations, and create powerful datavisualizations.
Improving your data literacy not only involves hard skills, such as programming languages, but soft skills such as interpersonal communication, and stakeholder relations, as well as blended skills such as datavisualization. SQL Databases might sound scary, but honestly, they’re not all that bad. Learning is learning.
Humans and machines Data scientists and analysts need to be aware of how this technology will affect their role, their processes, and their relationships with other stakeholders. There are clearly aspects of datawrangling that AI is going to be good at. Chat interfaces can be viewed as another step up the ladder of abstraction.
Gain knowledge in data manipulation and analysis: Familiarize yourself with data manipulation techniques using tools like SQL for database querying and data extraction. Also, learn how to analyze and visualizedata using libraries such as Pandas, NumPy, and Matplotlib.
Velocity It indicates the speed at which data is generated and processed, necessitating real-time analytics capabilities. Businesses need to analyse data as it streams in to make timely decisions. This diversity requires flexible data processing and storage solutions.
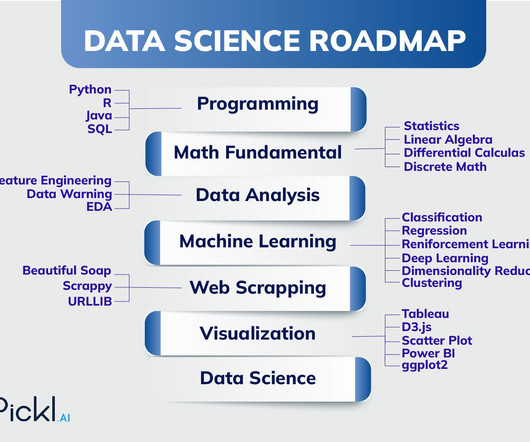
Key Takeaways: Data Science is a multidisciplinary field bridging statistics, mathematics, and computer science to extract insights from data. The roadmap to becoming a Data Scientist involves mastering programming, statistics, machine learning, datavisualization, and domain knowledge.
Making data-driven decisions: Data science empowers you to make informed decisions by analyzing and interpreting data. Addressing real-world problems: Data science enables you to tackle real-world challenges across diverse domains, such as healthcare, finance, marketing, and social sciences.
Let’s look at five benefits of an enterprise data catalog and how they make Alex’s workflow more efficient and her data-driven analysis more informed and relevant. A data catalog replaces tedious request and data-wrangling processes with a fast and seamless user experience to manage and access data products.
Drag and drop data fields into the “Rows,” “Columns,” “Values,” and “Filters” sections of the PivotTable Fields list to organize and analyze your data. Ensure headers are clear and data types are formatted correctly (currency for “Sales Amount”).
Data science methodologies and skills can be leveraged to design these experiments, analyze results, and iteratively improve prompt strategies. Using skills such as statistical analysis and datavisualization techniques, prompt engineers can assess the effectiveness of different prompts and understand patterns in the responses.
By providing a single, unified platform for data storage, management, and analysis, Snowflake connects organizations to leading software vendors specializing in analytics, machine learning, datavisualization, and more.
Monday’s sessions will cover a wide range of topics, from Generative AI and LLMs to MLOps and DataVisualization. Day 1: Monday, October 30th (Bootcamp, VIP, Platinum) Day 1 of ODSC West 2023 will feature our hands-on training sessions, workshops, and tutorials and will be open to Platinum, Bootcamp, and VIP pass holders.
This is the data at the source step (the first step in the right hand side) before any datawrangling. This is to improve the data loading performance. And, this is not only for SQL queries but also works for MongoDB queries and other datawrangling steps such as Filter, Create Calculation, etc. ?
Data often arrives from multiple sources in inconsistent forms, including duplicate entries from CRM systems, incomplete spreadsheet records, and mismatched naming conventions across databases. These issues slow analysis pipelines and demand time-consuming cleanup.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

























Let's personalize your content