This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Introduction Data from different sources are brought to a single location and then converted into a format that the datawarehouse can process and store. For example, a company stores data about its customers, products, employees, salaries, sales, and invoices. A boss may […].
Wouldn’t the process be much easier if the raw data were more organized and clean? Here’s when Data […]. The post What are Schemas in DataWarehouse Modeling? It’s possible, of course, but it can be tiresome and not be as accurate as it should be. appeared first on Analytics Vidhya.
Introduction on DataWarehouses During one of the technical webinars, it was highlighted where the transactional database was rendered no-operational bringing day to day operations to a standstill. The post Understanding Key Concepts on DataWarehouses appeared first on Analytics Vidhya.
Introduction The STAR schema is an efficient database design used in data warehousing and business intelligence. It organizes data into a central fact table linked to surrounding dimension tables. A major advantage of the STAR […] The post How to Optimize DataWarehouse with STAR Schema?
DHW, short for DataWarehouse, was presented first by great IBM researchers Barry Devlin and Paul […]. The post DataWarehouse for the Beginners! IBM is one name that easily enters the picture whenever long history in computer science is involved. appeared first on Analytics Vidhya.
Data collection is critical for businesses to make informed decisions, understand customers’ […]. The post Data Lake or DataWarehouse- Which is Better? We can use it to represent facts, figures, and other information that we can use to make decisions. appeared first on Analytics Vidhya.
Introduction Amazon’s Redshift Database is a cloud-based large data warehousing solution. Companies may store petabytes of data in easy-to-access “clusters” that can be searched in parallel using the platform’s storage system. The datasets range in size from a few 100 megabytes to a petabyte. […].
CEO and co-founder of Simon Data, believes that when companies try to pull together all the data streams in a warehouse, they can run into several challenges that make it hard to get a comprehensive picture and create effective personalization. In this contributed article, Jason Davis, Ph.D.
Introduction Have you ever wondered how big IT giants store and process huge amounts of data? Different organizations make use of different databases like an oracle database storing transactional data, MySQL for storing product data, and many others for different tasks. storing the data […].
This is where data warehousing is a critical component of any business, allowing companies to store and manage vast amounts of data. It provides the necessary foundation for businesses to […] The post Understanding the Basics of DataWarehouse and its Structure appeared first on Analytics Vidhya.
Now, businesses are looking for different types of data storage to store and manage their data effectively. Organizations can collect millions of data, but if they’re lacking in storing that data, those efforts […] The post A Comprehensive Guide to Data Lake vs. DataWarehouse appeared first on Analytics Vidhya.
Introduction This article will introduce the concept of data modeling, a crucial process that outlines how data is stored, organized, and accessed within a database or data system. It involves converting real-world business needs into a logical and structured format that can be realized in a database or datawarehouse.
In the contemporary age of Big Data, DataWarehouse Systems and Data Science Analytics Infrastructures have become an essential component for organizations to store, analyze, and make data-driven decisions. So why using IaC for Cloud Data Infrastructures?
In this contributed article, Chris Tweten, Marketing Representative of AirOps, discusses how datawarehouse best practices give digital businesses a solid foundation for building a streamlined data management system. Here’s what you need to know.
Firebolt announced the next-generation Cloud DataWarehouse (CDW) that delivers low latency analytics with drastic efficiency gains. Built across five years of relentless development, it reflects continuous feedback from users and real-world use cases.
When it comes to data, there are two main types: data lakes and datawarehouses. What is a data lake? An enormous amount of raw data is stored in its original format in a data lake until it is required for analytics applications. Some NoSQL databases are also utilized as platforms for data lakes.
INTRODUCTION Hive is one of the most popular datawarehouse systems in the industry for data storage, and to store this data Hive uses tables. Tables in the hive are analogous to tables in a relational database management system. By default, it is /user/hive/warehouse directory. For instance, […].
Introduction Data is the new oil in this century. The database is the major element of a data science project. To generate actionable insights, the database must be centralized and organized efficiently. So, we are […] The post How to Normalize Relational Databases With SQL Code?
Built into Data Wrangler, is the Chat for data prep option, which allows you to use natural language to explore, visualize, and transform your data in a conversational interface. Amazon QuickSight powers data-driven organizations with unified (BI) at hyperscale. A provisioned or serverless Amazon Redshift datawarehouse.
While customers can perform some basic analysis within their operational or transactional databases, many still need to build custom data pipelines that use batch or streaming jobs to extract, transform, and load (ETL) data into their datawarehouse for more comprehensive analysis. or a later version) database.
It powers business decisions, drives AI models, and keeps databases running efficiently. But heres the problem: raw data is often messy. Without proper organization, databases become bloated, slow, and unreliable. Thats where data normalization comes in. Thats where data normalization comes in.
Introduction on ETL Pipeline ETL pipelines are a set of processes used to transfer data from one or more sources to a database, like a datawarehouse. Extraction, transformation, and loading are three interdependent procedures used to pull data from one database and place […].
This article was published as a part of the Data Science Blogathon. Introduction We are all pretty much familiar with the common modern cloud datawarehouse model, which essentially provides a platform comprising a data lake (based on a cloud storage account such as Azure Data Lake Storage Gen2) AND a datawarehouse compute engine […].
It serves as the primary means for communicating with relational databases, where most organizations store crucial data. SQL plays a significant role including analyzing complex data, creating data pipelines, and efficiently managing datawarehouses.
This article was published as a part of the Data Science Blogathon What is the need for Hive? The official description of Hive is- ‘Apache Hive datawarehouse software project built on top of Apache Hadoop for providing data query and analysis.
Summary : This guide provides an in-depth look at the top datawarehouse interview questions and answers essential for candidates in 2025. Covering key concepts, techniques, and best practices, it equips you with the knowledge needed to excel in interviews and demonstrates your expertise in data warehousing.
This article was published as a part of the Data Science Blogathon. Introduction Organizations with a separate transactional database and datawarehouse typically have many data engineering activities. For example, they extract, transform and load data from various sources into their datawarehouse.
This article was published as a part of the Data Science Blogathon Image 1 What is data mining? Data mining is the process of finding interesting patterns and knowledge from large amounts of data. This analysis […].
Businesses have adopted Snowflake as migration from on-premise enterprise datawarehouses (such as Teradata) or a more flexibly scalable and easier-to-manage alternative to […]. The post Data Warehousing with Snowflake and Other Alternatives appeared first on Analytics Vidhya.
The market for datawarehouses is booming. While there is a lot of discussion about the merits of datawarehouses, not enough discussion centers around data lakes. We talked about enterprise datawarehouses in the past, so let’s contrast them with data lakes. DataWarehouse.
Enter AnalyticsCreator AnalyticsCreator, a powerful tool for data management, brings a new level of efficiency and reliability to the CI/CD process. It offers full BI-Stack Automation, from source to datawarehouse through to frontend. It supports a holistic data model, allowing for rapid prototyping of various models.
This article was published as a part of the Data Science Blogathon. Introduction Apache SQOOP is a tool designed to aid in the large-scale export and import of data into HDFS from structured data repositories. Relational databases, enterprise datawarehouses, and NoSQL systems are all examples of data storage.
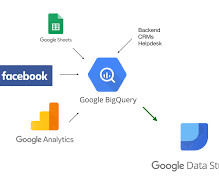
Introduction Google’s BigQuery is a powerful cloud-based datawarehouse that provides fast, flexible, and cost-effective data storage and analysis capabilities. BigQuery was created to analyse data […] The post Building a Machine Learning Model in BigQuery appeared first on Analytics Vidhya.
In the first part of this series, we explored how harmonizing relational database management systems (RDBMS) with datawarehouses (DWH) can drive scalability, efficiency, and advanced analytics.
Want to create a robust datawarehouse architecture for your business? The sheer volume of data that companies are now gathering is incredible, and understanding how best to store and use this information to extract top performance can be incredibly overwhelming.
This article was published as a part of the Data Science Blogathon. Source: [link] Introduction If you are familiar with databases, or datawarehouses, you have probably heard the term “ETL.” As the amount of data at organizations grow, making use of that data in analytics to derive business insights grows as well.
Introduction Google Big Query is a secure, accessible, fully-manage, pay-as-you-go, server-less, multi-cloud datawarehouse Platform as a Service (PaaS) service provided by Google Cloud Platform that helps to generate useful insights from big data that will help business stakeholders in effective decision-making.
In this contributed article, Sida Shen, product marketing manager, CelerData, discusses how data lakehouse architectures promise the combined strengths of data lakes and datawarehouses, but one question arises: why do we still find the need to transfer data from these lakehouses to proprietary datawarehouses?
The goal of this post is to understand how data integrity best practices have been embraced time and time again, no matter the technology underpinning. In the beginning, there was a datawarehouse The datawarehouse (DW) was an approach to data architecture and structured data management that really hit its stride in the early 1990s.
SQL (Structured Query Language) is an important tool for data scientists. It is a programming language used to manipulate data stored in relational databases. Mastering SQL concepts allows a data scientist to quickly analyze large amounts of data and make decisions based on their findings.
The main solutions on the market are decentralized file storage networks (DSFN) like Filecoin and Arweave, and decentralized datawarehouses like Space and Time (SxT). Built to seamlessly integrate with existing enterprise systems, the datawarehouse lets businesses tap into blockchain data while publishing query results back on-chain.
What is an online transaction processing database (OLTP)? OLTP is the backbone of modern data processing, a critical component in managing large volumes of transactions quickly and efficiently. This approach allows businesses to efficiently manage large amounts of data and leverage it to their advantage in a highly competitive market.
This article was published as a part of the Data Science Blogathon. Introduction Hive is a popular datawarehouse built on top of Hadoop that is used by companies like Walmart, Tiktok, and AT&T. It is an important technology for data engineers to learn and master.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content