This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
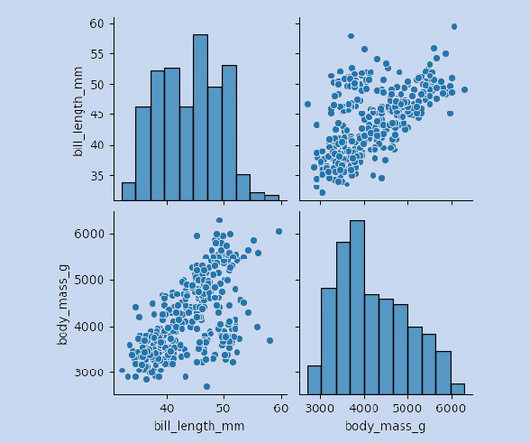
Introduction ExploratoryDataAnalysis is a method of evaluating or comprehending data in order to derive insights or key characteristics. EDA can be divided into two categories: graphical analysis and non-graphical analysis. EDA is a critical component of any data science or machinelearning process.
This article was published as a part of the Data Science Blogathon. The post The Clever Ingredient that decides the rise and the fall of your MachineLearning Model- ExploratoryDataAnalysis appeared first on Analytics Vidhya. Introduction Well! We all love cakes. If you take a deeper look.
Introduction ExploratoryDataAnalysis, or EDA, examines the data and identifies potential relationships between variables using numerical summaries and visualisations. We use summary statistics and graphical tools to get to know our data and understand what we may deduce from them during EDA. […].
This article was published as a part of the Data Science Blogathon. Introduction ExploratoryDataAnalysis helps in identifying any outlier data points, understanding the relationships between the various attributes and structure of the data, recognizing the important variables.
Overview In this article, we will be analyzing the flight fare prediction using MachineLearning dataset using essential exploratorydataanalysis techniques then will draw some predictions about the price of the flight based on some features such as what type of airline it […].
Introduction In the realm of data science, the initial step towards understanding and analyzing data involves a comprehensive exploratorydataanalysis (EDA). This process is pivotal for recognizing patterns, identifying anomalies, and establishing hypotheses.
ChatGPT can also use Wolfram Language to perform more complex tasks, such as simulating physical systems or training machinelearning models. Deploy machinelearning Models: You can use the plugin to train and deploy machinelearning models. Source: Datacamp 4.
Table of Contents Introduction Working with dataset Creating loss dataframe VisualizationsAnalysis from Heatmap Overall Analysis Conclusion Introduction In this article, I am going to perform ExploratoryDataAnalysis on the Sample Superstore dataset.
These skills include programming languages such as Python and R, statistics and probability, machinelearning, datavisualization, and data modeling. Data preparation is an essential step in the data science workflow, and data scientists should be familiar with various data preparation tools and best practices.
Photo by Adam Śmigielski on Unsplash It’s a great time to be a data scientist! What takes a lot of time to put together can be automated now, leaving much room to improve insights-creation and the machinelearning model design.
ArticleVideo Book Understand the ML best practice and project roadmap When a customer wants to implement ML(MachineLearning) for the identified business problem(s) after. The post Rapid-Fire EDA process using Python for ML Implementation appeared first on Analytics Vidhya.
t-SNE (t-distributed stochastic neighbor embedding) has become an essential tool in the realm of data analytics, standing out for its ability to unravel the complexities inherent in high-dimensional data.
Machinelearning engineer vs data scientist: two distinct roles with overlapping expertise, each essential in unlocking the power of data-driven insights. As businesses strive to stay competitive and make data-driven decisions, the roles of machinelearning engineers and data scientists have gained prominence.
Python machinelearning packages have emerged as the go-to choice for implementing and working with machinelearning algorithms. These libraries, with their rich functionalities and comprehensive toolsets, have become the backbone of data science and machinelearning practices.
7 types of statistical distributions with practical examples Statistical distributions help us understand a problem better by assigning a range of possible values to the variables, making them very useful in data science and machinelearning.
Building an End-to-End MachineLearning Project to Reduce Delays in Aggressive Cancer Care. Figure 3: The required python libraries The problem presented to us is a predictive analysis problem which means that we will be heavily involved in finding patterns and predictions rather than seeking recommendations.
Machinelearning (ML) technologies can drive decision-making in virtually all industries, from healthcare to human resources to finance and in myriad use cases, like computer vision , large language models (LLMs), speech recognition, self-driving cars and more. What is machinelearning?
The importance of EDA in the machinelearning world is well known to its users. Making visualizations is one of the finest ways for data scientists to explain dataanalysis to people outside the business. The EDA, the first chance for visualizations, will be the main topic of this article.
In this practical Kaggle notebook, I went through the basic techniques to work with time-series data, starting from data manipulation, analysis, and visualization to understand your data and prepare it for and then using statistical, machine, and deep learning techniques for forecasting and classification.
Join us as we delve into each of these top blogs, uncovering how they help us stay at the forefront of learning and innovation in these ever-changing industries. Here are 7 types of distributions with intuitive examples that often occur in real-life data.
There are many well-known libraries and platforms for dataanalysis such as Pandas and Tableau, in addition to analytical databases like ClickHouse, MariaDB, Apache Druid, Apache Pinot, Google BigQuery, Amazon RedShift, etc. Datavisualization can help here by visualizing your datasets.
1, Data is the new oil, but labeled data might be closer to it Even though we have been in the 3rd AI boom and machinelearning is showing concrete effectiveness at a commercial level, after the first two AI booms we are facing a problem: lack of labeled data or data themselves.
Basic knowledge of statistics is essential for data science. Statistics is broadly categorized into two types – Descriptive statistics – Descriptive statistics is describing the data. Visual graphs are the core of descriptive statistics. ExploratoryDataAnalysis. Basics of MachineLearning.
From Solo Notebooks to Collaborative Powerhouse: VS Code Extensions for Data Science and ML Teams Photo by Parabol | The Agile Meeting Toolbox on Unsplash In this article, we will explore the essential VS Code extensions that enhance productivity and collaboration for data scientists and machinelearning (ML) engineers.
The final point to which the data has to be eventually transferred is a destination. The destination is decided by the use case of the data pipeline. It can be used to run analytical tools and power datavisualization as well. Otherwise, it can also be moved to a storage centre like a data warehouse or lake.
Summary: DataAnalysis focuses on extracting meaningful insights from raw data using statistical and analytical methods, while datavisualization transforms these insights into visual formats like graphs and charts for better comprehension. Deep Dive: What is DataVisualization?
But make no mistake; data science is not a solitary endeavor; it’s a ballet of complexities and creativity. Data scientists waltz through intricate datasets, twirling with statistical tools and machinelearning techniques. Exploring the question, “What does a data scientist do?
Source: Author MachineLearningVisualization is the art and science of representing machinelearning models, data, and their relationships through graphical or interactive means. Visualization is crucial to any machinelearning project to understand complex data.
ChatGPT is essential in the domains of natural language processing, modeling, dataanalysis, data cleaning, and datavisualization. Nonetheless, Data Scientists need to be mindful of its limitations and ethical issues. It facilitates exploratoryDataAnalysis and provides quick insights.
Through each exercise, you’ll learn important data science skills as well as “best practices” for using pandas. By the end of the tutorial, you’ll be more fluent at using pandas to correctly and efficiently answer your own data science questions. Read the Data The first step is to get the data and load it to memory.
It involves steps like handling missing values, normalizing data, and managing categorical features, ultimately enhancing model performance and ensuring data quality. Introduction Data preprocessing is a critical step in the MachineLearning pipeline, transforming raw data into a clean and usable format.
A fair understanding of calculus, linear algebra, probability, and statistics is essential for tasks such as modeling, analysis, and inference. These languages are used for data manipulation, analysis, and building machinelearning models. Education: Bachelors in Computer Scene or a Quantitative field.
In the digital age, the abundance of textual information available on the internet, particularly on platforms like Twitter, blogs, and e-commerce websites, has led to an exponential growth in unstructured data. Text data is often unstructured, making it challenging to directly apply machinelearning algorithms for sentiment analysis.
Or even if we have a pretty good understanding of the problem, there is not enough data to run a successful project and deliver impact back to the business. Image recognition is one of the most relevant areas of machinelearning. Deep learning makes the process efficient. In 2020, our team launched DataRobot Visual AI.
Principal component analysis (PCA) is a popular unsupervised MachineLearning technique for reducing the dimensionality of large datasets. By reducing the number of variables, PCA helps to simplify data and make it easier to analyze. Managing and analyzing such high-dimensional data can be challenging.
These models, which are based on artificial intelligence and machinelearning algorithms, are designed to process vast amounts of natural language data and generate new content based on that data. You should be comfortable working with data structures, algorithms, and libraries like NumPy, Pandas, and TensorFlow.
ExploratoryDataAnalysis Next, we will create visualizations to uncover some of the most important information in our data. At the same time, the number of rows decreased slightly to 160,454, a result of duplicate removal. Therefore, below is the monthly average price of HDB flats from January 2017 to August 2023.
Data science equips you with the tools and techniques to manage big data, perform exploratorydataanalysis, and extract meaningful information from complex datasets. Making data-driven decisions: Data science empowers you to make informed decisions by analyzing and interpreting data.
A Introduction to HiPlot for DataAnalysis and MachineLearning Image by Author with @MidJourney Introduction Datavisualization is an essential tool for understanding complex datasets. Overall, this article aims to provide a comprehensive guide to using HiPlot for datavisualization and analysis.
Proficient in programming languages like Python or R, data manipulation libraries like Pandas, and machinelearning frameworks like TensorFlow and Scikit-learn, data scientists uncover patterns and trends through statistical analysis and datavisualization.
Build a Stocks Price Prediction App powered by Snowflake, AWS, Python and Streamlit — Part 2 of 3 A comprehensive guide to develop machinelearning applications from start to finish. Introduction Welcome Back, Let's continue with our Data Science journey to create the Stock Price Prediction web application.
You will collect and clean data from multiple sources, ensuring it is suitable for analysis. You will perform ExploratoryDataAnalysis to uncover patterns and insights hidden within the data. Data Integration Data integration combines data from different sources into a single dataset.
Fantasy Football is a popular pastime for a large amount of the world, we gathered data around the past 6 seasons of player performance data to see what our community of data scientists could create. This report took the data set provided in the challenge, as well as external data feeds and alternative sources.
Snowflake is a cloud data platform that provides data solutions for data warehousing to data science. Snowflake is an AWS Partner with multiple AWS accreditations, including AWS competencies in machinelearning (ML), retail, and data and analytics. On the Import data page, choose Create connection.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content