This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This article was published as a part of the Data Science Blogathon. Introduction Jupyter Notebook is a web-based interactive computing platform that many data scientists use for datawrangling, datavisualization, and prototyping of their MachineLearning models.
Data Scientist Data scientists are responsible for designing and implementing data models, analyzing and interpreting data, and communicating insights to stakeholders. They require strong programming skills, knowledge of statistical analysis, and expertise in machinelearning.
Data science boot camps are intensive, short-term programs that teach students the skills they need to become data scientists. These programs typically cover topics such as datawrangling, statistical inference, machinelearning, and Python programming.
Recently, we posted the first article recapping our recent machinelearning survey. There, we talked about some of the results, such as what programming languages machinelearning practitioners use, what frameworks they use, and what areas of the field they’re interested in. As the chart shows, two major themes emerged.
At Springboard , we recently sat down with Michael Beaumier, a data scientist at Google, to discuss his transition into the field, what the interview process is like, the future of datawrangling, and the advice he has for aspiring data professionals. in physics and now you’re a data scientist.
7 types of statistical distributions with practical examples Statistical distributions help us understand a problem better by assigning a range of possible values to the variables, making them very useful in data science and machinelearning.
Machinelearning engineer vs data scientist: two distinct roles with overlapping expertise, each essential in unlocking the power of data-driven insights. As businesses strive to stay competitive and make data-driven decisions, the roles of machinelearning engineers and data scientists have gained prominence.
Join us as we delve into each of these top blogs, uncovering how they help us stay at the forefront of learning and innovation in these ever-changing industries. Here are 7 types of distributions with intuitive examples that often occur in real-life data.
In this article we will provide a brief introduction to Pandas, one of the most famous Python libraries for Data Science and Machinelearning. Introduction to Pandas – The fundamentals Pandas is a popular and powerful open-source data analysis and manipulation library for the Python programming language.
Just as a writer needs to know core skills like sentence structure, grammar, and so on, data scientists at all levels should know core data science skills like programming, computer science, algorithms, and so on. Scikit-learn also earns a top spot thanks to its success with predictive analytics and general machinelearning.
As a data analyst, you will learn several technical skills that data analysts need to be successful, including: Programming skills. Machinelearning knowledge. Datavisualization capability. Data Mining skills. Datawrangling ability.
I spent a day a week at Amazon, and they’ve been doing machinelearning going back to the early 90s to find patterns and also make logistics decisions. Whereas the kind of current machinelearning style thinking that federated learning, the ChatGPT do, is they don’t consider these issues.
Past courses have included An Introduction to DataWrangling with SQL Programming with Data: Python and Pandas Introduction to MachineLearning Introduction to Math for Data Science Introduction to DataVisualization During the conference itself, you’ll have your choice of any of ODSC East’s training sessions, workshops, and talks.
Overview: Data science vs data analytics Think of data science as the overarching umbrella that covers a wide range of tasks performed to find patterns in large datasets, structure data for use, train machinelearning models and develop artificial intelligence (AI) applications.
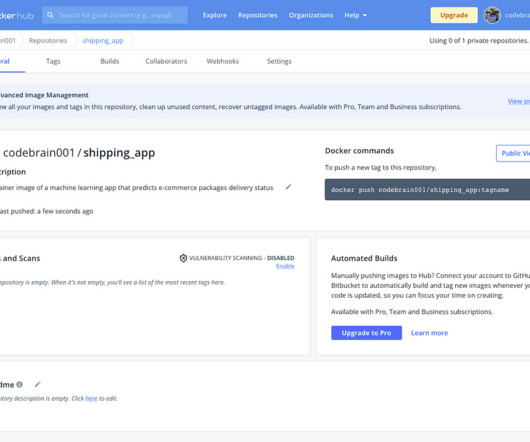
Photo by Ian Taylor on Unsplash This article will comprehensively create, deploy, and execute machinelearning application containers using the Docker tool. It will further explain the various containerization terms and the importance of this technology to the machinelearning workflow. Yes, they do, but partially.
Aspiring Data Scientists must equip themselves with a diverse skill set encompassing technical expertise, analytical prowess, and domain knowledge. Whether you’re venturing into machinelearning, predictive analytics, or datavisualization, honing the following top Data Science skills is essential for success.
We’re still hammering out the details and exact titles, but a tentative list of topics includes: An Introduction to DataWrangling with SQL Programming with Data: Python and Pandas Introduction to MachineLearning Introduction to Math for Data Science Introduction to DataVisualization Day 1: Tuesday, May 9th In-Person Day 1 ODSC East 2023 will feature (..)
Past courses have included An Introduction to DataWrangling with SQL Programming with Data: Python and Pandas Introduction to MachineLearning Introduction to Math for Data Science Introduction to DataVisualization During the conference itself, you’ll have your choice of any of ODSC West’s training sessions, workshops, and talks.
As you’ll see below, however, a growing number of data analytics platforms, skills, and frameworks have altered the traditional view of what a data analyst is. Data Presentation: Communication Skills, DataVisualization Any good data analyst can go beyond just number crunching.
Improving your data literacy not only involves hard skills, such as programming languages, but soft skills such as interpersonal communication, and stakeholder relations, as well as blended skills such as datavisualization. Both of these are important to predictive models in data science, machinelearning, and AI.
Making data-driven decisions: Data science empowers you to make informed decisions by analyzing and interpreting data. Cross-disciplinary collaboration: Data science often involves collaborating with experts from different domains, including computer science, mathematics, business, and domain-specific fields.
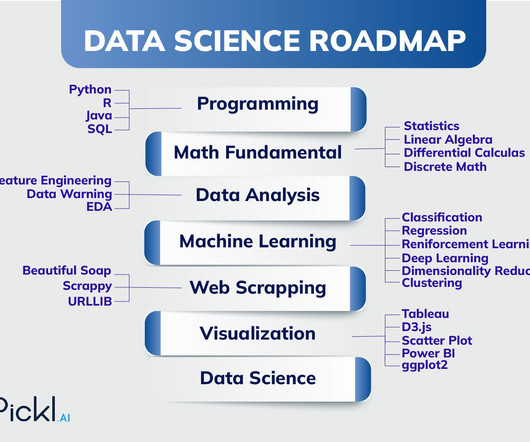
Key Takeaways: Data Science is a multidisciplinary field bridging statistics, mathematics, and computer science to extract insights from data. The roadmap to becoming a Data Scientist involves mastering programming, statistics, machinelearning, datavisualization, and domain knowledge.
Students should learn about datawrangling and the importance of data quality. Statistical Analysis Introducing statistical methods and techniques for analysing data, including hypothesis testing, regression analysis, and descriptive statistics. What are the Ethical Considerations in Big Data?
Enroll in data science courses or bootcamps: Participating in structured data science programs specifically designed for non-technical backgrounds can provide you with a comprehensive understanding of the field. Look for programs that cover topics such as machinelearning, datavisualization, and predictive modeling.
R is a popular programming language and environment widely used in the field of data science. It provides a comprehensive suite of tools, libraries, and packages specifically designed for statistical analysis, data manipulation, visualization, and machinelearning.
Descriptive Analytics Projects: These projects focus on summarizing historical data to gain insights into past trends and patterns. Examples include generating reports, dashboards, and datavisualizations to understand business performance, customer behavior, or operational efficiency.
They design intricate sequences of prompts, leveraging their knowledge of AI, machinelearning, and data science to guide powerful LLMs (Large Language Models) towards complex tasks. Data science methodologies and skills can be leveraged to design these experiments, analyze results, and iteratively improve prompt strategies.
Let’s look at five benefits of an enterprise data catalog and how they make Alex’s workflow more efficient and her data-driven analysis more informed and relevant. A data catalog replaces tedious request and data-wrangling processes with a fast and seamless user experience to manage and access data products.
Dataiku is an advanced analytics and machinelearning platform designed to democratize data science and foster collaboration across technical and non-technical teams. Snowflake excels in efficient data storage and governance, while Dataiku provides the tooling to operationalize advanced analytics and machinelearning models.
Monday’s sessions will cover a wide range of topics, from Generative AI and LLMs to MLOps and DataVisualization. This day will have a strong focus on intermediate content, as well as several sessions appropriate for data practitioners at all levels. Register now while tickets are 50% off. Prices go up Friday!
When you import data to Exploratory it used to save the data in a binary format called RDS on the local hard disk. This is the data at the source step (the first step in the right hand side) before any datawrangling. That’s all for the Exploratory v6.1
Mastering tools like LLMs, prompt engineering, and datawrangling is now essential for every modern developer. ODSC Highlights ODSC AI Bootcamp Primer Course: AI & Machine LearningModeling Tuesday, April 1st, 2:00 PMET This course is designed to introduce participants to the basics of AI and machinelearning.
Data often arrives from multiple sources in inconsistent forms, including duplicate entries from CRM systems, incomplete spreadsheet records, and mismatched naming conventions across databases. Data […] These issues slow analysis pipelines and demand time-consuming cleanup.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.







































Let's personalize your content