This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Data engineering tools offer a range of features and functionalities, including data integration, data transformation, data quality management, workflow orchestration, and datavisualization. Essential data engineering tools for 2023 Top 10 data engineering tools to watch out for in 2023 1.
DataVisualization Think of datavisualization as creating a visual map of the data. Big Data Technologies For large datasets, you need special tools to handle them efficiently. Hadoop and Spark: These are like powerful computers that can process huge amounts of data quickly.
Their role is crucial in understanding the underlying data structures and how to leverage them for insights. Key Skills Proficiency in SQL is essential, along with experience in datavisualization tools such as Tableau or Power BI. Programming Questions Data science roles typically require knowledge of Python, SQL, R, or Hadoop.
DataVisualization Think of datavisualization as creating a visual map of the data. Big Data Technologies For large datasets, you need special tools to handle them efficiently. Hadoop and Spark: These are like powerful computers that can process huge amounts of data quickly.
Big data processing With the increasing volume of data, big data technologies have become indispensable for Applied Data Science. Technologies like Hadoop and Spark enable the processing and analysis of massive datasets in a distributed and parallel manner.
They’re looking to hire experienced data analysts, data scientists and data engineers. With big data careers in high demand, the required skillsets will include: Apache Hadoop. Software businesses are using Hadoop clusters on a more regular basis now. NoSQL and SQL. Machine Learning. Other coursework.
Data Storage and Management Once data have been collected from the sources, they must be secured and made accessible. The responsibilities of this phase can be handled with traditional databases (MySQL, PostgreSQL), cloud storage (AWS S3, Google Cloud Storage), and big data frameworks (Hadoop, Apache Spark).
Even if you don’t have a degree, you might still be pondering, “How to become a data scientist?” ” Datavisualization and communication It’s not enough to uncover insights from data; a data scientist must also communicate these insights effectively. Works with smaller data sets.
Data science bootcamps are intensive short-term educational programs designed to equip individuals with the skills needed to enter or advance in the field of data science. They cover a wide range of topics, ranging from Python, R, and statistics to machine learning and datavisualization.
Big data analytics Big data analytics involves processing vast amounts of structured and unstructured data, extracting key insights that drive business decisions. Machine learning Integrating machine learning enhances the accuracy of predictive analytics applications, continuously learning from new data inputs.
Navigate through 6 Popular Python Libraries for Data Science R R is another important language, particularly valued in statistics and data analysis, making it useful for AI applications that require intensive data processing. C++ C++ is essential for AI engineering due to its efficiency and control over system resources.
Introduction Not a single day passes without us getting to hear the word “data.” This is precisely what happens in data analytics. People equipped with the […] The post 10 Best Data Analytics Projects appeared first on Analytics Vidhya. It is almost as if our lives revolve around it. Don’t they?
Architecturally the introduction of Hadoop, a file system designed to store massive amounts of data, radically affected the cost model of data. Organizationally the innovation of self-service analytics, pioneered by Tableau and Qlik, fundamentally transformed the user model for data analysis. Disruptive Trend #1: Hadoop.
Programming languages like Python and R are commonly used for data manipulation, visualization, and statistical modeling. Machine learning algorithms play a central role in building predictive models and enabling systems to learn from data. Data Scientists rely on technical proficiency.
Among the skills necessary to become a data scientist include an analytical mindset, mathematics, datavisualization, and business knowledge, just to name a few. In addition to having the skills, you’ll need to then learn how to use the modern data science tools.
They create data pipelines, ETL processes, and databases to facilitate smooth data flow and storage. With expertise in programming languages like Python , Java , SQL, and knowledge of big data technologies like Hadoop and Spark, data engineers optimize pipelines for data scientists and analysts to access valuable insights efficiently.
And you should have experience working with big data platforms such as Hadoop or Apache Spark. Additionally, data science requires experience in SQL database coding and an ability to work with unstructured data of various types, such as video, audio, pictures and text.
Big data has been billed as being the future of business for quite some time. Analysts have found that the market for big data jobs increased 23% between 2014 and 2019. The market for Hadoop jobs increased 58% in that timeframe. The impact of big data is felt across all sectors of the economy. However, the future is now.
Big Data Technologies and Tools A comprehensive syllabus should introduce students to the key technologies and tools used in Big Data analytics. Some of the most notable technologies include: Hadoop An open-source framework that allows for distributed storage and processing of large datasets across clusters of computers.
A good course to upskill in this area is — Machine Learning Specialization DataVisualization The ability to effectively communicate insights through datavisualization is important. Additionally, knowledge of model evaluation, hyperparameter tuning, and model selection is valuable.
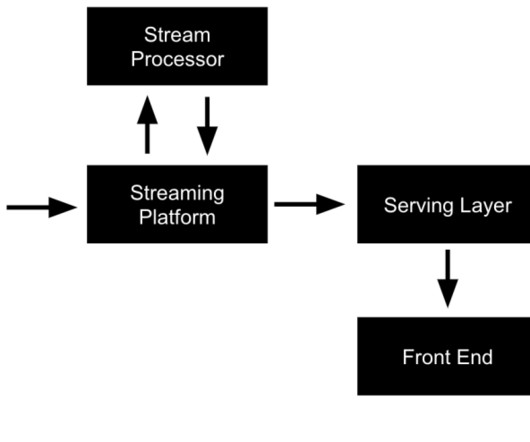
Data Processing (Preparation): Ingested data undergoes processing to ensure it’s suitable for storage and analysis. Batch Processing: For large datasets, frameworks like Apache Hadoop MapReduce or Apache Spark are used. Stream Processing: Real-time data is processed using tools like Apache Kafka or Apache Flink.
It combines techniques from mathematics, statistics, computer science, and domain expertise to analyze data, draw conclusions, and forecast future trends. Data scientists use a combination of programming languages (Python, R, etc.), Acquiring and maintaining this breadth of knowledge can be challenging and time-consuming.
It is popular for its powerful datavisualization and analysis capabilities. Hence, Data Scientists rely on R to perform complex statistical operations. With a wide array of packages like ggplot2 and dplyr, R allows for sophisticated datavisualization and efficient data manipulation. Wrapping it up !!!
They employ statistical methods and machine learning techniques to interpret data. Key Skills Expertise in statistical analysis and datavisualization tools. Data Analyst Data Analysts gather and interpret data to help organisations make informed decisions. Experience with big data technologies (e.g.,
Knowledge of Core Data Engineering Concepts Ensure one possess a strong foundation in core data engineering concepts, which include data structures, algorithms, database management systems, data modeling , data warehousing , ETL (Extract, Transform, Load) processes, and distributed computing frameworks (e.g.,
Thus, it focuses on providing all the fundamental concepts of Data Science and light concepts of Machine Learning, Artificial Intelligence, programming languages and others. Usually, a Data Science course comprises topics on statistical analysis, datavisualization, data mining and data preprocessing.
Read More: Unlocking the Power of Data Analytics in the Finance Industry Technologies and Tools Used Uber employs a robust technological infrastructure to support its Data Analytics initiatives.By What Technologies Does Uber Use for Data Processing?
Responsibilities of a Data Analyst Data analysts, on the other hand, help businesses and organizations make data-driven decisions through their analytical skills. Their job is mainly to collect, process, analyze, and create detailed reports on data to meet business needs.
The fields have evolved such that to work as a data analyst who views, manages and accesses data, you need to know Structured Query Language (SQL) as well as math, statistics, datavisualization (to present the results to stakeholders) and data mining.
It can ingest from batch data sources (such as Hadoop HDFS, Amazon S3, and Google Cloud Storage) as well as stream data sources (such as Apache Kafka and Redpanda). Pinot stores data in tables, each of which must first define a schema.
This layer is critical as it transforms raw data into actionable insights that drive business decisions. DataVisualizationDatavisualization tools present analyzed data in an easily understandable format. Prescriptive Analytics : Offers recommendations for actions based on predictive models.
Alation helps connects to any source Alation helps connect to virtually any data source through pre-built connectors. Alation crawls and indexes data assets stored across disparate repositories, including cloud data lakes, databases, Hadoop files, and datavisualization tools.
Significantly, Data Science experts have a strong foundation in mathematics, statistics, and computer science. Furthermore, they must be highly efficient in programming languages like Python or R and have datavisualization tools and database expertise. Who is a Data Analyst?
Tableau/Power BI: Visualization tools for creating interactive and informative datavisualizations. Hadoop/Spark: Frameworks for distributed storage and processing of big data. Cloud Platforms (AWS, Azure, Google Cloud): Infrastructure for scalable and cost-effective data storage and analysis.
They employ advanced statistical modeling techniques, machine learning algorithms, and datavisualization tools to derive meaningful insights. Data Analyst Data analysts focus on collecting, cleaning, and transforming data to discover patterns and trends.
Tools like Apache Airflow are widely used for scheduling and monitoring workflows, while Apache Spark dominates big data pipelines due to its speed and scalability. Hadoop, though less common in new projects, is still crucial for batch processing and distributed storage in large-scale environments.
Here is the tabular representation of the same: Technical Skills Non-technical Skills Programming Languages: Python, SQL, R Good written and oral communication Data Analysis: Pandas, Matplotlib, Numpy, Seaborn Ability to work in a team ML Algorithms: Regression Classification, Decision Trees, Regression Analysis Problem-solving capability Big Data: (..)
Packages like stats, car, and survival are commonly used for statistical modeling and analysis. · DataVisualization : R offers several libraries, including ggplot2, plotly, and lattice, that allow for the creation of high-quality visualizations.
Popular libraries for Data Science in Python include NumPy (numerical computing), pandas (data manipulation and analysis), and scikit-learn (machine learning algorithms). R: A powerful language specifically designed for statistical computing and datavisualization. Course Focus Data Science is a vast field.
Descriptive Analytics Projects: These projects focus on summarizing historical data to gain insights into past trends and patterns. Examples include generating reports, dashboards, and datavisualizations to understand business performance, customer behavior, or operational efficiency.
As models become more complex and the needs of the organization evolve and demand greater predictive abilities, you’ll also find that machine learning engineers use specialized tools such as Hadoop and Apache Spark for large-scale data processing and distributed computing.
Gain Experience with Big Data Technologies With the rise of Big Data, familiarity with technologies like Hadoop and Spark is essential. Understanding real-time data processing frameworks, such as Apache Kafka, will also enhance your ability to handle dynamic analytics.
These integrations allow users to easily track their machine learning experiments and visualize their results within the Comet platform, without having to write additional code. Comet also integrates with popular data storage and processing tools like Amazon S3, Google Cloud Storage, and Hadoop.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content